
国内首家百亿估值纯推理GPU独角兽诞生!专访曦望联席CEO王湛:谁的推理成本更低谁就是赢家
国内首家百亿估值纯推理GPU独角兽诞生!专访曦望联席CEO王湛:谁的推理成本更低谁就是赢家杭州速度,这个词组的含金量还在上升。
来自主题: AI资讯
9279 点击 2026-04-24 09:42
 搜索
搜索
杭州速度,这个词组的含金量还在上升。
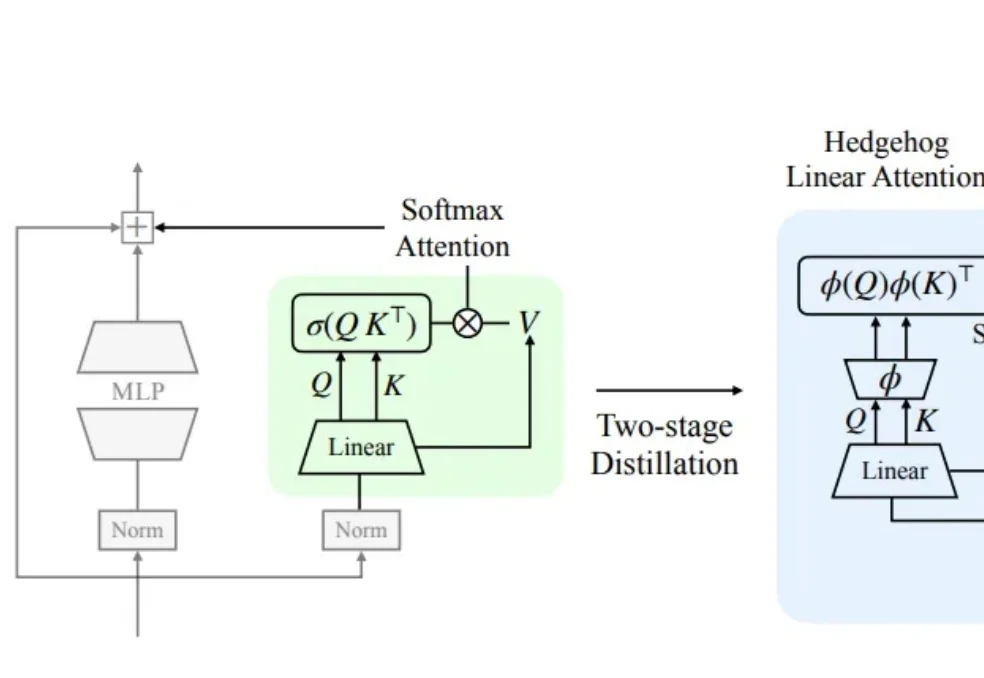
最近,苹果又整了个活儿,很工程、也挺关键: 把又贵又强的 Transformer,改造成又便宜又差不多强的 Mamba。而且,性能基本没怎么掉。

视频生成进入大规模时代,但计算成本也炸了。
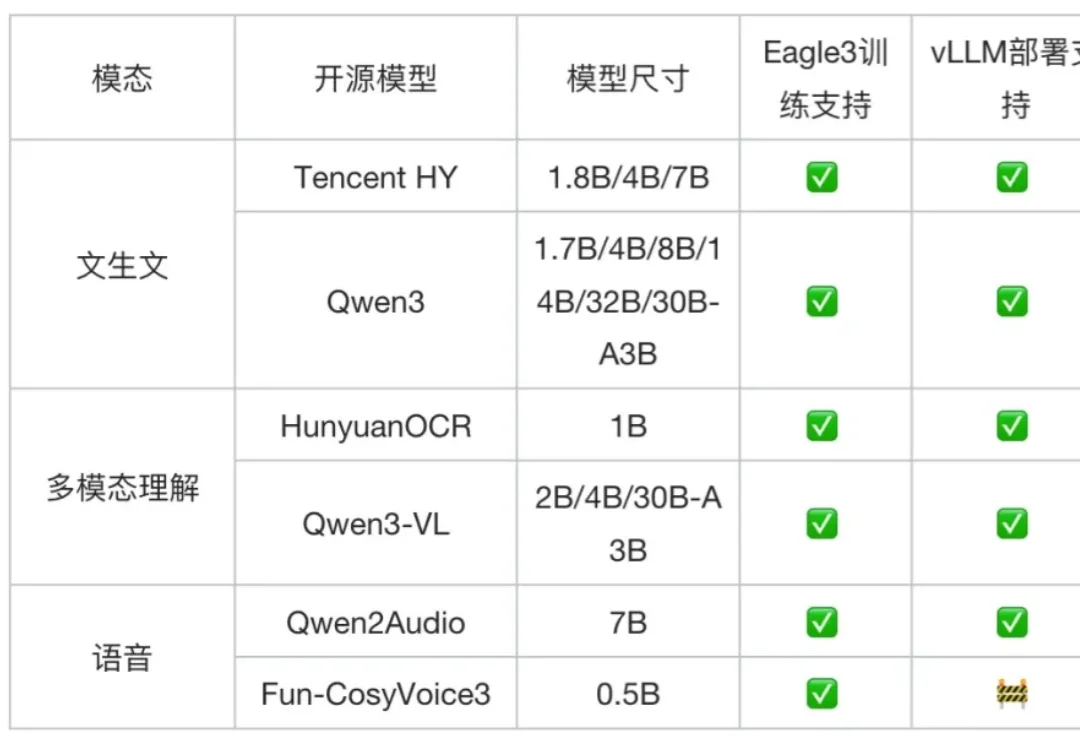
随着大模型步入规模化应用深水区,日益高昂的推理成本与延迟已成为掣肘产业落地的核心瓶颈。在 “降本增效” 的行业共识下,从量化、剪枝到模型蒸馏,各类压缩技术竞相涌现,但往往难以兼顾性能损耗与通用性。
「每隔 10 到 15 年,计算行业就会革新一次,每次都会催生出新形态的平台。现在,有两个转变在同时进行:应用将会构建于 AI 之上,你构建软件的方式也将改变。」
在检索增强生成中,扩大生成模型规模往往能提升准确率,但也会显著抬高推理成本与部署门槛。CMU 团队在固定提示模板、上下文组织方式与证据预算,并保持检索与解码设置不变的前提下,系统比较了生成模型规模与检索语料规模的联合效应,发现扩充检索语料能够稳定增强 RAG,并在多项开放域问答基准上让小中型模型在更大语料下达到甚至超过更大模型在较小语料下的表现,同时在更高语料规模处呈现清晰的边际收益递减。

2026 年将是 OpenAI 的生死赛点。面对预计 170 亿美元的惊人现金黑洞和谷歌 Gemini 的凶猛反扑,奥特曼被迫启动「红色代码」。一边是史无前例的千亿融资计划,一边是推理成本倒挂的财务危机,这究竟是通往 AGI 的必经之路,还是硅谷最大的泡沫破裂前夜?
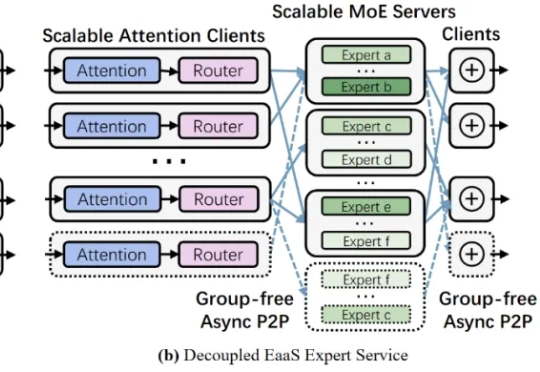
近年来,大型语言模型的参数规模屡创新高,随之而来的推理开销也呈指数级增长。如何降低超大模型的推理成本,成为业界关注的焦点之一。Mixture-of-Experts (MoE,混合专家) 架构通过引入大量 “专家” 子模型,让每个输入仅激活少数专家,从而在参数规模激增的同时避免推理计算量同比增长。

Mila 和微软研究院等多家机构的一个联合研究团队却另辟蹊径,提出了一个不同的问题:如果环境从一开始就不会造成计算量的二次级增长呢?他们提出了一种新的范式,其中策略会在基于一个固定大小的状态上进行推理。他们将这样的策略命名为马尔可夫式思考机(Markovian Thinker)。

英伟达还能“猖狂”多久?——不出三年! 实现AGI需要新的架构吗?——不用,Transformer足矣! “近几年推理成本下降了100倍,未来还有望再降低10倍!” 这些“暴论”,出自Flash Attention的作者——Tri Dao。