# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
本文第一作者为刘禹宏,上海交通大学人工智能专业本科四年级学生,相关研究工作于上海人工智能实验室科研实习期间完成。通讯作者为王佳琦、臧宇航,在该研究工作完成期间,均担任上海人工智能实验室研究员。
近年来,视觉大语言模型(LVLM)的空间智能受到了广泛关注,高水平的空间理解能力对于自动驾驶、具身智能等领域发展有着重要意义。然而,当前的LVLM在空间理解方面仍显著落后于人类。
近期,来自上海人工智能实验室、上海交通大学、香港中文大学等机构的研究团队提出了名为Spatial-SSRL (Self-Supervised Reinforcement Learning) 的全新自监督RL范式,无需任何外界标注,旨在提升LVLM空间理解能力。实验证明,该范式在 Qwen2.5-VL(3B&7B) 和最新的 Qwen3-VL(4B) 架构下都成功地提升了模型的空间理解能力,同时保留了原有的通用视觉能力。
目前Spatial-SSRL的Huggingface model&dataset总下载量已经突破1k,欢迎大家下载和使用!

https://arxiv.org/pdf/2510.27606
https://github.com/InternLM/Spatial-SSRL
https://huggingface.co/internlm/Spatial-SSRL-7B
https://huggingface.co/internlm/Spatial-SSRL-Qwen3VL-4B
https://huggingface.co/datasets/internlm/Spatial-SSRL-81k

图1. Spatial-SSRL效果示例与性能评测
传统的提升LVLM空间理解的方法大多基于监督微调 (SFT) 范式。该方法的训练数据往往包含带思维链(CoT)的答案,需要大量人工标注或闭源模型标注,成本较高,可扩展性低。此外,SFT优化后的模型还容易出现“死记硬背”,泛化性弱的性能局限。
基于可验证奖励的强化学习(RLVR)成为了新的主流训练范式。如图2(a),现有利用RLVR提升空间理解的方法常聚焦于搭建复杂的流程构建训练数据,其中往往依赖已标注好的公开数据集,以及较多外部工具,如专家模型、模拟器等,框架较为繁琐,且使用的外部工具也会引入不小的计算开销和时间成本。
RGB和RGB-D图内部本身包含大量于2D和3D空间信息,可以天然地作为视觉监督信号。因此,研究者们提出自监督RL的新范式,实现低成本高效增强LVLM空间理解能力。
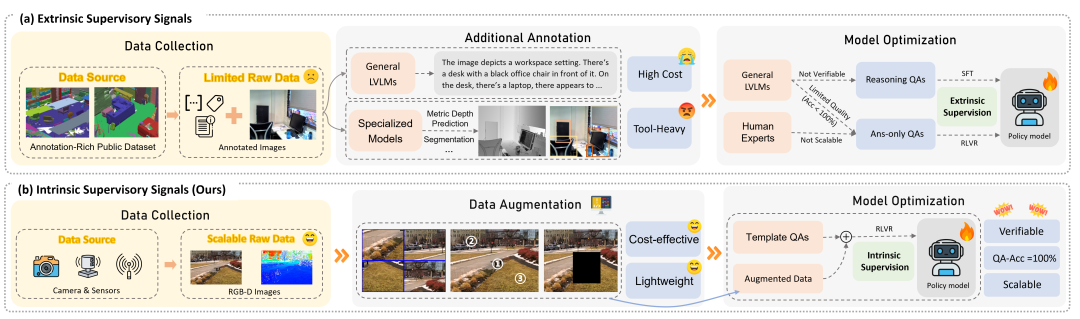
图2. Spatial-SSRL与相关工作框架对比
Spatial-SSRL基于低成本、易采集的RGB、RGB-D图像,构建了五种自监督任务:打乱图块重排序、翻转图块识别、裁剪图块复原、区域深度排序、3D相对位置预测。这五个任务将视觉线索作为监督信号,分别聚焦于感知和理解2D布局、局部物体朝向、3D深度与位置关系等空间信息,互为补充,从多方位全面提升空间理解能力。

图3. Spatial-SSRL方法总览
相较于之前的方法,Spatial-SSRL具备以下核心亮点(如图2(b)):
随后,研究者们基于上述流程构建了数据集Spatial-SSRL-81k,并在此基础上使用GRPO方法训练,引导模型输出推理过程,提升空间理解能力。
为充分验证Spatial-SSRL范式的效果,研究团队选取了Qwen2.5-VL (3B&7B)和Qwen3-VL(4B)两个架构的三个不同参数量的基模型,利用GRPO进行训练,并对训练后的模型进行了空间理解、通用视觉能力等全方位评测,与相应的基模型实施了对比分析。
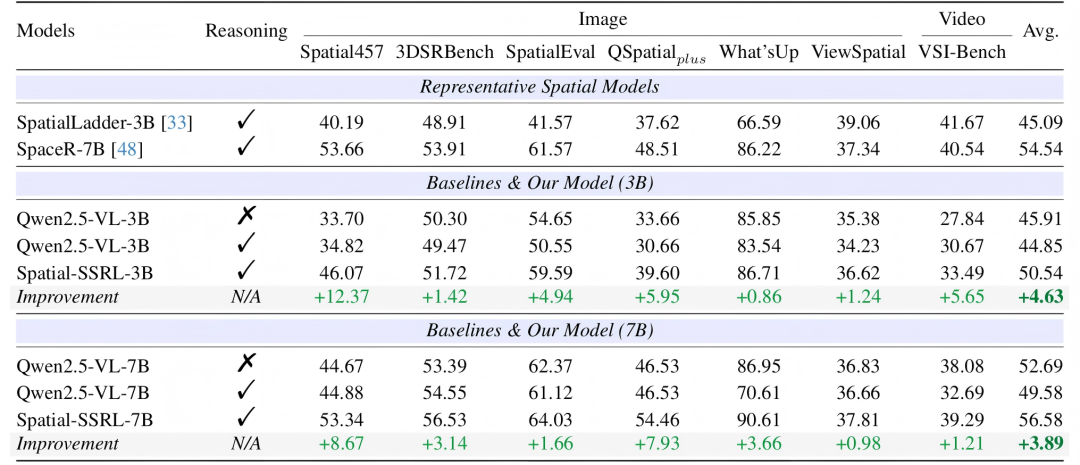
图4. 训练前后模型在空间理解基准的性能对比(Qwen2.5-VL架构)
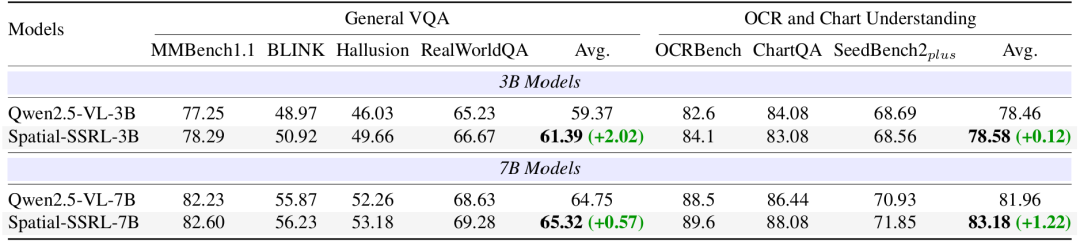
图5. 训练前后模型在通用视觉基准的性能对比(Qwen2.5-VL架构)
从图4和图6可以看出,在Qwen2.5-VL和Qwen3-VL两种架构的三个不同参数量下,Spatial-SSRL都对LVLM空间理解能力带来了显著提升,且在所有的7个空间基准(包含图片和视频两类模态)上均表现有所进步。其中,7B的平均水平超越基线模型3.89%,而3B更是达到了4.63%。这展现出了Spatial-SSRL自监督RL范式的有效性和鲁棒性。
另一个很多人可能关心的问题是:空间理解能力虽然提升了,但模型本来的通用能力是否会下降。研究人员进一步评测了训练前后模型的通用视觉能力,在通用视觉问答和OCR与图表理解两大类基准上进行测试,发现模型的通用视觉能力基本保持稳定,平均表现甚至略有提升。这证明了Spatial-SSRL不会导致模型“遗忘”其原有的技能。
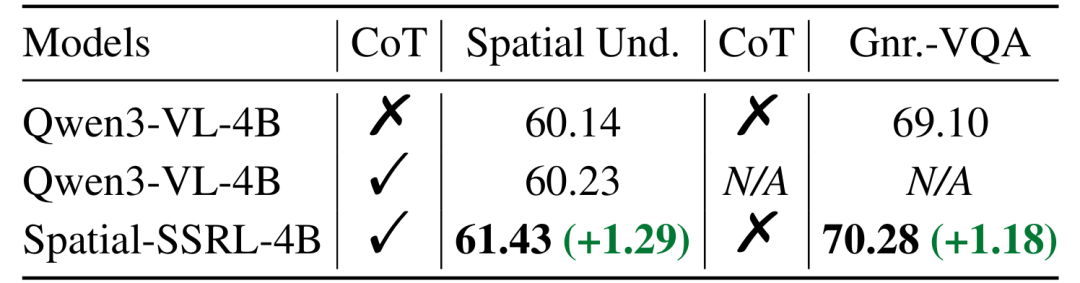
图6. 训练前后模型的性能对比(Qwen3-VL架构)
Spatial-SSRL是一种直接从内在图像结构中生成可验证监督的自监督强化学习范式。其核心优势在于可以从常见易大规模低成本采集的 RGB 与 RGB-D 图像直接提取丰富的空间理解自监督信号,且这些信号可通过可验证奖励自然地与强化学习兼容。
在七个空间基准上的全面实验表明,Spatial-SSRL 带来显著空间理解提升,且复杂空间推理基准上增益尤为显著。关键的是,Spatial-SSRL 不仅增强空间能力,还能同时保持原有的细粒度感知和通用视觉理解能力。这说明了简单的内在视觉监督信号可以有效实现大规模RLVR,对于未来提升LVLM空间智能提供了新的思路和方法!
目前该工作代码、模型和数据集均已开源,希望大家多多下载体验!
文章来自于微信公众号 “机器之心”,作者 “机器之心”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
