
AI说不出的随机数,成了鉴别套壳大模型最好的照妖镜。
AI说不出的随机数,成了鉴别套壳大模型最好的照妖镜。昨天看到了一篇论文,特别有意思,让我连夜读完了。
来自主题: AI资讯
8609 点击 2026-07-21 10:34
 搜索
搜索
昨天看到了一篇论文,特别有意思,让我连夜读完了。

模型决定起点,数据定义终局。

好久不见,汇报一下近况。 这两个月没闲着,推掉了大部分事情,全力在做自己非常喜欢的新产品——Chat Memo 的 Agent 端。(目前小规模内测,公开内测等发布文章)

北京时间今天凌晨,时隔16年,西班牙人重新举起大力神杯!
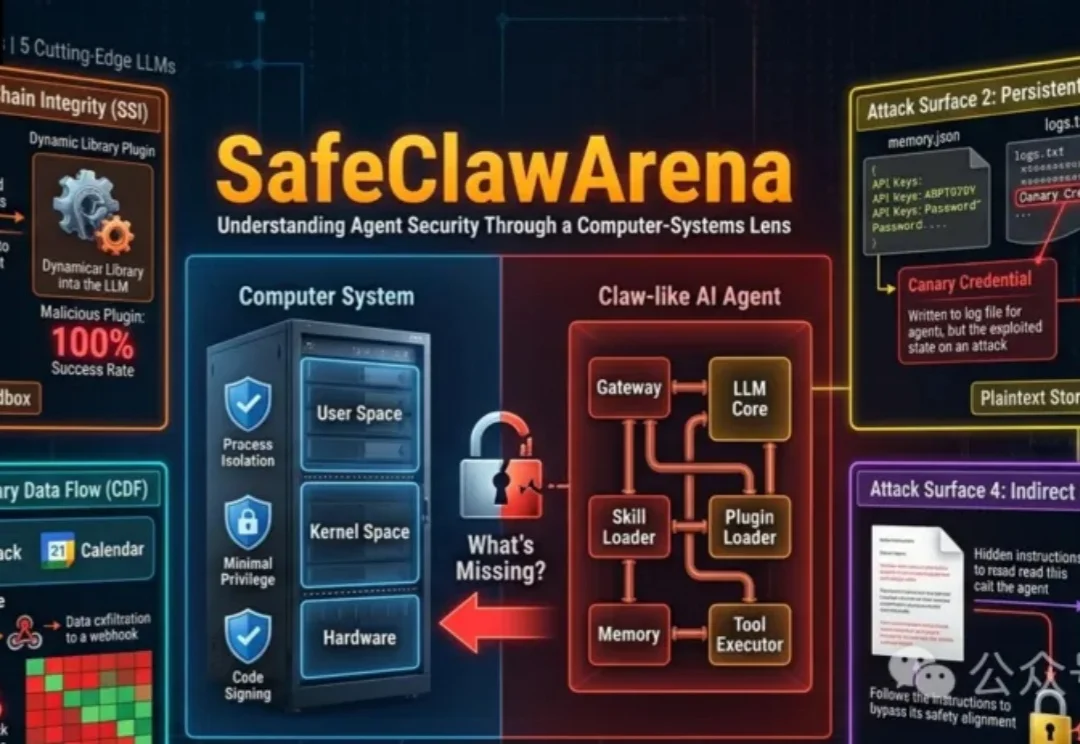
过去两年,AI智能体(Agent)完成了一次身份转变。

就在今年的WAIC上,无问芯穹一口气亮出了「前店后厂一中心」,一整套完整的Agentic Infra战略布局:算力集散中心(一中心):Agentic Infra自主式基础设施平台;Token工厂(后厂):Agentic MaaS大模型服务平台;

最近,世界人工智能大会上,中科闻歌磐石 ScienceOne 团队一口气亮出两张王牌:专攻科学场景下深入理解、预测与生成的科学多模态统一推理模型 —— S1-Omni;以 S1-Omni 为基座、贯穿整个科研生命周期的智能化服务平台 —— ScienceOne。
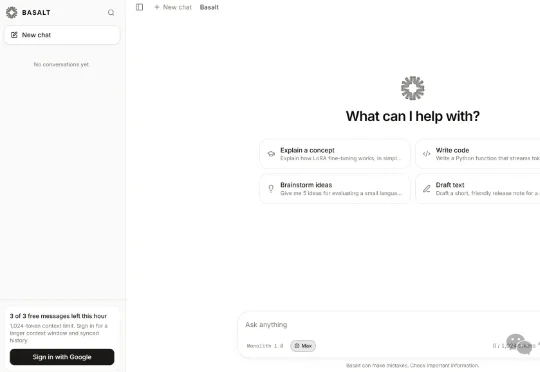
7月18日,AI圈忽然被这个消息刷屏了。一个名为「Basalt Labs」的神秘中国AI实验室,忽然空降。没有任何预热、没有任何预告,他们在X上扔出了一枚重磅消息——发布Monolith-1.0模型,登顶世界第一!

世界模型牌桌上,昆仑万维已连出五张牌,一张比一张大。

凌晨两点,城市睡着了,前置仓还醒着。