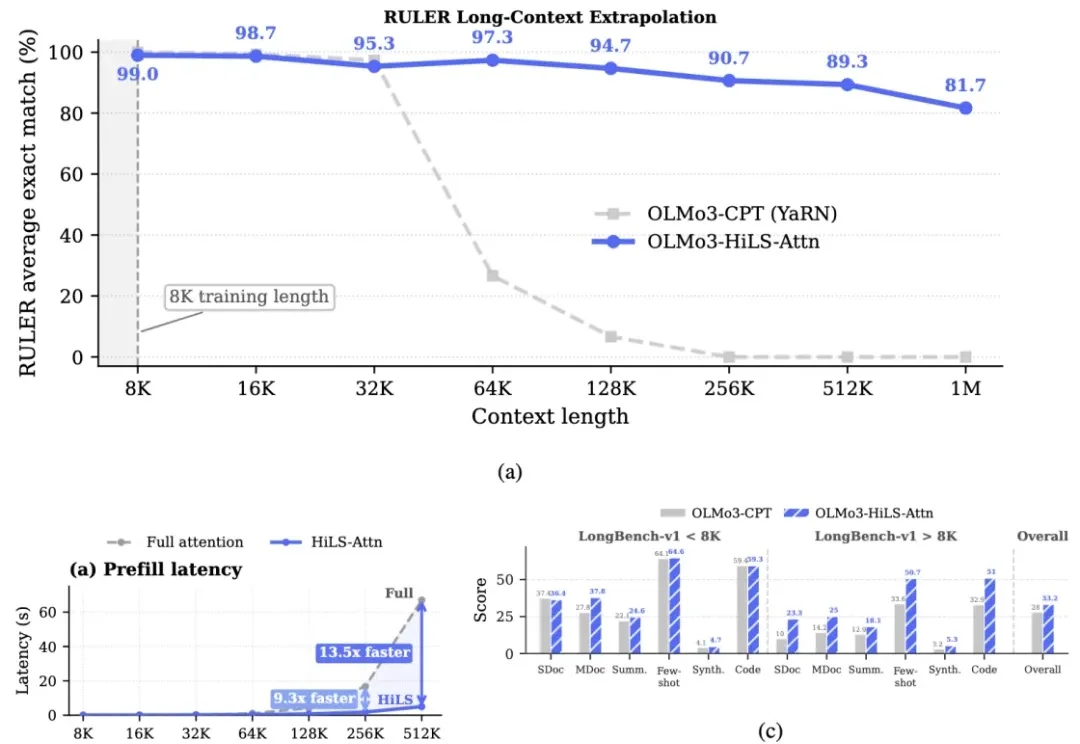
在数学上把稀疏注意力做对!腾讯Hy开源HiLS-Attention: 计算更少效果更好, 外推512倍
在数学上把稀疏注意力做对!腾讯Hy开源HiLS-Attention: 计算更少效果更好, 外推512倍让大模型 "读得更长" 一直是 Agent、深度推理和海量资料整合等场景的刚需,但标准全注意力机制的计算量随序列长度呈平方级增长,始终是横亘在长上下文建模面前的三座大山。
来自主题: AI技术研报
9104 点击 2026-07-20 15:19
 搜索
搜索
让大模型 "读得更长" 一直是 Agent、深度推理和海量资料整合等场景的刚需,但标准全注意力机制的计算量随序列长度呈平方级增长,始终是横亘在长上下文建模面前的三座大山。

如果你走进2026 WAIC的现场,最直观的感受可能只有一个“卷”字。

在计算历史的绝大部分时间里,编程的本质是一项翻译工作:开发者需要在人类理解的维度上剖析问题,设计抽象方案,随后将其转译为机器能够执行的语法。当前的软件工程领域正在经历自高级编程语言问世以来最为显著的变化。

让大模型给一张图片打“质量分”,它其实经常看走眼。

“芯片的定价权越强,模型和应用公司的成本刚性就越难消解。” 当下,仅豆包一家大模型的日均Token调用量就已突破180万亿;国家数据局的统计显示,全国日均调用量在今年3月已超过140万亿——无论从哪个口径衡量,这都是一条两年内从“近乎为零”飙涨超千倍的曲线。
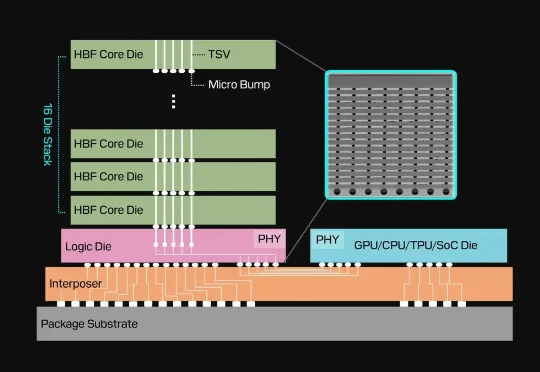
IEEE最新刊发了一条挺反常识的新思路:大模型的内存焦虑,可能要靠U盘里的同款技术来缓解了。没错,就是NAND Flash。但现在,SanDisk和SK海力士正在推动一种新东西:High Bandwidth Flash(高带宽闪存),简称HBF。

AI体育赛道今年迎来了一波明星资本的押注。

人工智能(AI)模型在科学发现中的角色,正经历着一场从「工程缝合者」向「智能推演者」的深刻蜕变。
过去一年,Deep Research Agent 被视为大模型落地的下一个突破口,它们会检索、能用工具、可多步推理,在一个个榜单上高歌猛进。但把它们放到真实世界的专业场景里,表现是否也同样亮眼?

市面上已有几十种Agent记忆方案,有的基于向量检索,有的基于知识图谱,有的靠定期总结“压缩”对话,有的则完全依赖模型自身的上下文窗口。它们各有各的说法,但在系统层面,到底哪种方案靠得住?哪种方案在你的工作负载下既不贵又准?