

全面增强LLM推理/规划/执行力!北航提出全新「内置CoT」思考方法
全面增强LLM推理/规划/执行力!北航提出全新「内置CoT」思考方法基于内置思维链的思考方法为解决多轮会话中存在的问题提供了研究方向。按照思考方法收集训练数据集,通过有监督学习微调大语言模型;训练一个一致性奖励模型,并将该模型用作奖励函数,以使用强化学习来微调大语言模型。结果大语言模型的推理能力和计划能力,以及执行计划的能力得到了增强。
来自主题: AI资讯
7378 点击 2025-03-04 19:46
基于内置思维链的思考方法为解决多轮会话中存在的问题提供了研究方向。按照思考方法收集训练数据集,通过有监督学习微调大语言模型;训练一个一致性奖励模型,并将该模型用作奖励函数,以使用强化学习来微调大语言模型。结果大语言模型的推理能力和计划能力,以及执行计划的能力得到了增强。
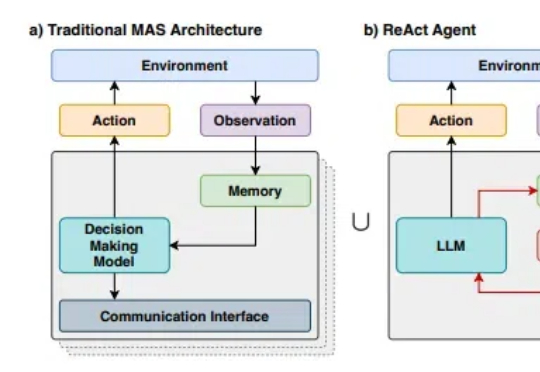
随着R1等先进推理模型展现出接近人类的推理能力,多代理系统(Multi-Agent Systems,MAS)的发展也出现了前所未有的机遇。然而,随着我们尝试构建越来越复杂的多代理系统,一个核心问题日益凸显:如何在保持系统灵活性的同时,降低开发和维护的复杂度?

在 DeepSeek 生成的文本中,有 74.2% 的文本在风格上与 OpenAI 模型具有惊人的相似性?这是一项新研究得出的结论。这项研究来自 Copyleaks—— 一个专注于检测文本中的抄袭和 AI 生成内容的平台。
AFFiNE,一个开源的 AI 协作知识库,集成了完整文档、白板和数据库的工作空间。累计融资 1000 万美元,开源项目在 Github 上超过 4.5 万 stars。创始人、CEO 贺嘉琛,连续创业者。创业前研究天体物理,毕业于格拉斯哥与香港科技大学。

全球生态学家正面临一场「数据海啸」——红外相机陷阱每天产生数百万张野生动物照片,但人工分类需耗时数周。
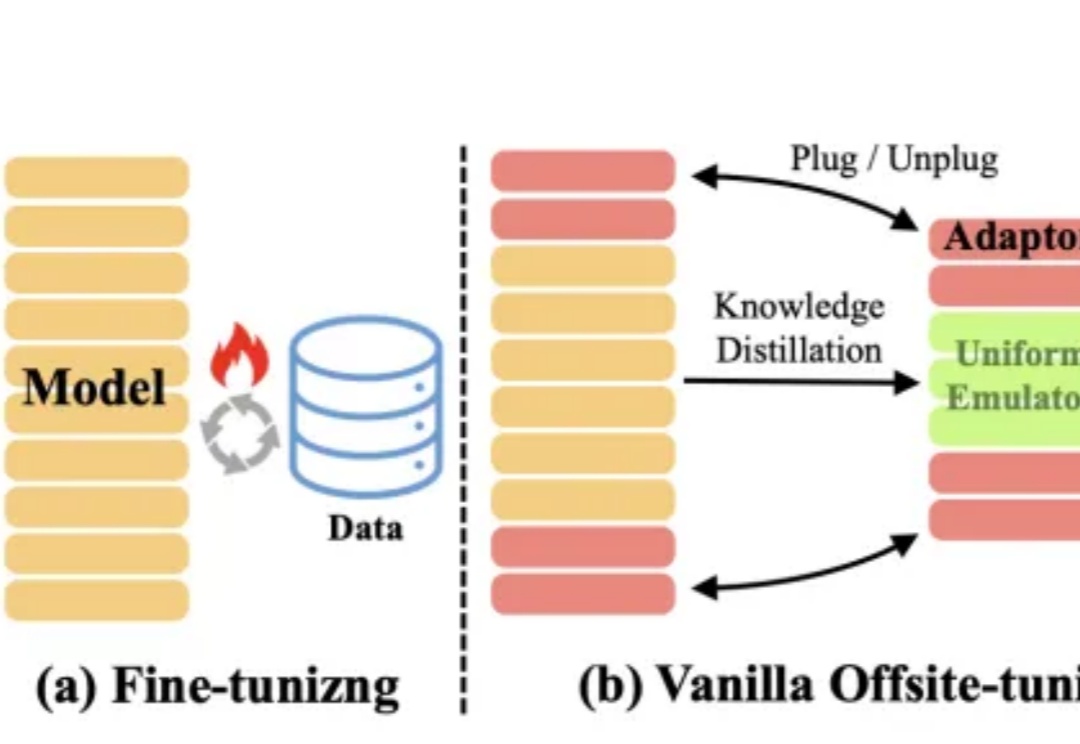
大模型的快速及持续发展,离不开对模型所有权及数据隐私的保护。

什么,你在开发RAG竟然还没听说过Embedding模型还有排名?在AI应用开发热潮中,Embedding模型的选择已成为决定RAG系统成败的关键因素。然而,令人惊讶的是,许多开发者仍依靠直觉或跟风选择模型,而非基于系统化评估。

黑石的野心远不止于对AI的“豪赌”。这家老牌资产管理公司正在加速转型,从传统的不动产投资巨头,转变为全球科技基础设施的资本掌舵者。
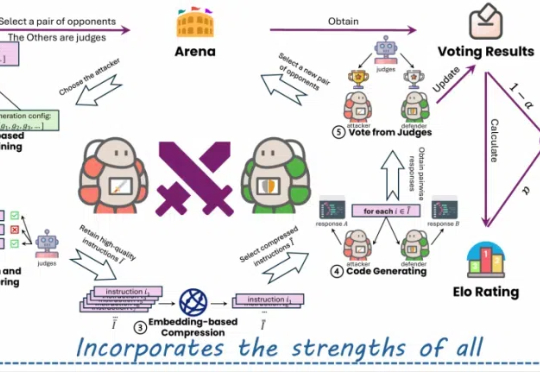
近年来,大型语言模型(LLMs)在代码相关的任务上展现了惊人的表现,各种代码大模型层出不穷。这些成功的案例表明,在大规模代码数据上进行预训练可以显著提升模型的核心编程能力。
Transformer 很成功,更一般而言,我们甚至可以将(仅编码器)Transformer 视为学习可交换数据的通用引擎。由于大多数经典的统计学任务都是基于独立同分布(iid)采用假设构建的,因此很自然可以尝试将 Transformer 用于它们。