
我在县城“驯化”AI:有多少“人工”才有多少“智能”
我在县城“驯化”AI:有多少“人工”才有多少“智能”AI催生数据标注员,文科生转型与大厂调整。
来自主题: AI资讯
7327 点击 2025-03-07 10:16
AI催生数据标注员,文科生转型与大厂调整。
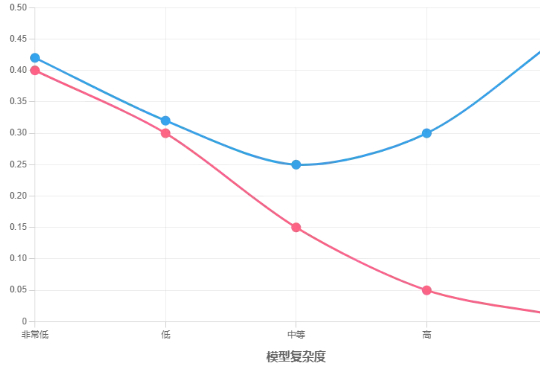
当模型复杂度增加到一定程度后,模型开始对训练数据中的噪声和异常值进行拟合,而不是仅仅学习数据中的真实模式。这导致模型在训练数据上表现得非常好,但在新的数据上表现不佳,因为新的数据中噪声和异常值的分布与训练数据不同。

新一代智能数据分析架构的开创者

本文提出了一种轨迹级别 SE (3) 等变的扩散策略(ET-SEED),通过将等变表示学习和扩散策略结合,使机器人能够在极少的示范数据下高效学习复杂操作技能,并能够泛化到不同物体姿态和环境中。
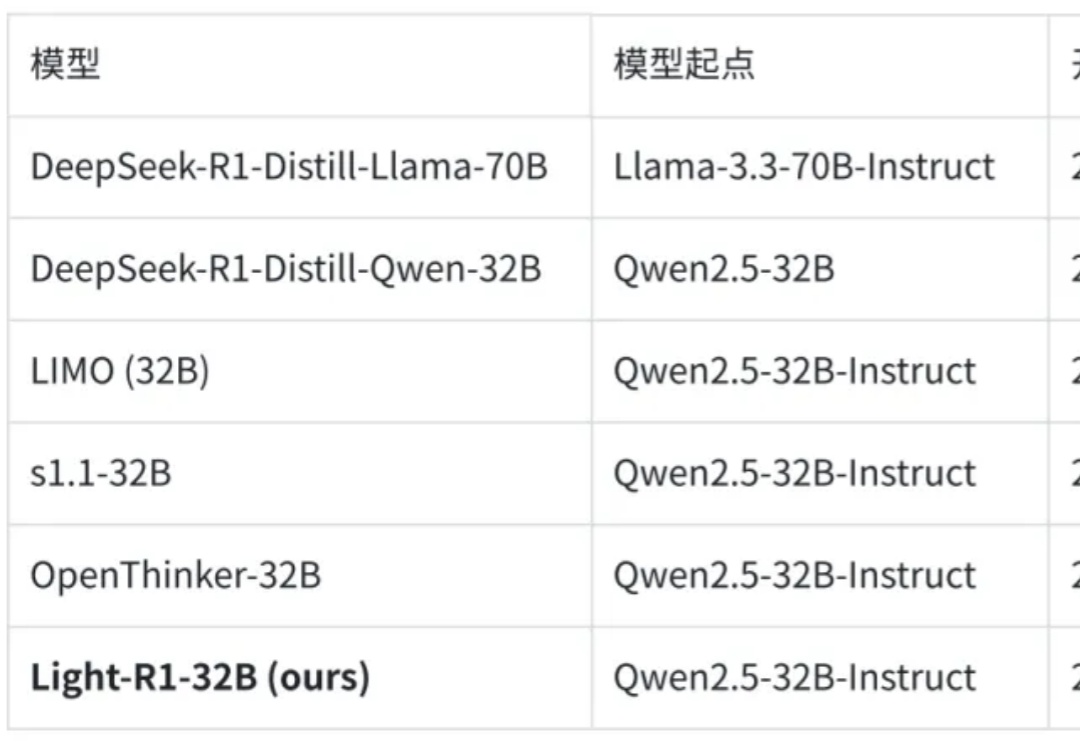
2025 年 3 月 4 日,360 智脑开源了 Light-R1-32B 模型,以及全部训练数据、代码。仅需 12 台 H800 上 6 小时即可训练完成,从没有长思维链的 Qwen2.5-32B-Instruct 出发,仅使用 7 万条数学数据训练,得到 Light-R1-32B

与3D物理环境交互、适应不同机器人形态并执行复杂任务的通用操作策略,一直是机器人领域的长期追求。

2025年2月,如果不是长期从事人口研究的中国人民大学教授李婷的公开辟谣,很多人都真诚地相信了一组数据——“中国80后累计死亡率为5.20%”。
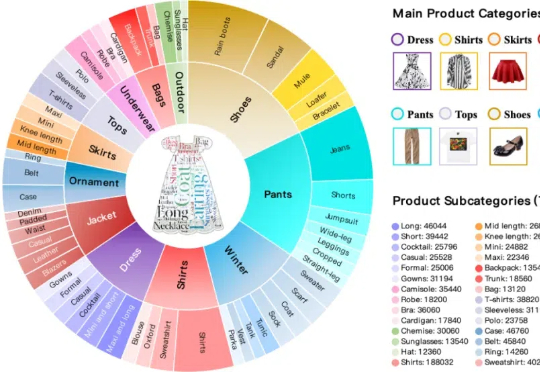
本文构建了新的多轮组合图像检索数据集和评测基准FashionMT。其特点包括:(1)回溯性:每轮修改文本可能涉及历史参考图像信息(如保留特定属性),要求算法回溯利用多轮历史信息;(2)多样化:FashionMT包含的电商图像数量和类别分别是MT FashionIQ的14倍和30倍,且交互轮次数量接近其27倍,提供了丰富的多模态检索场景。

去年10月,家族元老41岁的孙子Kuok Meng Wei执掌的集团非上市子公司K2 Strategic在占地700英亩的塞德纳克科技园(Sedenak Tech Park)开设了一座60兆瓦的数据中心(容量以能耗计)。

基于内置思维链的思考方法为解决多轮会话中存在的问题提供了研究方向。按照思考方法收集训练数据集,通过有监督学习微调大语言模型;训练一个一致性奖励模型,并将该模型用作奖励函数,以使用强化学习来微调大语言模型。结果大语言模型的推理能力和计划能力,以及执行计划的能力得到了增强。