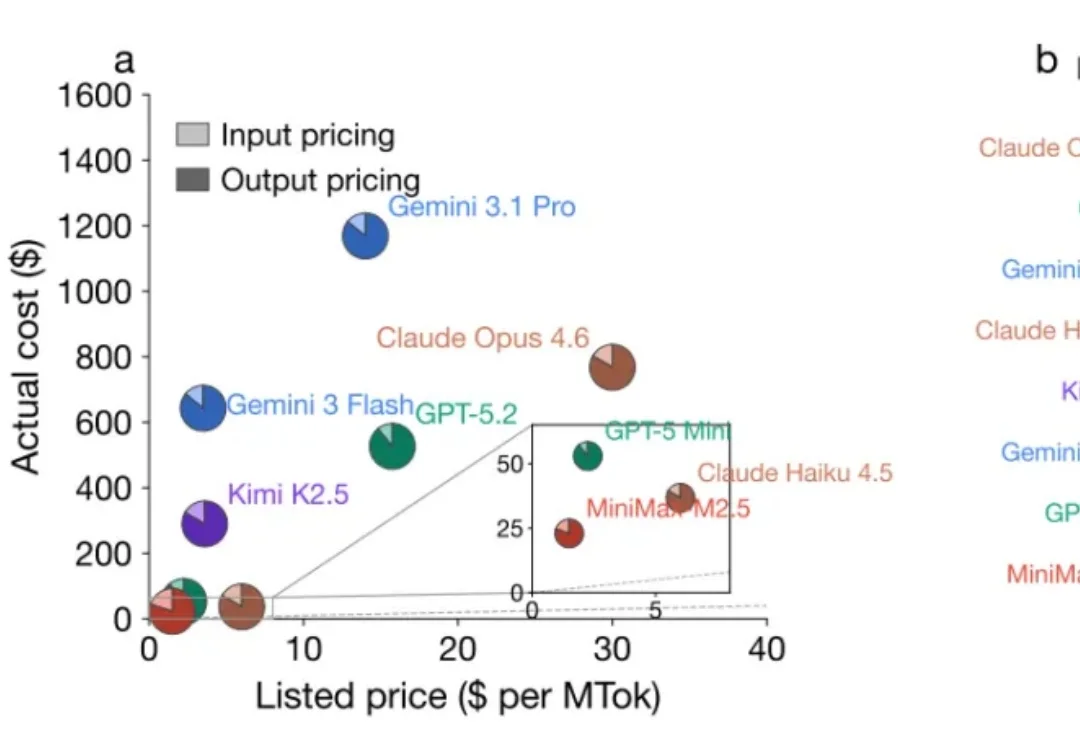
警惕!大模型成本倒挂:你正在为模型的多余「思考」买单
警惕!大模型成本倒挂:你正在为模型的多余「思考」买单在选择使用大模型 (LLM) 时,除了模型性能强弱,价格也是一个重要指标。人们通常会用大模型的 API 定价更贵或更便宜,来比较模型的价格高低。但事实上,定价低的模型真的比定价高的模型使用起来更便宜吗?
来自主题: AI技术研报
6498 点击 2026-04-15 09:45
 搜索
搜索
在选择使用大模型 (LLM) 时,除了模型性能强弱,价格也是一个重要指标。人们通常会用大模型的 API 定价更贵或更便宜,来比较模型的价格高低。但事实上,定价低的模型真的比定价高的模型使用起来更便宜吗?

刚刚,上海大模型独角兽MiniMax,正式通过港交所聆讯,吹响了IPO冲刺号角。但直到招股书披露,更重要的资本吸引力原因才完全明确——不仅因为全模态能力全球领先,更关键的是,累计花费只用了5亿美元,不到OpenAI的1%。
就在刚刚,在Create 2025百度AI开发者大会上,李彦宏又一口气官宣了两款新模型:分别是主打深度思考和多模态的X1 Turbo/4.5 Turbo。据介绍,它们是百度在3月发布的旗舰模型X1、4.5的升级版,推理和多模态能力双双更跃Level。

在刚刚成立的一年多时间里,DeepSeek一直不声不响,V2模型的发布成为其破圈的关键。由于模型结构层面的突破性创新,使得其将模型成本大大降低,也被业内戏称为AI届拼多多。这之后,DeepSeek也真正引发了硅谷的恐慌,OpenAI正迎来一个最强劲的对手。

本次量子位MEET 2025智能未来大会上,智谱COO张帆热情分享了智谱大模型的发展、应用、商业化发展、未来方向,以及企业和个人的科技战略构建。

如何将这个应用到你的实际营销中可能成效并不明显,但一个值得注意的变化是模型成本的贬值。你可能没有意识到,AI是有史以来折旧速度最快的技术。

探索数推分离,降低大模型成本,提高效率。

Meta的开源大模型Llama 3在市场上遇冷,进一步加剧了大模型开源与闭源之争的关注热度。

DeepMind最近被ICML 2024接收的一篇论文,完完全全暴露了他们背靠谷歌的「豪横」。一篇文章预估了这项研究所需的算力和成本,大概是Llama 3预训练的15%,耗费资金可达12.9M美元。

随着竞争压力加大,开发AI模型成本上升,越来越多的AI初创公司考虑对外出售。