
科研人有自己的“吃虾”方式!斯坦福普林斯顿最新开源,仅需一行指令
科研人有自己的“吃虾”方式!斯坦福普林斯顿最新开源,仅需一行指令眼见大伙儿玩“龙虾”6到飞起,来自斯坦福&普林斯顿的高校团队也立刻推出了“科研版龙虾”LabClaw。划重点,开!源!人人都能立马用上那种。而且打工方式超级easy,只需一行命令就能调动LabClaw里的龙虾军团。
来自主题: AI资讯
9132 点击 2026-03-16 10:34
眼见大伙儿玩“龙虾”6到飞起,来自斯坦福&普林斯顿的高校团队也立刻推出了“科研版龙虾”LabClaw。划重点,开!源!人人都能立马用上那种。而且打工方式超级easy,只需一行命令就能调动LabClaw里的龙虾军团。

刚刚,由斯坦福具身智能明星赵子豪(Tony Zhao) 与迟宬(Cheng Chi) 创立的机器人公司Sunday Robotics宣布完成1.65亿美元B轮融资。公司估值飙至11.5亿美元,正式进入独角兽行列。
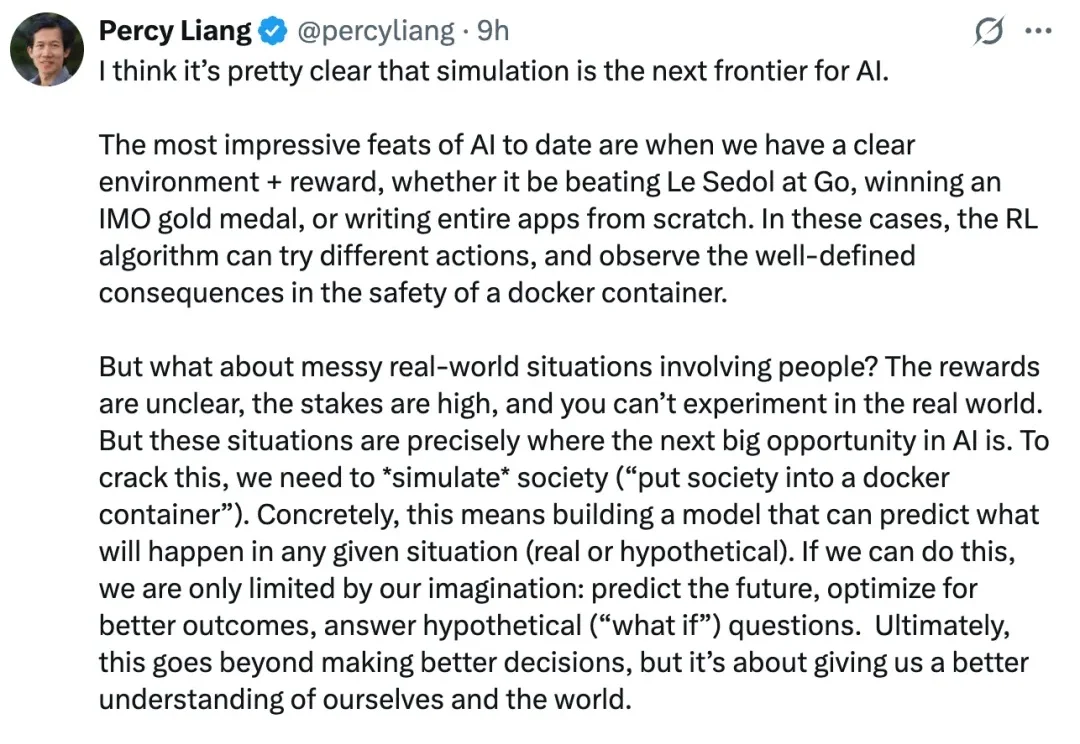
进入到 2026 年,人工智能领域被一只「龙虾」(OpenClaw)硬控了。这种具备高主动性、强活人感的私人 AI 助理成为了新一代人机交互的标杆。

生物研发进步提速长期受制于海量人工试错。恩和首发全球生物制造物理 AI 平台 SAION,打破 AI 仅限虚拟辅助的痛点。最大惊喜是它「长出了手脚」,能自主设计并直接调度设备执行真实实验,实现闭环进化!其生物科研表现全面超越 GPT 与斯坦福 Biomni,实现 SOTA。AI 科学家终于下场干活了!
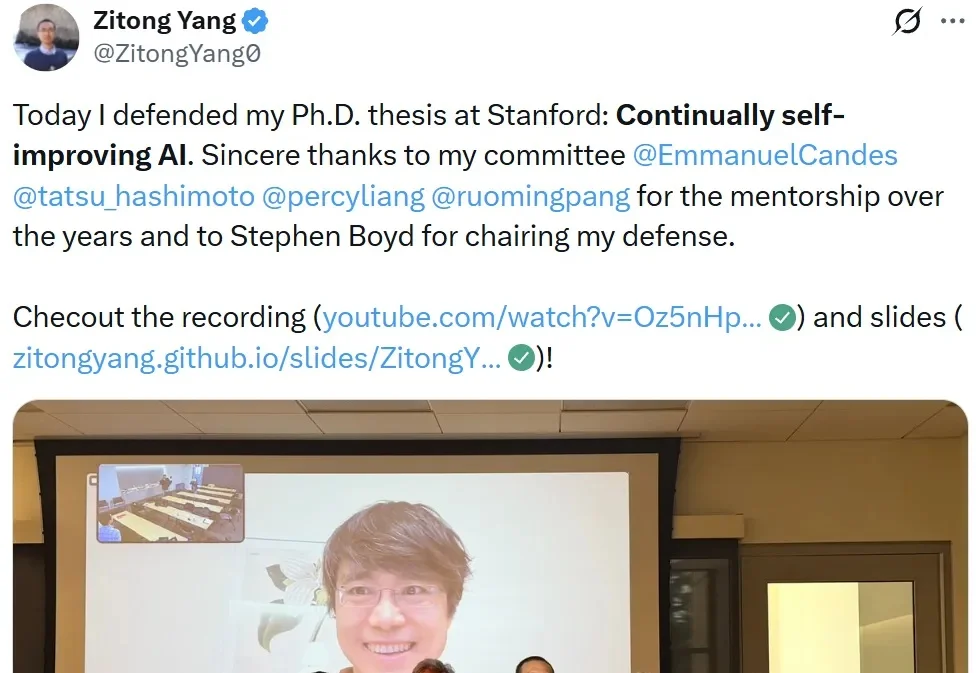
昨天,Thinking Maching Lab 研究者、斯坦福大学博士生 Zitong Yang 正式完成了他的博士论文答辩,课题为「持续自我提升式 AI」(Continually self-improving AI),并且他在答辩完成后很快就放出了自己的答辩视频,从中我们可以看到他对未来 AI 发展路径的系统性探索。
近日, Anthropic 和斯坦福研究者 Neil Rathi 与这位传奇研究者联合发布了一篇新论文,并得到了一些相当惊人的新发现。在这项研究中,他们挑战了当前大模型安全领域的一个核心假设。长期以来,业界普遍认为要在模型发布后通过 RLHF 或微调来限制其危险行为。但 Neil Rathi 和 Alec Radford 提出了一种更本质的解法:

机器之心编辑部 整个具身智能领域都在探索世界模型的实用化路径。这个被寄予厚望的「数字模拟器」,本应成为机器人训练的核心工具,却因物理保真度低等问题成为「空中楼阁」。 去年年中,谷歌发布了 Genie-
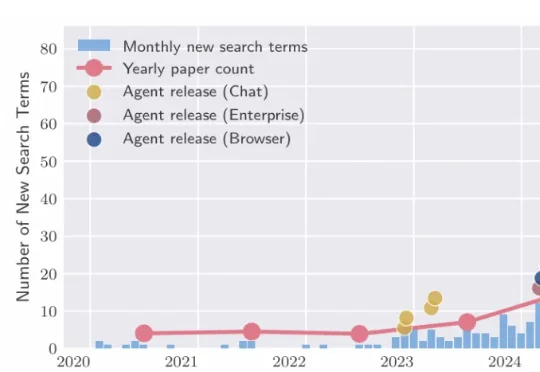
这两周,Claude Code 上了个 COBOL 现代化功能,IBM 当天暴跌 13%;又上了个安全扫描功能,一口气翻出 500 多个此前藏了几十年的高危漏洞,网安股集体跳水。彭博社甚至专门做了一期播客讨论“哪些 SaaS 公司能活下来”。

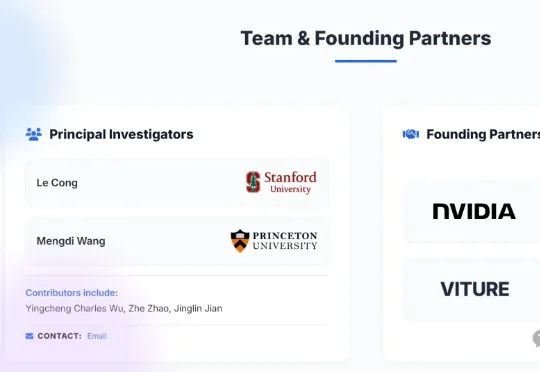
医疗AI终于走出了「只会聊天」的舒适区。今天,斯坦福与普林斯顿联手NVIDIA发布MedOS。这不是一个单纯的手术机器人,而是全球首个通用医疗具身世界模型。从临床诊断到治疗,从外科手术到药物研发,MedOS正在让AI真正读懂「生老病死」的物理现实。
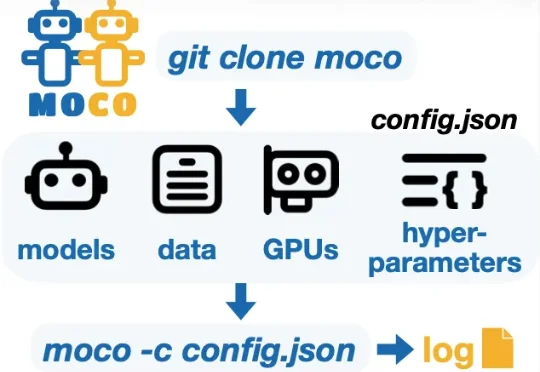
为了支持多模型协同研究并加速这一未来愿景的实现,华盛顿大学 (University of Washington) 冯尚彬团队联合斯坦福大学、哈佛大学等研究人员提出 MoCo—— 一个针对多模型协同研究的 Python 框架。MoCo 支持 26 种在不同层级实现多模型交互的算法,研究者可以灵活自定义数据集、模型以及硬件配置,比较不同算法,优化自身算法,以此构建组合式人工智能系统。MoCo 为设计、