刚刚,OpenAI/Gemini共斩ICPC 2025金牌!OpenAI满分碾压横扫全场
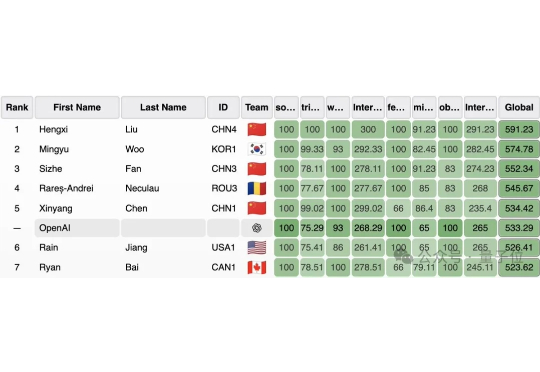
刚刚,OpenAI/Gemini共斩ICPC 2025金牌!OpenAI满分碾压横扫全场ICPC 2025全球总决赛诞生历史性一幕:谷歌Gemini与OpenAI推理模型同时斩获金牌!Gemini在5小时内攻下12题中的10题,并在30分钟破解难倒所有人类的死亡C题;而OpenAI更是满分12/12,碾压139支人类队伍,成为赛场唯一全解团队。
来自主题: AI资讯
9132 点击 2025-09-18 14:05