
300多篇相关研究,复旦、南洋理工最新多模态图像编辑综述论文
300多篇相关研究,复旦、南洋理工最新多模态图像编辑综述论文本文提出了解决一般性编辑任务的统一框架!近期,复旦大学 FVL 实验室和南洋理工大学的研究人员对于多模态引导的基于文生图大模型的图像编辑算法进行了总结和回顾。综述涵盖 300 多篇相关研究,调研的最新模型截止至今年 6 月!
来自主题: AI技术研报
9140 点击 2024-06-29 00:35
 搜索
搜索
本文提出了解决一般性编辑任务的统一框架!近期,复旦大学 FVL 实验室和南洋理工大学的研究人员对于多模态引导的基于文生图大模型的图像编辑算法进行了总结和回顾。综述涵盖 300 多篇相关研究,调研的最新模型截止至今年 6 月!

上下文学习 (in-context learning, 简写为 ICL) 已经在很多 LLM 有关的应用中展现了强大的能力,但是对其理论的分析仍然比较有限。人们依然试图理解为什么基于 Transformer 架构的 LLM 可以展现出 ICL 的能力。
日前,旷视科技发布了一项新的开源 AI 人像视频生成框架 ——MegActor。基于该框架,用户只需输入一张静态的肖像图片,以及一段视频(演讲、表情包、rap)文件,即可生成一段表情丰富、动作一致的 AI 人像视频。
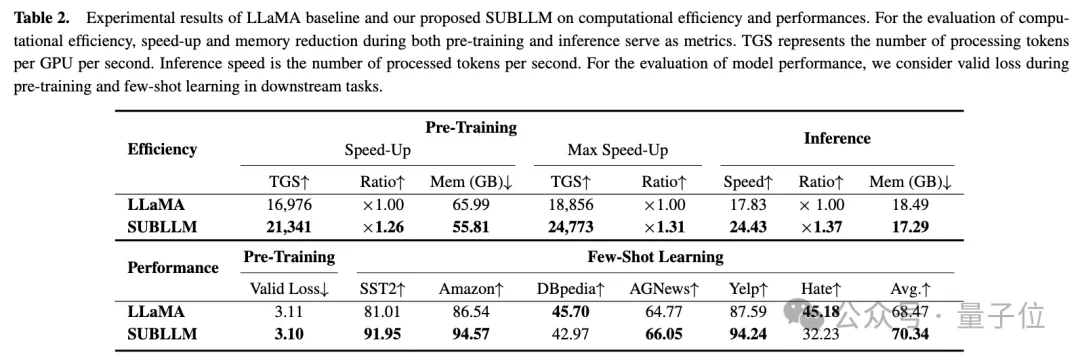
大模型推理速度提升50%以上,还能保证少样本学习性能!
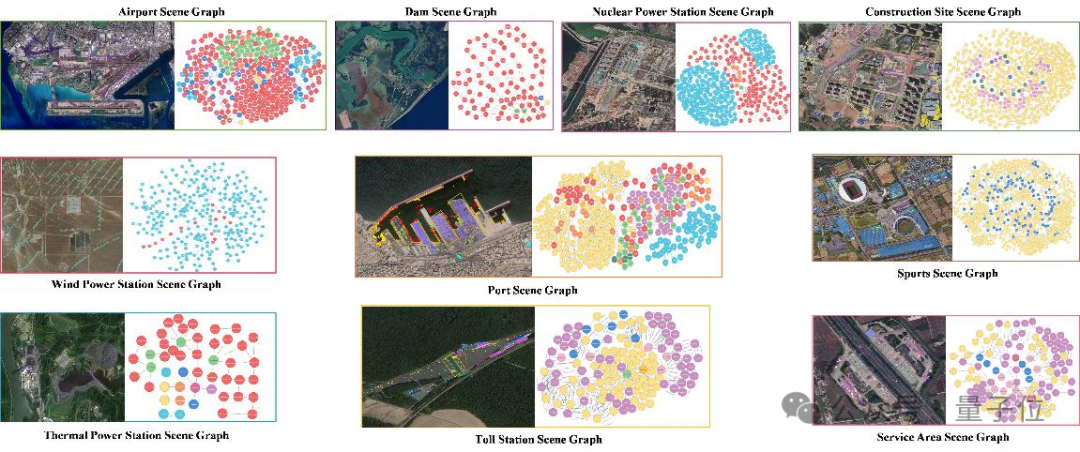
AI卫星影像知识生成模型数据集稀缺的问题,又有新解了。
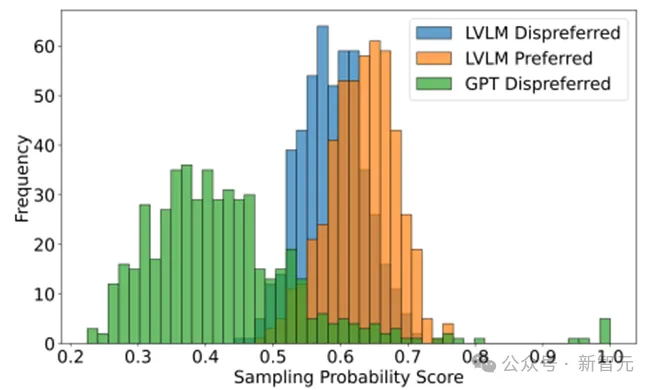
现有多模态大模型在对齐不同模态时面临幻觉和细粒度感知不足等问题,传统偏好学习方法依赖可能不适配的外源数据,存在成本和质量问题。Calibrated Self-Rewarding(CSR)框架通过自我增强学习,利用模型自身输出构造更可靠的偏好数据,结合视觉约束提高学习效率和准确性。
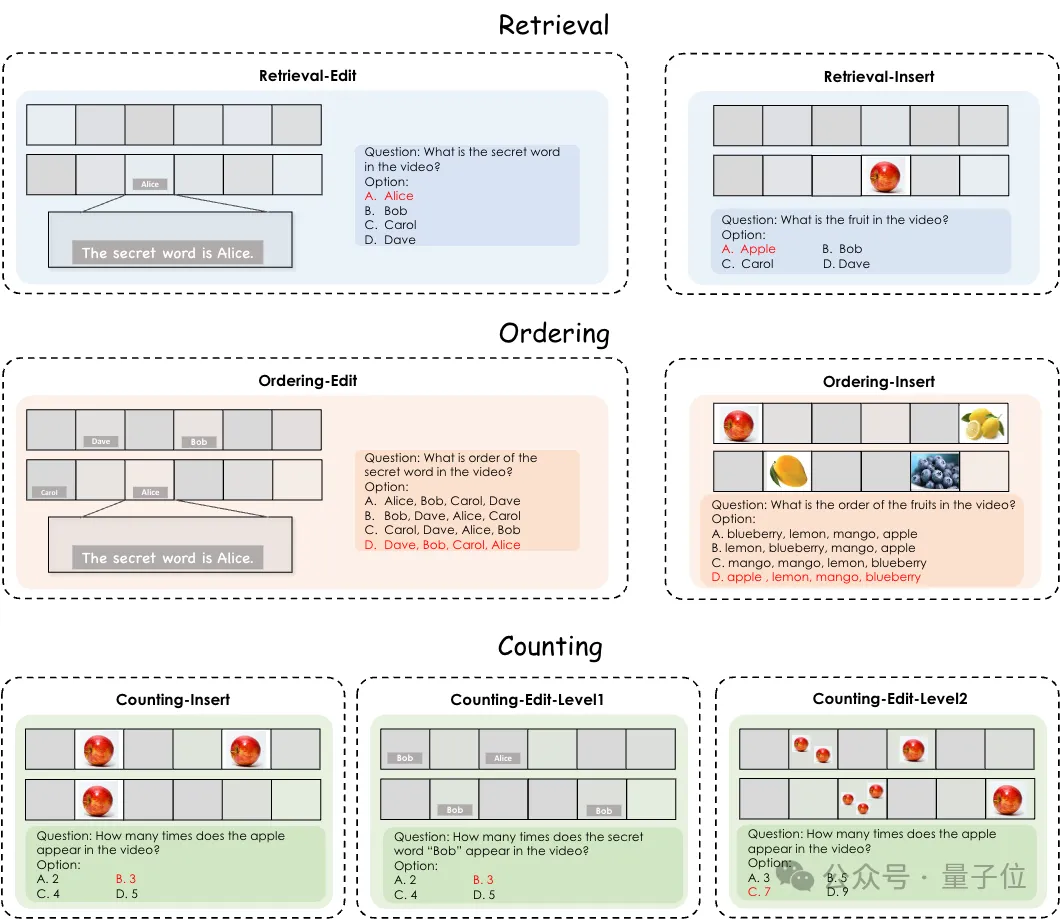
测试Gemini1.5 Pro、GPT-4o等多模态大模型的新基准来了,针对视频理解能力的那种。
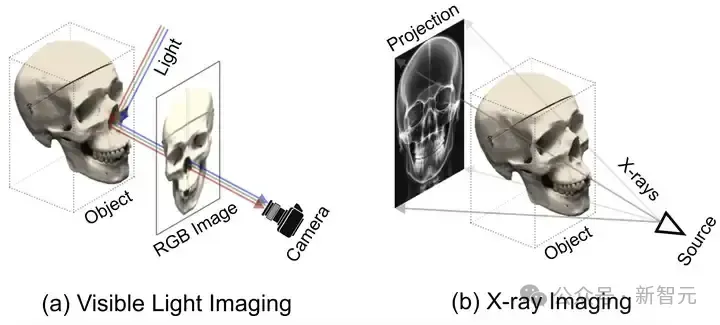
SAX-NeRF框架,一种专为稀疏视角下X光三维重建设计的新型NeRF方法,通过Lineformer Transformer和MLG采样策略显著提升了新视角合成和CT重建的性能。研究者还建立了X3D数据集,并开源了代码和预训练模型,为X光三维重建领域的研究提供了宝贵的资源和工具。

本⽂介绍由清华等⾼校联合推出的⾸个开源的⼤模型⽔印⼯具包 MarkLLM。MarkLLM 提供了统⼀的⼤模型⽔印算法实现框架、直观的⽔印算法机制可视化⽅案以及系统性的评估模块,旨在⽀持研究⼈员⽅便地实验、理解和评估最新的⽔印技术进展。通过 MarkLLM,作者期望在给研究者提供便利的同时加深公众对⼤模型⽔印技术的认知,推动该领域的共识形成,进⽽促进相关研究的发展和推⼴应⽤。

如何生成高难度、指令超复杂的视频呢?