
机器人终于不瞎抓了!港大阿里联手开源FineVLA:用哪只手、抓哪里,一句话全搞定
机器人终于不瞎抓了!港大阿里联手开源FineVLA:用哪只手、抓哪里,一句话全搞定机器人模型已经能根据“把杯子放进篮子”这类指令完成任务,但用哪只手?
来自主题: AI技术研报
7112 点击 2026-06-23 15:02
 搜索
搜索
机器人模型已经能根据“把杯子放进篮子”这类指令完成任务,但用哪只手?

近日,AI-Native科技潮玩品牌ZuzuZoos查无此园宣布完成数千万元Pre-A轮融资,由锦秋基金领投、上海复容投资跟投。这家成立于2025年的初创公司,定位于"AI陪伴机器人+AI潮玩"方向,试图将情感陪伴、AI交互与潮玩IP结合,打造一款会拥抱人的便携式AI伙伴。

机器狗去买咖啡,轮椅跟人抬杠:清华现场0遥操、全靠现挂。完全没有剧本,在清华现场,这群机器人直接把物理AGI第一幕演活了!
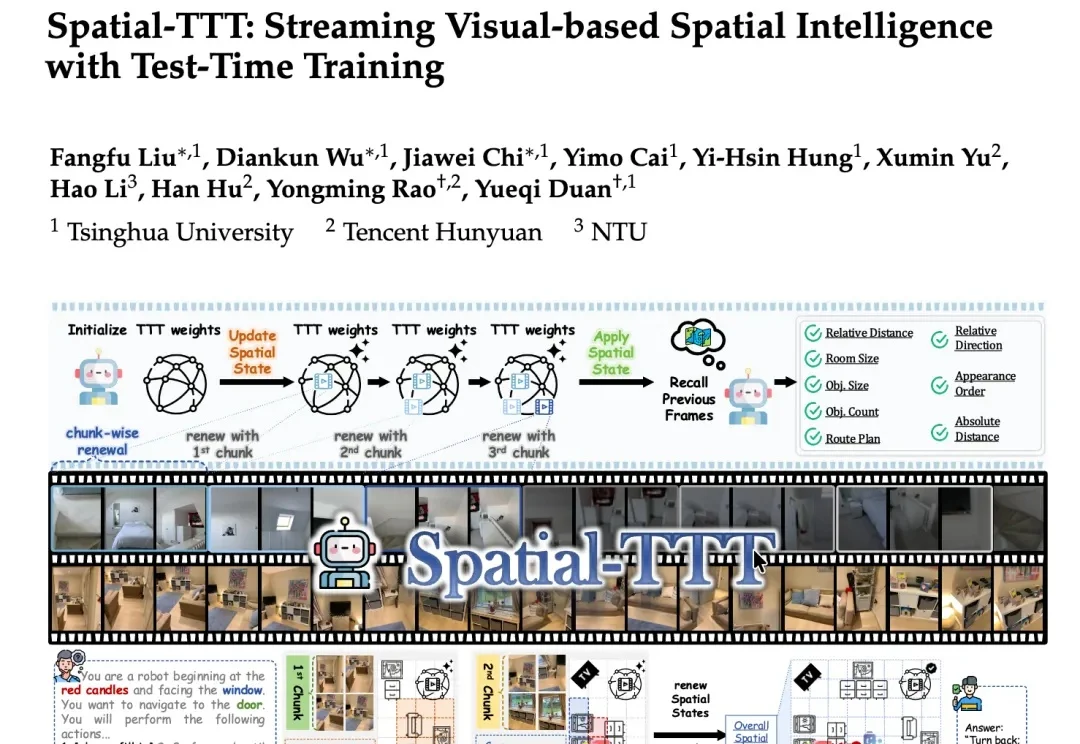
在机器人、自动驾驶、AR等真实场景中,空间理解从来都不是“看一眼图像”就能解决的问题。
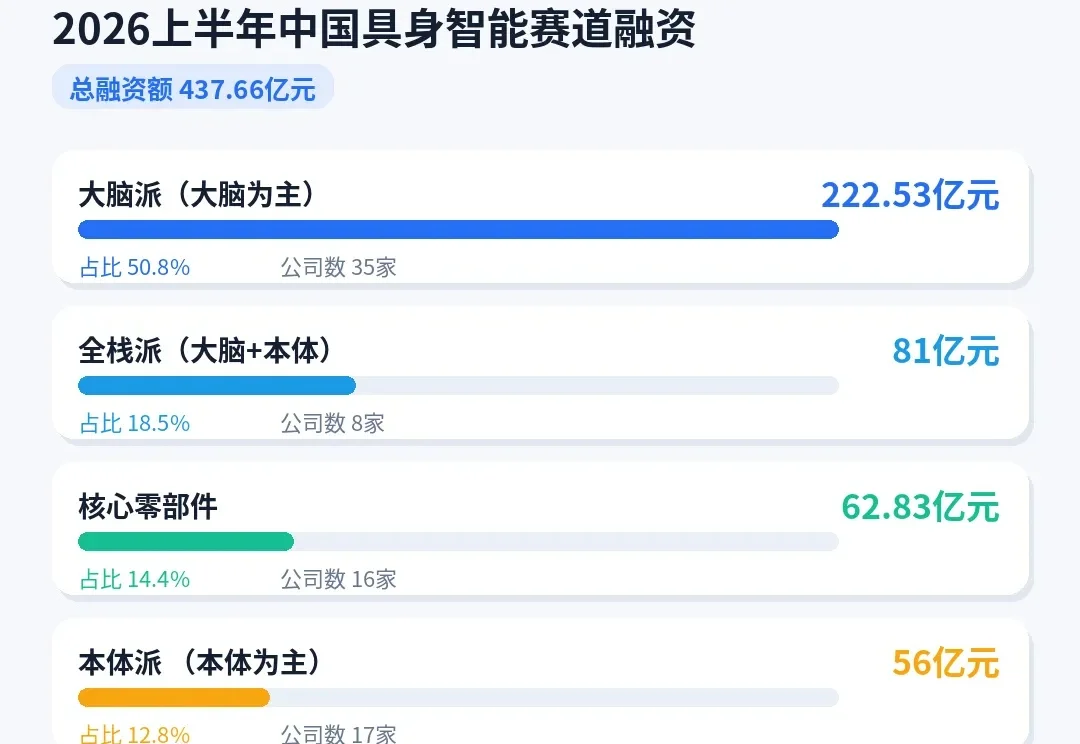
具身智能领域的资本,正在涌向机器人的“大脑”。
硬氪获悉,AI厨房机器人品牌「栗上LISSOME」(以下简称“栗上”)近日完成数千万元人民币A轮融资。本轮融资由红杉中国、Brizan Ventures领投,老股东及HKX等机构跟投。此前,栗上已累计获得来自李泽湘教授的清水湾基金、高秉强教授、挑战者资本、高锋耐心资本、XbotPark宁波基地等机构的数千万元融资。

2011 年,Judea Pearl 凭借在因果推理领域的奠基性贡献获得图灵奖。他提出AI必须跨越三层:关联、干预、反事实。2018 年,他在面向大众的著作《The Book of Why》中将这一框架系统化为“因果之梯”。

银河通用团队用史上最大、整整 20 亿帧的动捕数据,训练出了全球首个人形机器人全身实时运控基座大模型,该模型零样本泛化全新动作,成功率从 MLP 架构的 76.89% 跃至 92.58%,推理延迟仅 0.39ms,效果超越英伟达 SONIC,甚至比目前业内主流 TWIST 系统速度提升至五倍。

让人形机器人在移动中完成精细操作,一直是具身智能领域没有被很好解决的问题。

自动化研究,这一次真正走出代码沙盒,进入了真实的物理世界。