
告别「盲目自信」,CCD:扩散语言模型推理新SOTA
告别「盲目自信」,CCD:扩散语言模型推理新SOTA扩散语言模型(Diffusion Language Models)以其独特的 “全局规划” 与并行解码能力广为人知,成为 LLM 领域的全新范式之一。然而在 Any-order 解码模式下,其通常面临
来自主题: AI技术研报
8279 点击 2025-12-13 10:59
 搜索
搜索
扩散语言模型(Diffusion Language Models)以其独特的 “全局规划” 与并行解码能力广为人知,成为 LLM 领域的全新范式之一。然而在 Any-order 解码模式下,其通常面临
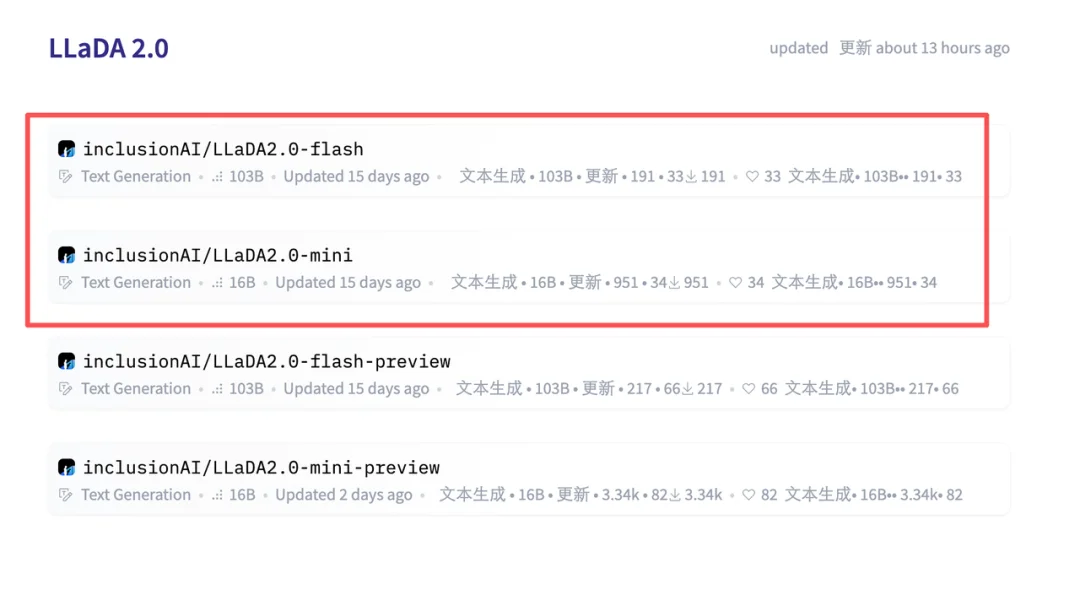
前段时间,我们在 HuggingFace 页面发现了两个新模型:LLaDA2.0-mini 和 LLaDA2.0-flash。它们来自蚂蚁集团与人大、浙大、西湖大学组成的联合团队,都采用了 MoE 架构。前者总参数量为 16B,后者总参数量则高达 100B—— 在「扩散语言模型」这个领域,这是从未见过的规模。
基于扩散的大语言模型 (dLLM) 凭借全局解码和双向注意力机制解锁了原生的并行解码和受控生成的潜力,最近吸引了广泛的关注。例如 Fast-dLLM 的现有推理框架通过分块半自回归解码进一步实现了 dLLM 对 KV cache 的支持,挑战了传统自回归 LLMs 的统治地位。
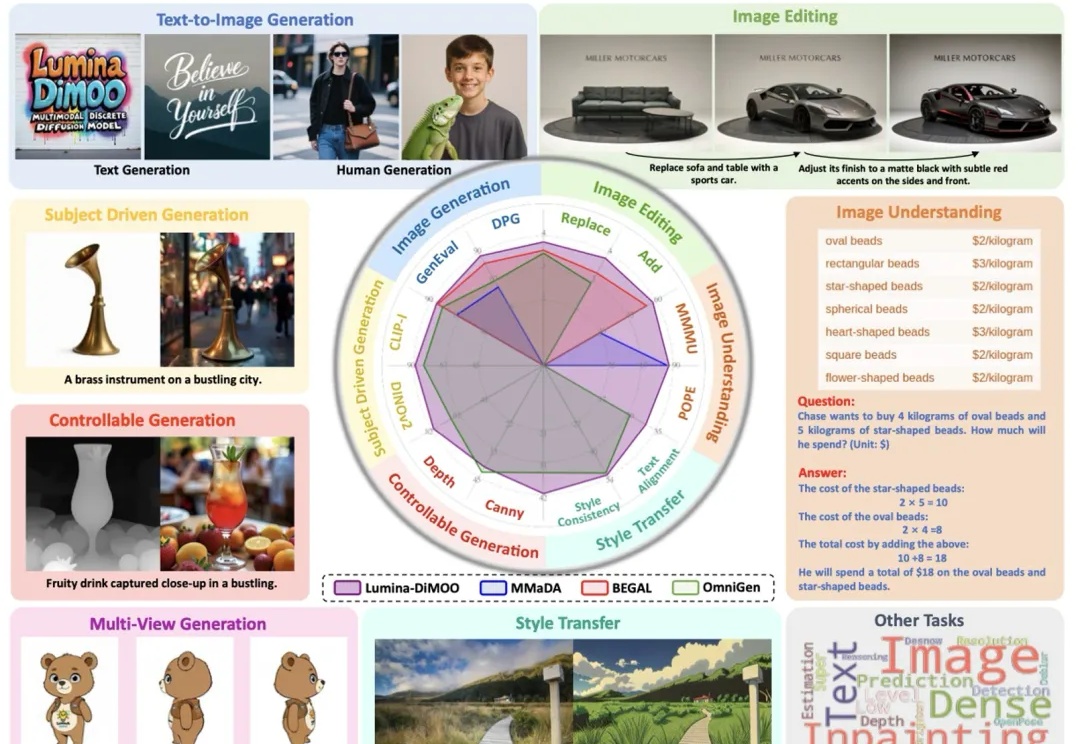
上海人工智能实验室推出了一款革新的多模态生成理解一体化的扩散语言模型 ——Lumina-DiMOO。基于离散扩散建模(Discrete Diffusion Modeling),Lumina-DiMOO 打破了多模态任务之间的壁垒,在同一离散扩散框架下,完成从 文本→图像、图像→图像、图像→文本的全栈能力闭环。
扩散大语言模型得到了突飞猛进的发展,早在 25 年 2 月 Inception Labs 推出 Mercury—— 第一个商业级扩散大型语言模型,同期人民大学发布第一个开源 8B 扩散大语言模型 LLaDA,5 月份 Gemini Diffusion 也接踵而至。

近日,上海人工智能实验室针对该难题提出全新范式 SDAR (Synergistic Diffusion-AutoRegression)。该方法通过「训练-推理解耦」的巧妙设计,无缝融合了 AR 模型的高性能与扩散模型的并行推理优势,能以极低成本将任意 AR 模型「改造」为并行解码模型。
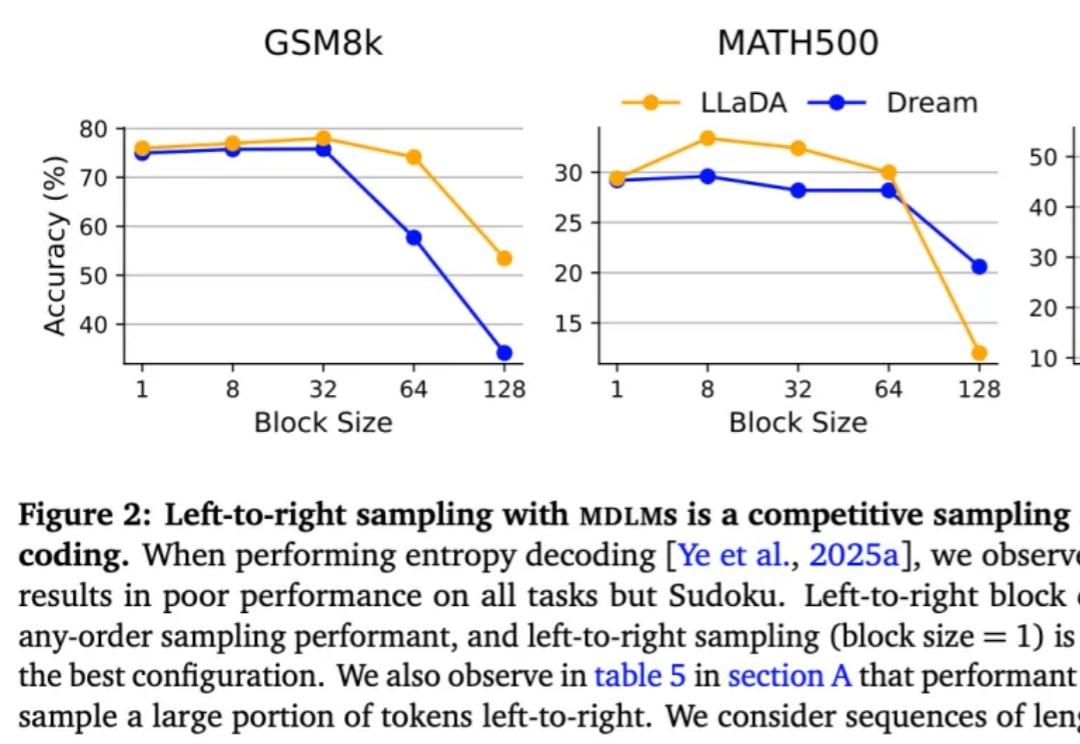
按从左到右的顺序依次生成下一个 token 真的是大模型生成方式的最优解吗?最近,越来越多的研究者对此提出质疑。其中,有些研究者已经转向一个新的方向 —— 掩码扩散语言模型(MDLM)。

近期,扩散语言模型备受瞩目,提供了一种不同于自回归模型的文本生成解决方案。为使模型能够在生成过程中持续修正与优化中间结果,西湖大学 MAPLE 实验室齐国君教授团队成功训练了具有「再掩码」能力的扩散语言模型(Remasking-enabled Diffusion Language Model, RemeDi 9B)。

扩散语言模型(Diffusion Language Models,DLM)一直以来都令研究者颇感兴趣,因为与必须按从左到右顺序生成的自回归模型(Autoregressive, AR)不同,DLM 能实现并行生成,这在理论上可以实现更快的生成速度,也能让模型基于前后文更好地理解生成语境。
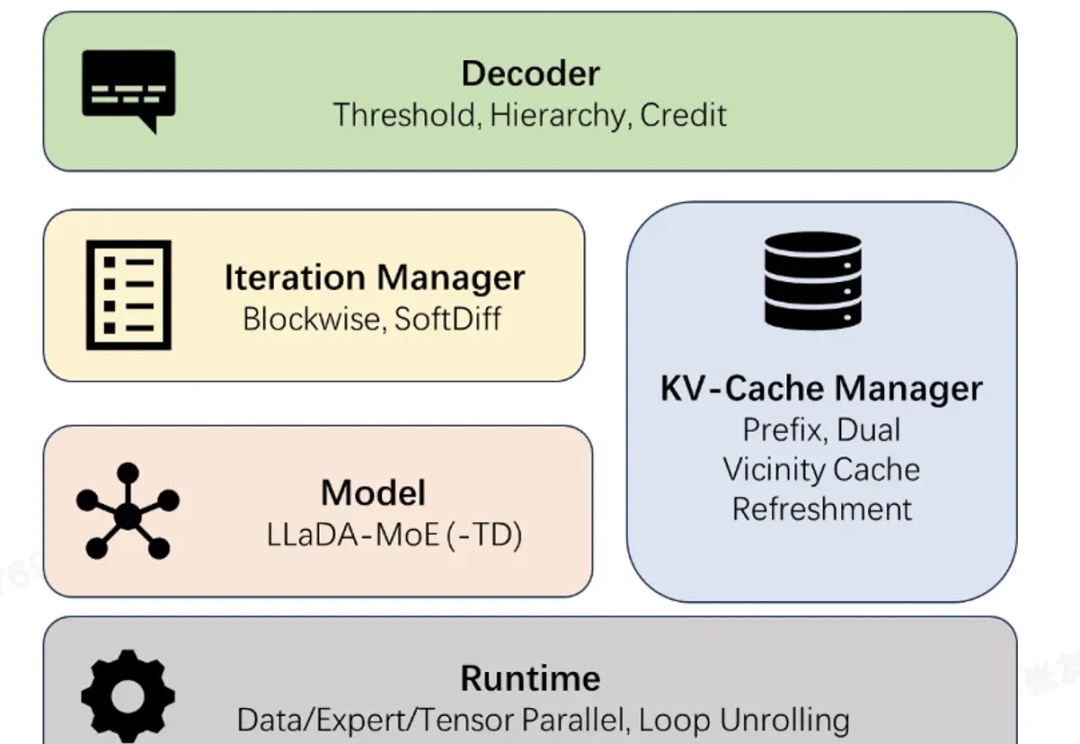
近日,蚂蚁集团正式开源业界首个高性能扩散语言模型(Diffusion Large Language Model,dLLM)推理框架 dInfer。