深度|ChatGPT搜索还不是OpenAI的“谷歌大杀器”?
深度|ChatGPT搜索还不是OpenAI的“谷歌大杀器”?OpenAI 发布了备受期待的搜索产品,ChatGPT 搜索,以挑战谷歌。业界已经为这一时刻准备了几个月,这促使谷歌在今年早些时候将 AI 生成的答案注入其核心产品,并在此过程中产生了一些尴尬的幻觉。这一失误让许多人相信 OpenAI 的搜索引擎将真正成为“谷歌大杀器”。
来自主题: AI资讯
6744 点击 2024-11-05 15:26
 搜索
搜索
OpenAI 发布了备受期待的搜索产品,ChatGPT 搜索,以挑战谷歌。业界已经为这一时刻准备了几个月,这促使谷歌在今年早些时候将 AI 生成的答案注入其核心产品,并在此过程中产生了一些尴尬的幻觉。这一失误让许多人相信 OpenAI 的搜索引擎将真正成为“谷歌大杀器”。

在人工智能领域,大型预训练模型(如 GPT 和 LLaVA)的 “幻觉” 现象常被视为一个难以克服的挑战,尤其是在执行精确任务如图像分割时。

如今,人们选择餐厅,多半会打开app搜索一番,再看看排名。然而美国奥斯汀的一家餐厅Ethos的存在证实这种选择机制多么不可靠。Ethos在社交媒体instagram宣称是当地排名第一的餐厅,拥有7万余粉丝。
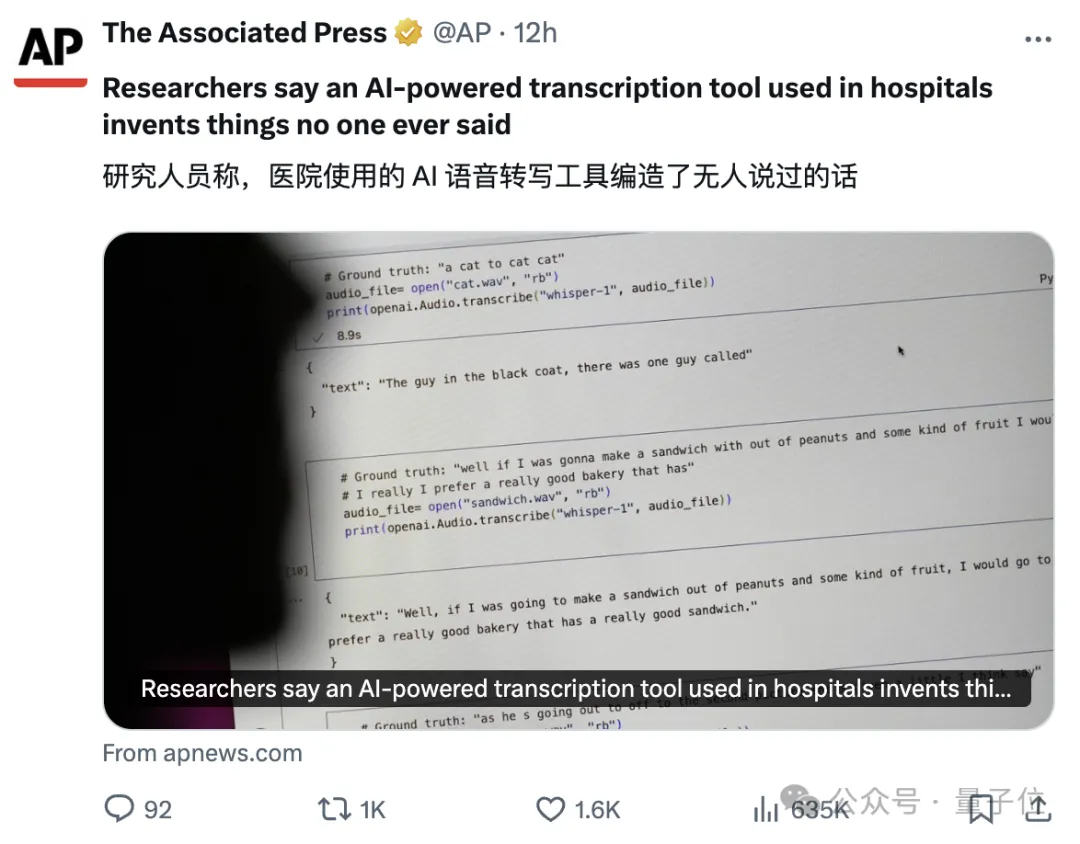
OpenAI的AI语音转写工具,那个号称近乎“人类水平”的Whisper,被曝幻觉严重—— 100多小时转录,被工程师发现约一半都在瞎扯。 更严重的是,美联社还爆料有医疗机构利用Whisper来转录医生与患者的会诊,瞬间引发大量网友关注。

哈佛大学研究了大型语言模型在回答晦涩难懂和有争议问题时产生「幻觉」的原因,发现模型输出的准确性高度依赖于训练数据的质量和数量。研究结果指出,大模型在处理有广泛共识的问题时表现较好,但在面对争议性或信息不足的主题时则容易产生误导性的回答。

现有的大模型主要依赖固定的参数和数据来存储知识,一旦训练完成,修改和更新特定知识的代价极大,常常因知识谬误导致模型输出不准确或引发「幻觉」现象。因此,如何对大模型的知识记忆进行精确控制和编辑,成为当前研究的前沿热点。
国庆节过后,人工智能领域似乎多了几分冷色调。不知道是因为大语言模型(Large Language Model,LLM)的幻觉,还是因为寒露时节的到来。

近期微软的高层人员调动以及新工具的推出,可能暗示着其AI战略的转向。

在AI技术广泛应用的企业场景中,提高检索准确度和效率已成为关键挑战。特别是面对生成式AI中的“幻觉”问题,企业急需有效解决方案。

准确的统计数据、时效性强的信息,一直是大语言模型产生幻觉的重灾区。谷歌在近日推出了自己筹划已久的大型数据库Data Commons,以及在此基础上诞生的大模型DataGemma。