
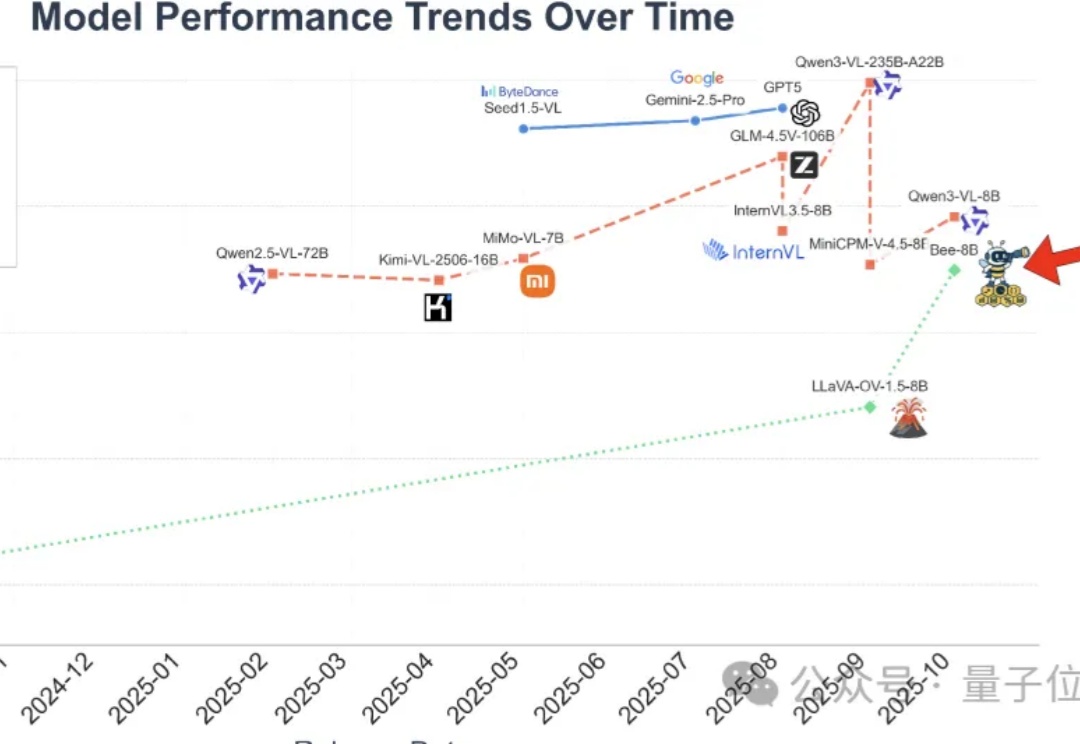
打破数据质量鸿沟!清华腾讯Bee项目发布1500万高质量数据集,刷新MLLM全栈开源SOTA
打破数据质量鸿沟!清华腾讯Bee项目发布1500万高质量数据集,刷新MLLM全栈开源SOTA全开源多模态大模型(MLLM)的性能,长期被闭源和半开源模型“卡脖子”。
来自主题: AI技术研报
8150 点击 2025-11-11 16:39
全开源多模态大模型(MLLM)的性能,长期被闭源和半开源模型“卡脖子”。

通用人工智能的终极瓶颈不是算法、算力和数据的“三驾马车”,而在思想史。

Leonis Capital 在全球超过 10,000 家 AI 初创公司中,基于融资、招聘、用户使用情况,GitHub 趋势、新闻、ProductHunt、ARR 预估等数据和信号,筛选出了 100 家增长最快的初创公司。他们对这 100 家 AI 初创公司进行了详细分析,制作了一份 The Leonis AI 100 的研究报告。

马斯克麾下的新AI虚拟女友Ani看似风光地上线,背后却被曝出员工被迫提供面容和声音等生物数据用于训练。这一做法在xAI公司内部引发争议,多名员工担心自己的相貌和声音可能被滥用于深度伪造,或在未授权情况下被他人使用。此事也让业界反思,在AI竞赛中冲锋陷阵的公司,是否正在以侵犯隐私和道德边界为代价换取技术进步。
OmniVinci是英伟达推出的全模态大模型,能精准解析视频和音频,尤其擅长视觉和听觉信号的时序对齐。它以90亿参数规模,性能超越同级别甚至更高级别模型,训练数据效率是对手的6倍,大幅降低成本。在视频内容理解、语音转录、机器人导航等场景中,OmniVinci能提供高效支持,展现出卓越的多模态应用能力。

过去两年,AI靠模仿人类席卷世界。但强化学习之父Richard Sutton却说:「GenAI的时代正在结束。」他带着图灵奖的荣光,加入一家几乎没人听过的公司——ExperienceFlow.AI,他要让AI不靠人类数据喂养,而靠「经验」觉醒。
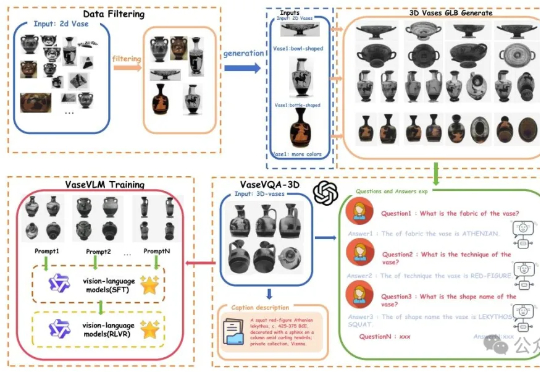
现在AI都懂文物懂历史了。一项来自北京大学的最新研究引发关注:他们推出了全球首个面向古希腊陶罐的3D视觉问答数据集——VaseVQA-3D,并配套推出了专用视觉语言模型VaseVLM。这意味着,AI正在从“识图机器”迈向“文化考古Agent”。

奥特曼称GPT-6或让「AI创造新科学」成真。与此呼应,类「AI科学家」Kosmos登场:12小时读1500篇文献、跑4.2万行代码,生成可溯源报告,并在材料等方向提出新发现。它凭持续记忆自主规划,正由工具迈向合作者;但受数据来源与复现性制约,约20%结论仍需人类裁判。人机协作或将重塑科研,科研范式加速演进,前景可期。
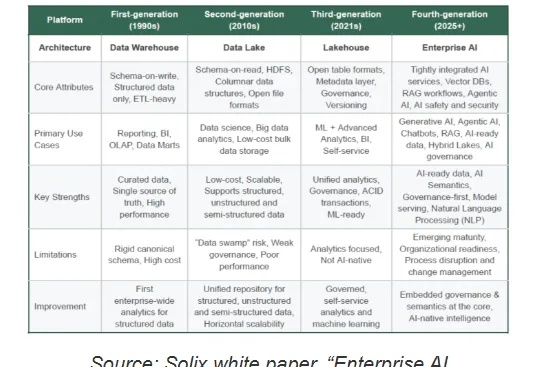
Solix Technologies最近推出了企业AI,据称这是业界首个第四代数据平台。Solix表示,通过将先进的数据管理功能集成到单一平台中,它可以提供企业成功利用AI所需的干净、可信和受治理的数据。

2025年11月4日,一家总部位于英国伦敦的人工智能公司Stability AI,赢得了一项具有里程碑意义的高等法院案件,该案审查了人工智能模型在未经许可的情况下使用大量受版权保护数据的合法性。而本案的原告,Getty Images 在针对人工智能公司 Stability AI 图像生成产品的英国诉讼中基本败诉。