UniPat AI开源SWE-Vision:五百行代码打造SOTA视觉智能体!
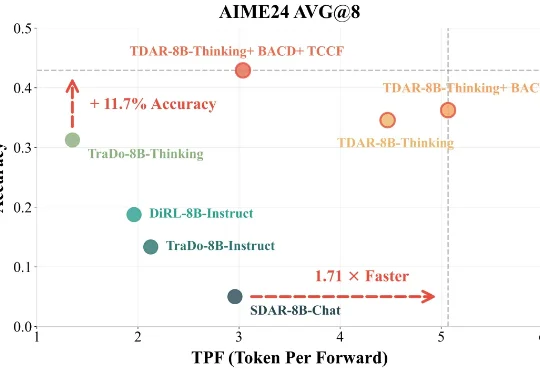
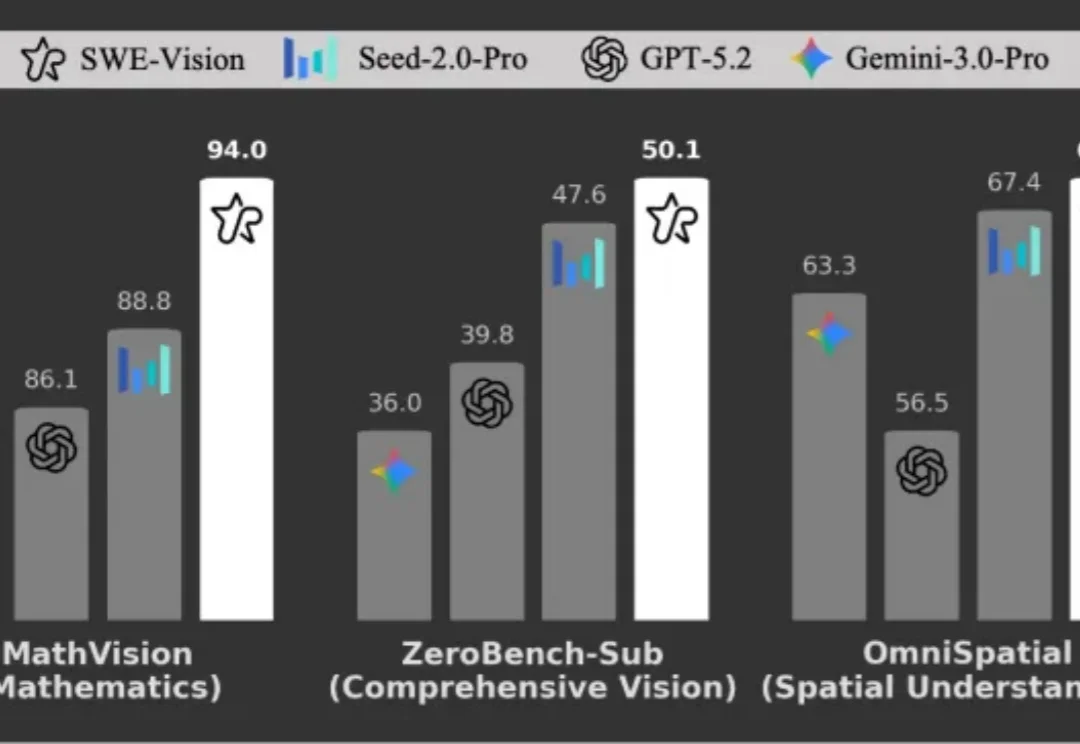
UniPat AI开源SWE-Vision:五百行代码打造SOTA视觉智能体!多模态大模型在代码能力上进步惊人,但在基础视觉任务上却频繁失误。UniPat AI 构建了一个极简的视觉智能体框架 ——SWE-Vision,让模型可以编写并执行 Python 代码来处理和验证自己的视觉判断。在五个主流视觉基准测试中,SWE-Vision 均达到了当前最优水平。
来自主题: AI技术研报
9605 点击 2026-03-16 14:25