

MiniMax-M1 登场,MiniMax 再次证明自己是一家模型驱动的 AI 公司
MiniMax-M1 登场,MiniMax 再次证明自己是一家模型驱动的 AI 公司好饭不怕晚,MiniMax 终于把这款金字塔尖的推理模型拿出来了。
来自主题: AI资讯
8913 点击 2025-06-18 15:13
好饭不怕晚,MiniMax 终于把这款金字塔尖的推理模型拿出来了。
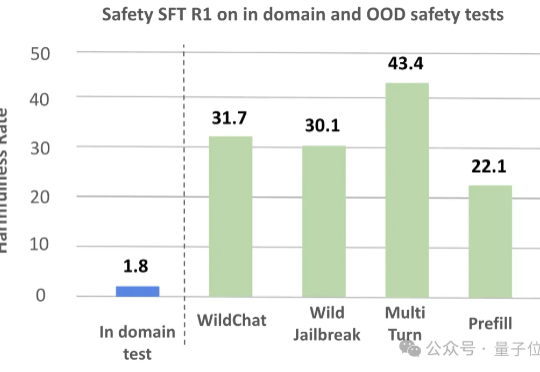
大型推理模型(LRMs)在解决复杂任务时展现出的强大能力令人惊叹,但其背后隐藏的安全风险不容忽视。
强化学习·RL范式尝试为LLMs应用于广泛的Agentic AI甚至构建AGI打开了一扇“深度推理”的大门,而RL是否是唯一且work的一扇门,先按下不表(不作为今天跟大家唠的重点),至少目前看来,随着o1/o3/r1/qwq..等一众语言推理模型的快速发展,正推动着LLMs和Agentic AI在不同领域的价值与作用,
推理模型开始「自言自语」、量子计算进入临界点……AI大航海时代已然启航,这不是一次产品发布会,而是未来的预言书。巴黎GTC大会,黄仁勋开讲了!这次他脱下了皮衣。
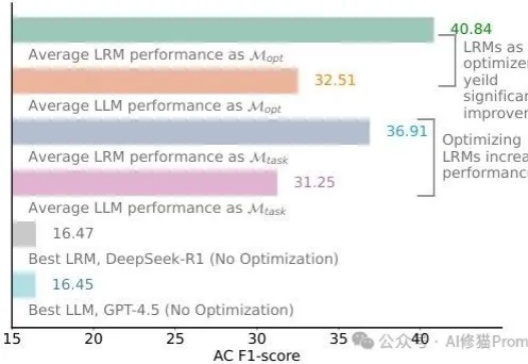
还记得DeepSeek-R1发布时AI圈的那波狂欢吗?"提示工程已死"、"再也不用费心写复杂提示了"、"推理模型已经聪明到不再需要学习提示词了"......这些观点在社交媒体上刷屏,连不少技术大佬都在转发。再到最近,“提示词写死了”......现实总是来得这么快——乔治梅森大学的研究者们用一个严谨得让人无法反驳的实验,狠狠打了所有人的脸!

第一财经「新皮层」独家获悉,MiniMax即将推出文本推理模型,并将开源。半个月前,MiniMax刚刚发布和开源了视觉推理模型Orsta(One RL to See Them All)。MiniMax今年3月做出产品线调整,将旗下现有产品「海螺AI」更名为「MiniMax」,与公司同名,聚焦文本理解和生成;

强推理终于要卷速度了。 大模型强推理赛道,又迎来一位重量级玩家。
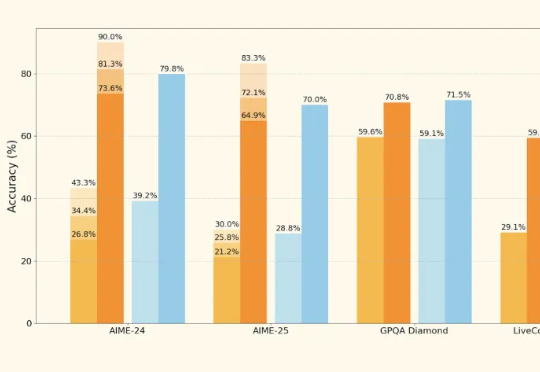
“欧洲的OpenAI”Mistral AI终于发布了首款推理模型——Magistral。 然而再一次遭到网友质疑:怎么又不跟最新版Qwen和DeepSeek R1 0528对比?
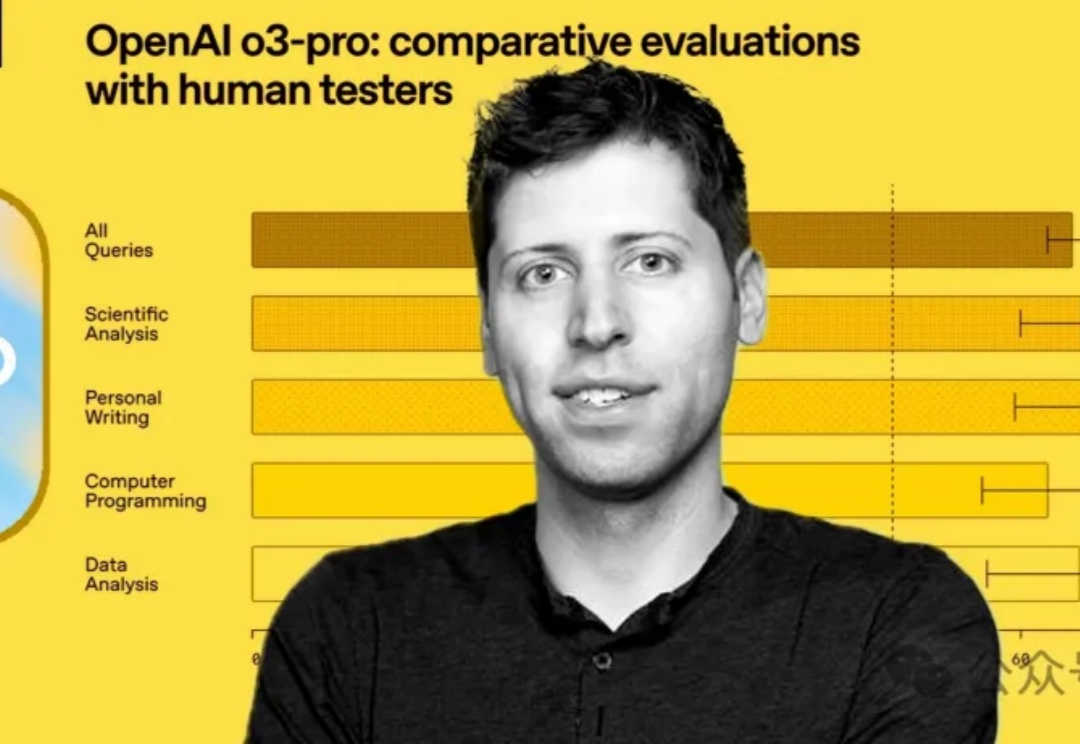
最强推理模型一夜易主!深夜,o3-pro毫无预警上线,刷爆数学、编程、科学基准,强势碾压o1-pro和o3。更惊艳的是,o3价格直接暴降80%,叫板Gemini 2.5 Pro。

SemiAnalysis全新硬核爆料,意外揭秘了OpenAI全新模型的秘密?据悉,新模型介于GPT-4.1和GPT-4.5之间,而下一代推理模型o4将基于GPT-4.1训练,而背后最大功臣,就是强化学习。