
训练加速1.8倍,推理开销降78%!精准筛选题目高效加速RL训练丨清华KDD
训练加速1.8倍,推理开销降78%!精准筛选题目高效加速RL训练丨清华KDD以DeepSeek R1为代表的一系列基于强化学习(RLVR)微调的工作,显著提升了大语言模型的推理能力。但在这股浪潮背后,强化微调的代价却高得惊人。
来自主题: AI技术研报
10183 点击 2026-02-10 14:19
 搜索
搜索
以DeepSeek R1为代表的一系列基于强化学习(RLVR)微调的工作,显著提升了大语言模型的推理能力。但在这股浪潮背后,强化微调的代价却高得惊人。
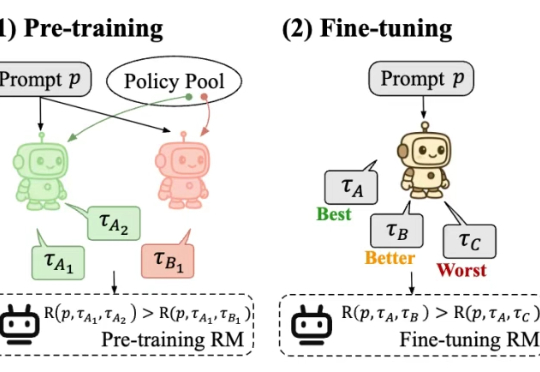
最近,一款全新的奖励模型「POLAR」横空出世。它开创性地采用了对比学习范式,通过衡量模型回复与参考答案的「距离」来给出精细分数。不仅摆脱了对海量人工标注的依赖,更展现出强大的Scaling潜力,让小模型也能超越规模大数十倍的对手。
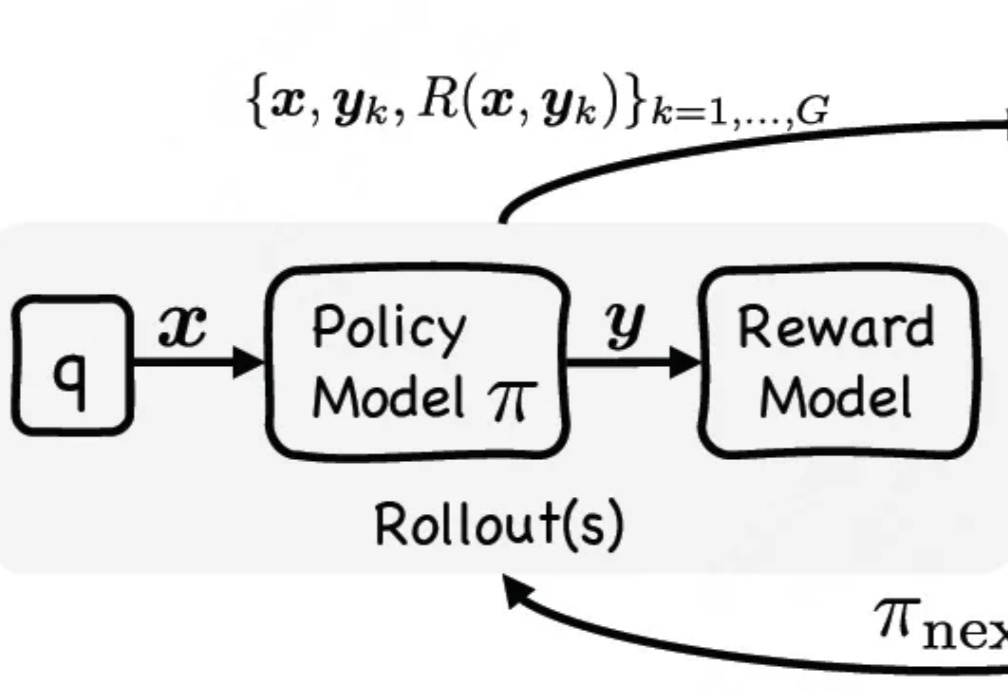
通过单阶段监督微调与强化微调结合,让大模型在训练时能同时利用专家演示和自我探索试错,有效提升大模型推理性能。
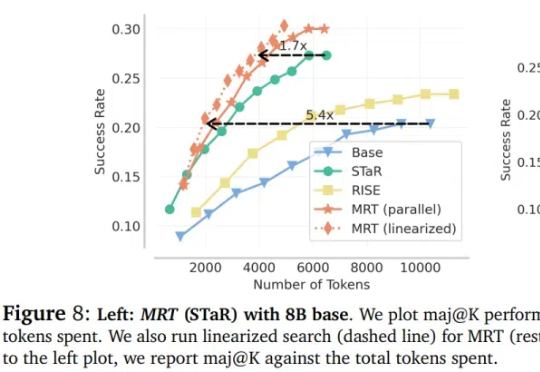
大语言模型(LLM)在推理领域的最新成果表明了通过扩展测试时计算来提高推理能力的潜力,比如 OpenAI 的 o1 系列。
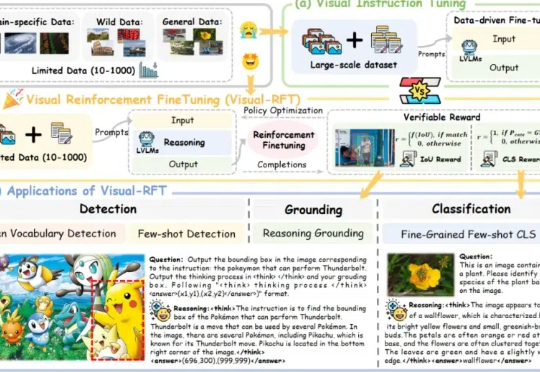
通过针对视觉的细分类、目标检测等任务设计对应的规则奖励,Visual-RFT 打破了 DeepSeek-R1 方法局限于文本、数学推理、代码等少数领域的认知,为视觉语言模型的训练开辟了全新路径!
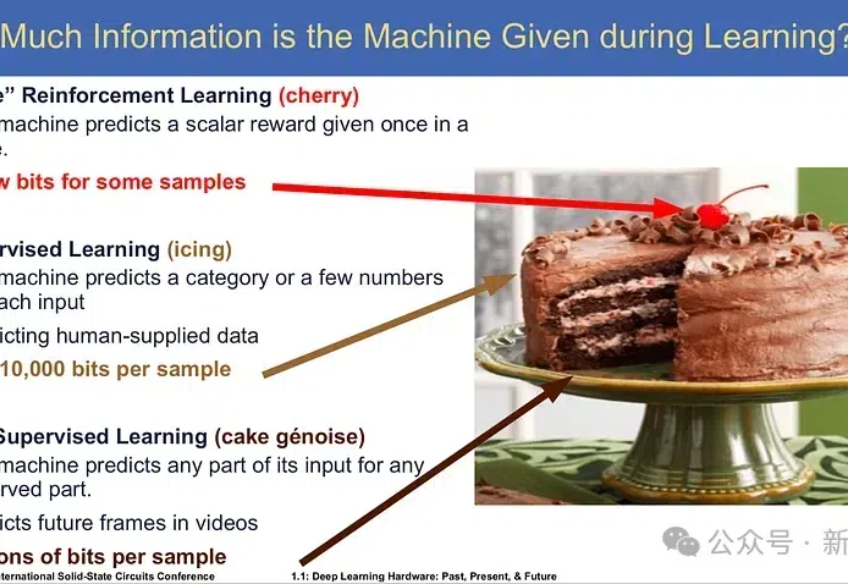
只需几十个样本即可训练专家模型,强化微调RLF能掀起强化学习热潮吗?具体技术实现尚不清楚,AI2此前开源的RLVR或许在技术思路上存在相似之处。
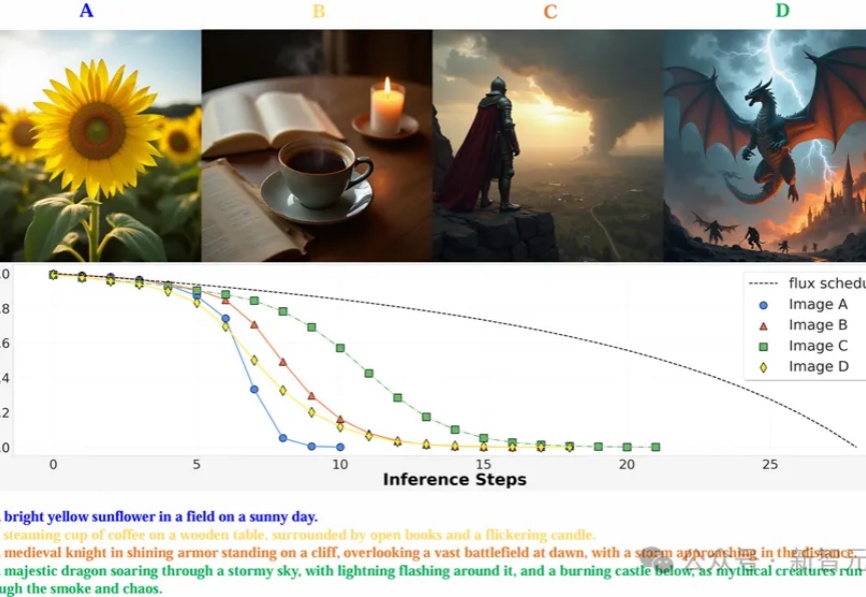
MAPLE实验室提出通过强化学习优化图像生成模型的去噪过程,使其能以更少的步骤生成高质量图像,在多个图像生成模型上实现了减少推理步骤,还能提高图像质量。
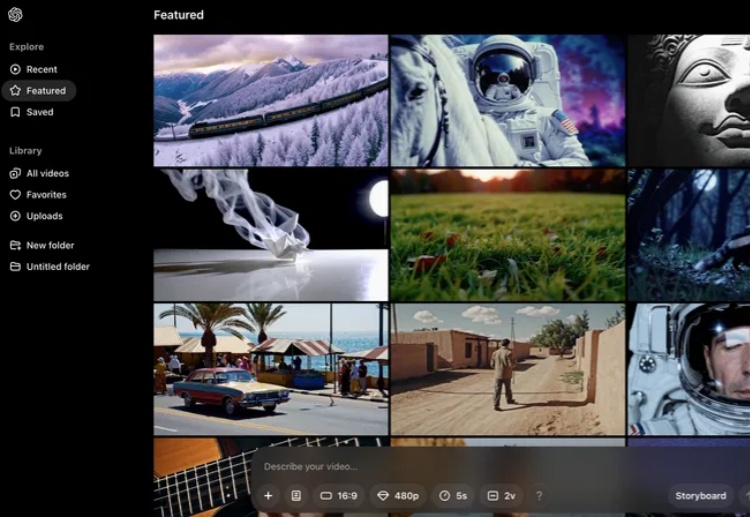
OpenAI发布会直播第3天,继第1天完全版o1和200美元月费ChatGPT Pro会员,以及第2天的强化微调工具后,OpenAI终于填上9个月前的期货大坑,正式发布了观众敲碗已久的全新视频生成模型——Sora Turbo。

2024 年 12 月 6 号加州时间上午 11 点,OpenAI 发布了新的 Reinforcement Finetuning 方法,用于构造专家模型。对于特定领域的决策问题,比如医疗诊断、罕见病诊断等等,只需要上传几十到几千条训练案例,就可以通过微调来找到最有的决策。
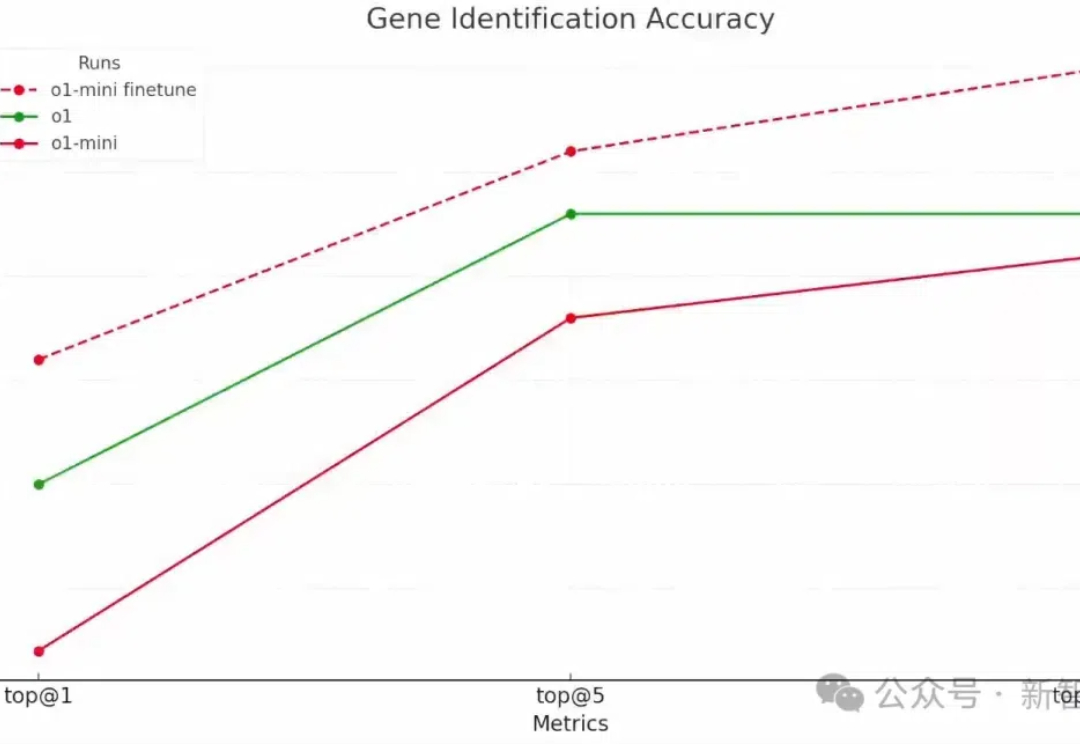
OpenAI第二天的直播,揭示了强化微调的强大威力:强化微调后的o1-mini,竟然全面超越了地表最强基础模型o1。而被奥特曼称为「2024年我最大的惊喜」的技术,技术路线竟和来自字节跳动之前公开发表的强化微调研究思路相同。