Agent 带来Episodic Workload后,传统开源数据库已经远不够用了
Agent 带来Episodic Workload后,传统开源数据库已经远不够用了如果把一个商业化产品、一个科技公司的底层系统比作一棵树,那任意挑出一个项目,层层抽丝剥茧之后,你一定会发现,最早的年轮,一定与开源有关。
来自主题: AI技术研报
6830 点击 2026-06-12 10:13
 搜索
搜索
如果把一个商业化产品、一个科技公司的底层系统比作一棵树,那任意挑出一个项目,层层抽丝剥茧之后,你一定会发现,最早的年轮,一定与开源有关。

顶级AI编码一日千里,到了生物学领域却频频翻车,并非模型不够聪明,而是科学数据库至今只为人类点鼠标而生。
官宣全球顶尖医院,微软要为AI医疗定制一款大模型!

这篇文章想回答几个大家更关心的基础问题:Vector Lakebase 能解决你的什么问题,什么场景下用它最合适,如何用好Vector Lakebase 。

过去半年,几乎所有Agent框架都在补长期记忆能力。最常见的做法,是给系统接一个向量数据库,把历史对话、用户偏好、项目经验、工具调用结果、失败案例都存进去。看起来,只要把“记忆”这块补上,Agent就能从一次性对话工具变成长期协作伙伴。

过去八九年,我们一直在做一件事:把向量数据库从一个很小众的系统方向,做成 AI 基础设施里的关键组件。
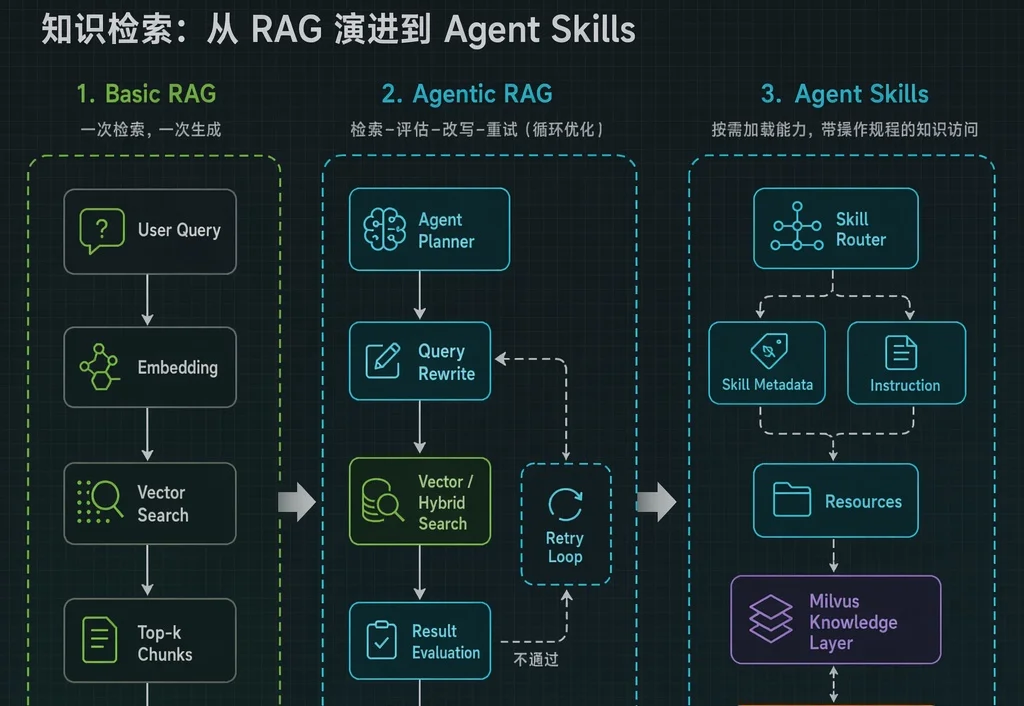
最近一两年,互联网上各种为RAG赛博哭坟的帖子不胜枚举。

在这些场景,一个集合也许一个月只被查询几次,运行时间不超过5小时,用户也并不需要为此投入向量数据库级别的资源建设,让高性能资源一个月时间里有715小时都被浪费。相应的,成本也就成了这一场景下的优先考量要素。而解决这一问题,也是我们选择在近期推出Vector Lakebase 产品的初心所在。

RAG 系统上线后答案出错,绝大多数团队的第一反应都是换更贵的模型、反复调试 prompt。
Reddit 上的 r/DHExchange 板块从来都不缺奇怪的交易。但月初的一个帖子,还是让见多识广的我打了个问号。「我囤积了一个非常有价值的大型数据库,只是不是你想的那种……15 万张粪便图像。」