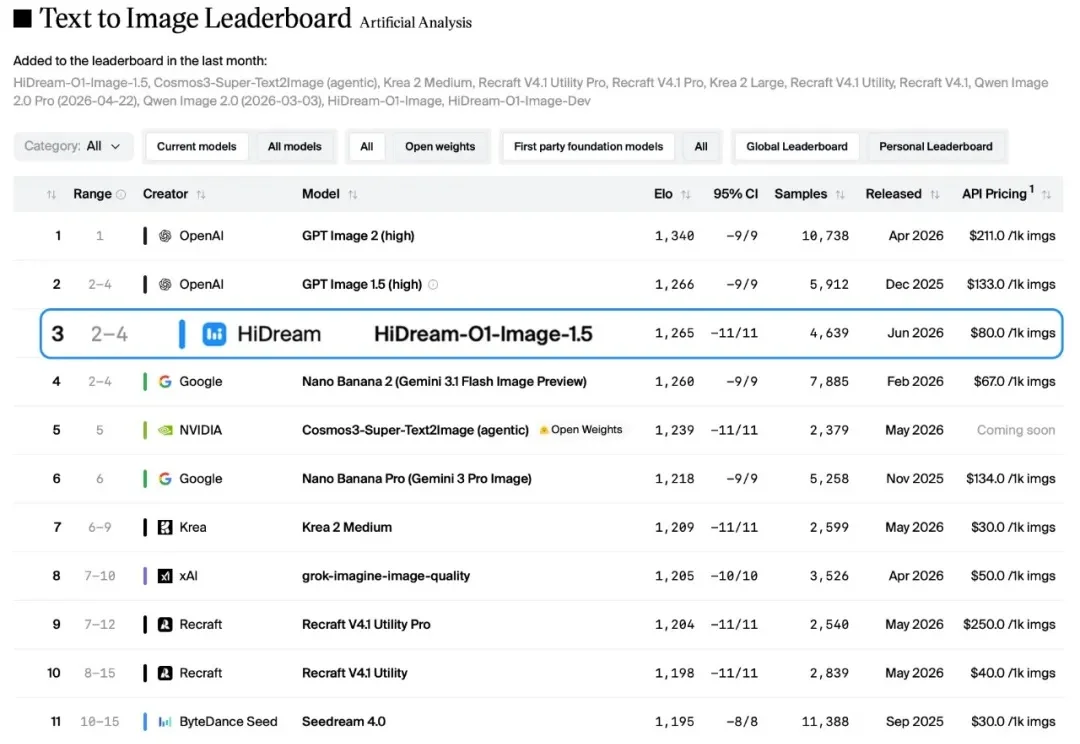
HiDream-O1-Image-1.5 刷新国产图像生成模型纪录:砍掉 VAE,是图像模型的未来吗?
HiDream-O1-Image-1.5 刷新国产图像生成模型纪录:砍掉 VAE,是图像模型的未来吗?文生图的"慢思考",到底有没有用?
来自主题: AI资讯
9081 点击 2026-06-11 10:41
 搜索
搜索
文生图的"慢思考",到底有没有用?

今天,“港股AGI第一股”云知声发布其最新通用大语言模型U2,该模型是由云知声自研的、基于快慢思考融合的MoE(混合专家)范式构建的通用大语言模型。U2跳出了传统大模型盲目堆参数、堆Token的内卷路径,实现了“小参数强能力、少Token高产出、低算力低成本”的进化。

Sora画下的饼终于被做熟了!用DeepSeek式的慢思考逻辑,把AI视频从「看运气抽卡」变成了「确定性交付」,这才是电商人真正需要的工业革命。

国产自研开源模型,让模型不用在快思考和慢思考间二选一了!
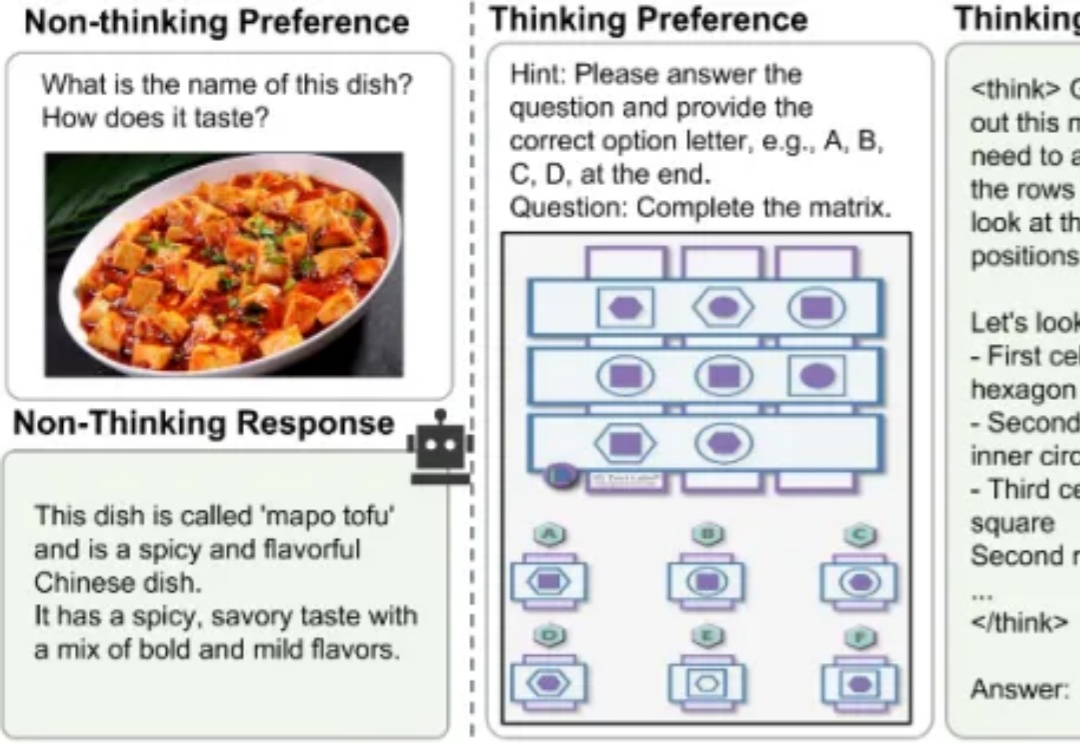
当前,业界顶尖的大模型正竞相挑战“过度思考”的难题,即无论问题简单与否,它们都采用 “always-on thinking” 的详细推理模式。无论是像 DeepSeek-V3.1 这种依赖混合推理架构提供需用户“手动”介入的快慢思考切换,还是如 GPT-5 那样通过依赖庞大而高成本的“专家路由”机制提供的自适应思考切换。

该大模型由海洋精准感知技术全国重点实验室(浙江大学)牵头研发,具备基础的海洋专业知识问答,以及声呐图像、海洋观测图等海洋特色多模态数据的自然语言解读能力。其采用的领域知识增强“慢思考”推理机制,相较现有通用大模型能有效降低幻觉式错误。
在文本推理领域,以GPT-o1、DeepSeek-R1为代表的 “慢思考” 模型凭借显式反思机制,在数学和科学任务上展现出远超 “快思考” 模型(如 GPT-4o)的优势。
孙子兵法有云:“故其疾如风,其徐如林”,意指在行进迅速时,如狂风飞旋;而在行进从容时,如森林徐徐展开。

在人工智能迅猛发展的时代,AI 大模型已成为推动科技进步与社会变革的核心力量。回顾 AI 大模型的发展史,不难发现,AI 正逐渐从“快思考”转变为“慢思考”。

2025 年初,OpenAI、Perplexity、xAI 等 AI 公司都相继推出 Deep(Re)Search 功能。交给模型慢慢思考从而得到更详细的回答,成为了新潮流。