
NeurIPS 2024|浙大 & 微信 & 清华:彻底解决扩散模型反演问题
NeurIPS 2024|浙大 & 微信 & 清华:彻底解决扩散模型反演问题随着扩散生成模型的发展,人工智能步入了属于 AIGC 的新纪元。扩散生成模型可以对初始高斯噪声进行逐步去噪而得到高质量的采样。当前,许多应用都涉及扩散模型的反演,即找到一个生成样本对应的初始噪声。当前的采样器不能兼顾反演的准确性和采样的质量。
来自主题: AI技术研报
8147 点击 2024-11-02 17:08
 搜索
搜索
随着扩散生成模型的发展,人工智能步入了属于 AIGC 的新纪元。扩散生成模型可以对初始高斯噪声进行逐步去噪而得到高质量的采样。当前,许多应用都涉及扩散模型的反演,即找到一个生成样本对应的初始噪声。当前的采样器不能兼顾反演的准确性和采样的质量。
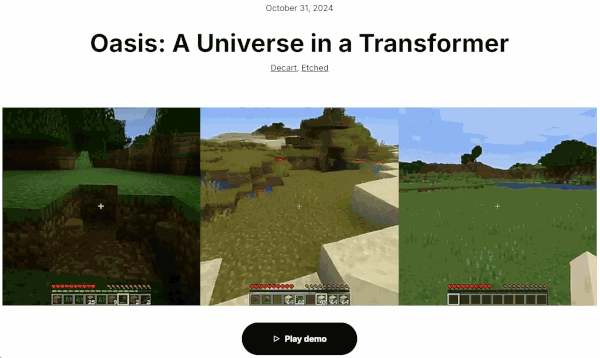
两个月前,我们对 AI 游戏的认知刚刚被谷歌 GameNGen 颠覆。他们实现了历史性的突破,从此不再需要游戏引擎,AI 能基于扩散模型,为玩家生成实时可玩的游戏。

多模态模型,统一图像生成。

LLM统一了语言生成任务,图像生成可以吗?就在刚刚,智源推出了全新扩散模型架构OmniGen,单个模型就能生成图像,彻底告别繁琐工作流!
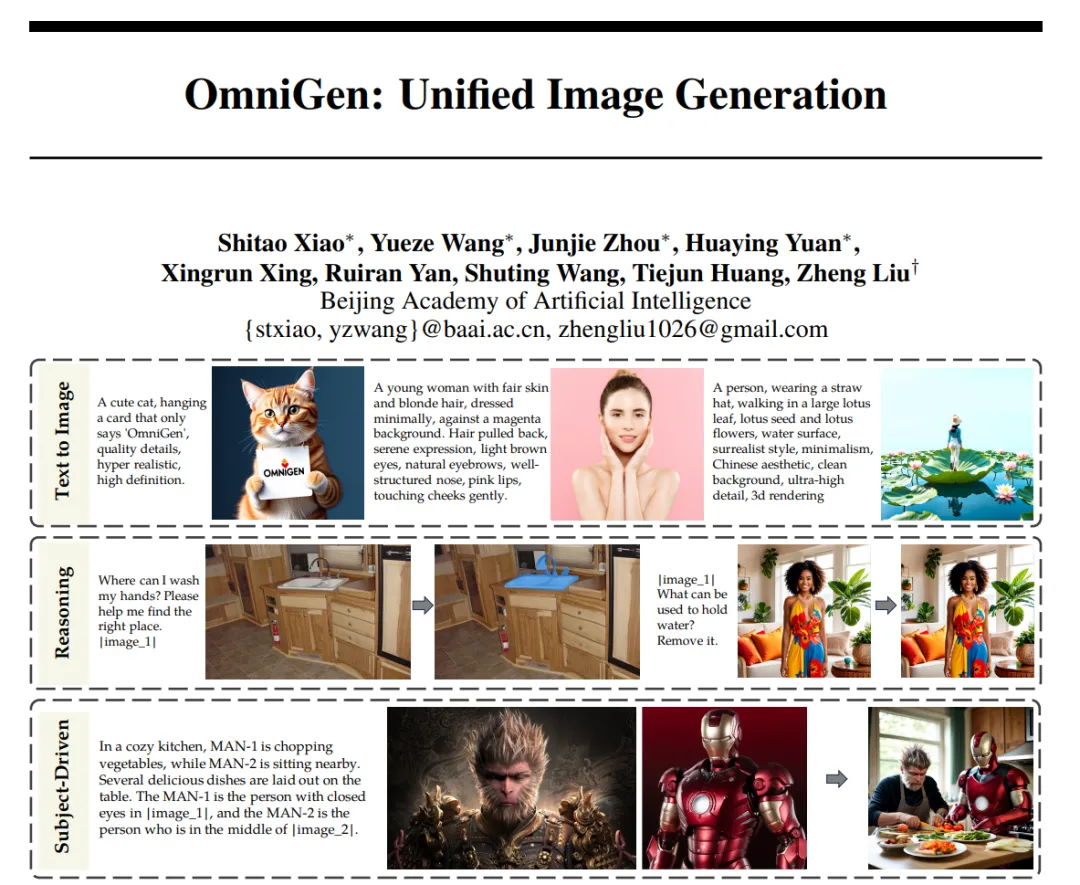
大型语言模型(LLM)的出现统一了语言生成任务,并彻底改变了人机交互。然而,在图像生成领域,能够在单一框架内处理各种任务的统一模型在很大程度上仍未得到探索。近日,智源推出了新的扩散模型架构 OmniGen,一种新的用于统一图像生成的多模态模型。

扩散模型(Diffusion Models, DMs)已经成为文本到图像生成领域的核心技术之一。凭借其卓越的性能,这些模型可以生成高质量的图像,广泛应用于各类创作场景,如艺术设计、广告生成等。

两位清华校友,在OpenAI发布最新研究—— 生成图像,但速度是扩散模型的50倍。 路橙、宋飏再次简化了一致性模型,仅用两步采样,就能使生成质量与扩散模型相媲美。

在NLP领域,研究者们已经充分认识并认可了表征学习的重要性,那么视觉领域的生成模型呢?最近,谢赛宁团队发表的一篇研究就拿出了非常有力的证据:Representation matters!

多项改进实现规模空前的连续时间一致性模型。

性能不输SOTA模型,计算开销却更低了——