
智谱与Anthropic是母凭子贵
智谱与Anthropic是母凭子贵Anthropic增加绿卡认证后,最开心是智谱,直接原地化身战狼,高呼「前沿智能属于所有人」,提前把专注Coding的GLM5.2发了。
来自主题: AI产品测评
8061 点击 2026-06-24 16:36
 搜索
搜索
Anthropic增加绿卡认证后,最开心是智谱,直接原地化身战狼,高呼「前沿智能属于所有人」,提前把专注Coding的GLM5.2发了。
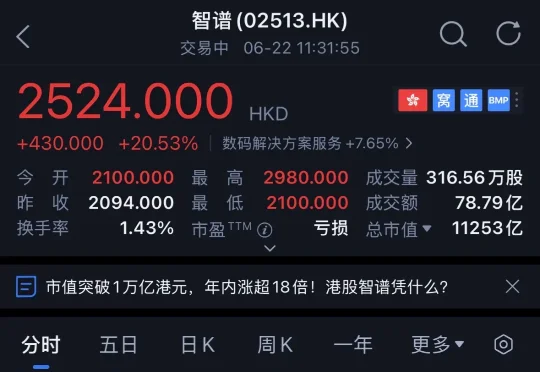
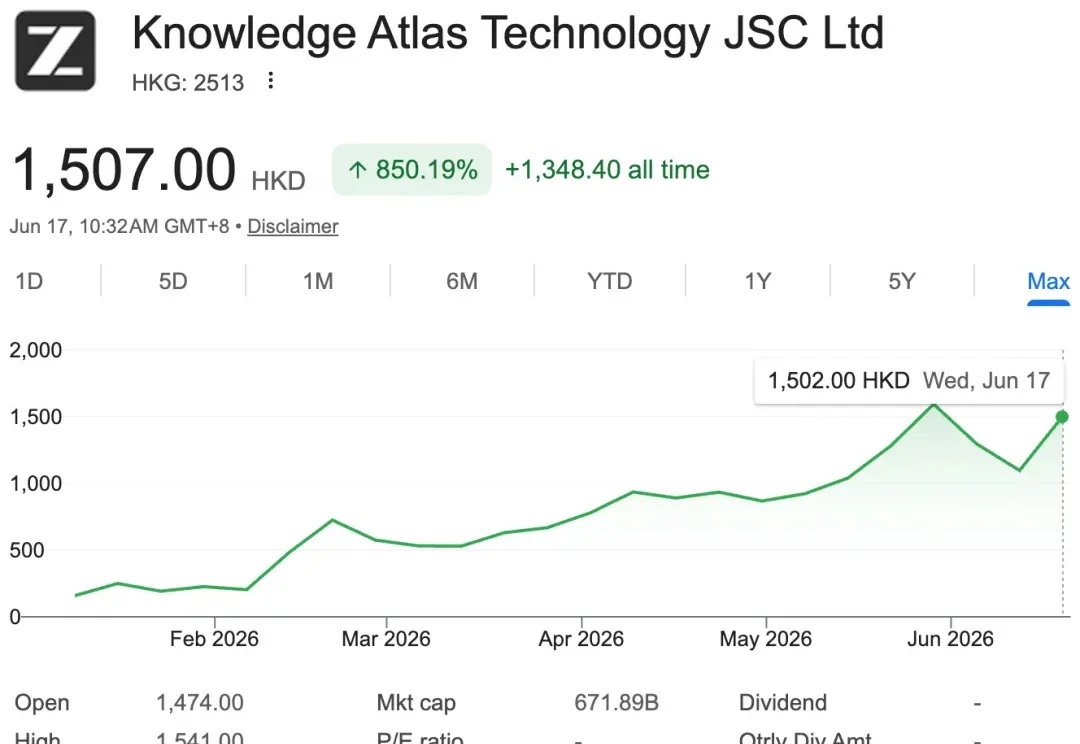
今日港股开盘后,智谱总市值首次突破1万亿港元,年内涨超2000%。截至今日11点31分,其股价为每股2524港元(约合人民币2181元),相比昨日收盘价上涨20.53%,总市值达到11253亿港元(约合人民币9722亿元)。
很多人认为这个数字不是随便挑的:美国政府向 Anthropic 下发出口管制指令、切断 Fable 5 与 Mythos 5 境外访问权限的那一刻,正是美国东部时间下午 5 点 21 分。「5 点 21」这个数字上的重复,被多家媒体解读为一次刻意设计的呼应。智谱选择在这个节点站出来,相当于当着全世界开发者的面说了一句话:你们担心的「模型随时可能被收回」,开源这边没有这个问题。

昨夜,全球最大的 AI 开源社区 Hugging Face 官宣了一项前所未有的决定:自掏腰包为智谱 AI 最新开源的旗舰模型 GLM-5.2 提供长达 6 小时的全球免费算力支持。这是 Hugging Face 第一次真金白银为国产模型开这种 “专属 VIP 通道”,海外网友纷纷直呼这波 “倒贴” 好!
前几天 Fable 5 对海外用户关停的时候,智谱突然宣布向 GLM Coding Plan 全量用户开放了 GLM-5.2,并表示「前沿智能不应只属于少数人,也不应被少数规则随手收回。」

这是葬AI起号以来工作量最大的一篇文章。为了严肃评测国产模型的能力,我自研了一个Benchmark,完整测试了智谱、Qwen、Kimi、Minimax、Deepseek这些最新国产模型,还引入了境外势力Claude作对照组。
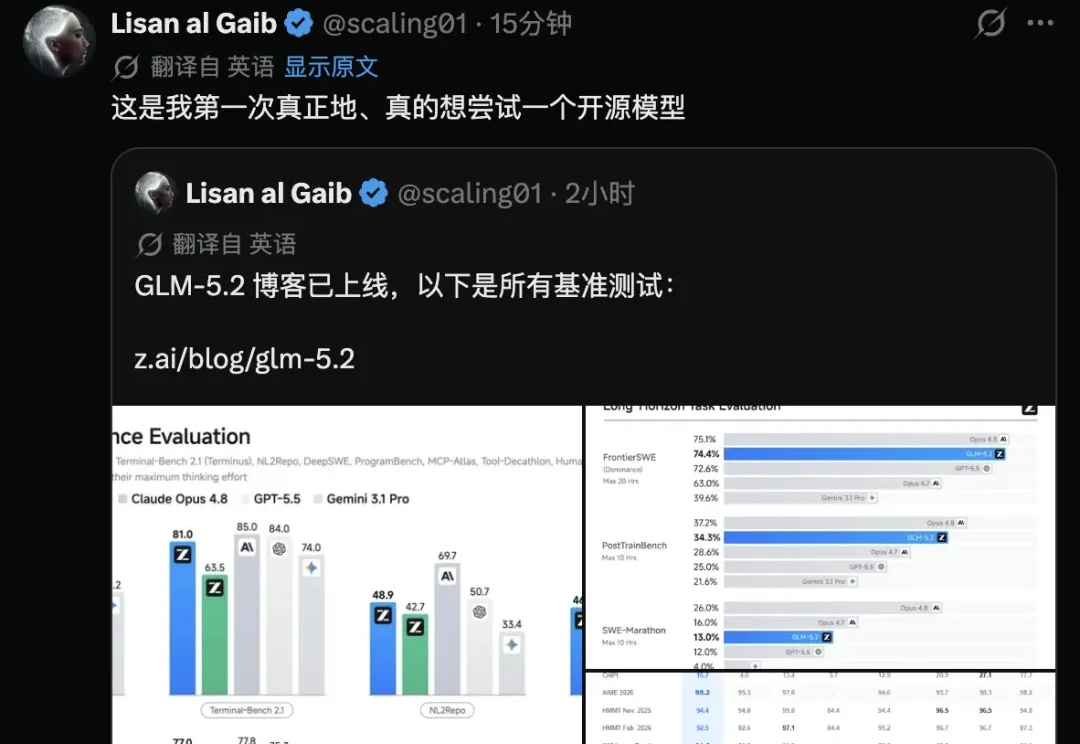
GLM-5.2 正式发布,震撼全网,主打长程任务能力,配合 1M token 上下文窗口,且完全开源(MIT 协议)。在相近的 token 消耗下,GLM-5.2 的能力大致介于 Opus 4.7 和 Opus 4.8 之间,参数仅为753B。

GLM-5.2 是智谱迄今能力最强的开源模型,支持真正可用的 1M 上下文,并在长程任务中继续保持领先。它也依旧是我们心中最强的国产 Coding 模型。

星源智,被视为“下一个智谱”。AI 科技评论独家获悉,具身智能大脑公司星源智机器人(以下简称“星源智”)已完成新一轮融资。至此,这家成立仅10个月的公司累计融资金额已达10亿元人民币。

80%募资金额拟用于基座大模型研发。