vLLM团队官宣创业:融资1.5亿美元,清华特奖游凯超成为联创
vLLM团队官宣创业:融资1.5亿美元,清华特奖游凯超成为联创大模型推理的基石 vLLM,现在成为创业公司了。
来自主题: AI资讯
7465 点击 2026-01-23 11:24
 搜索
搜索
大模型推理的基石 vLLM,现在成为创业公司了。
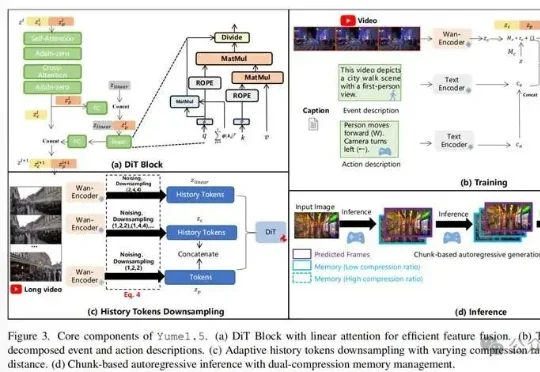
上海AI Lab联合多家机构开源的Yume1.5,针对这一核心难题提出了时空信道联合建模(TSCM),在长视频生成中实现了近似恒定计算成本的全局记忆访问。

“与AGI太过遥远的炒作相比,我非常喜欢这种 3 到 5 年的时间窗口。”“AI 现在最大的问题,已经不是不够聪明,而是太难真正落地。”这些非常务实的观点,并不是出自AI怀疑论者。相反,它出自硅谷圈内那位“工程与学术”的双修神话:

扩散语言模型(Diffusion Language Models)以其独特的 “全局规划” 与并行解码能力广为人知,成为 LLM 领域的全新范式之一。然而在 Any-order 解码模式下,其通常面临
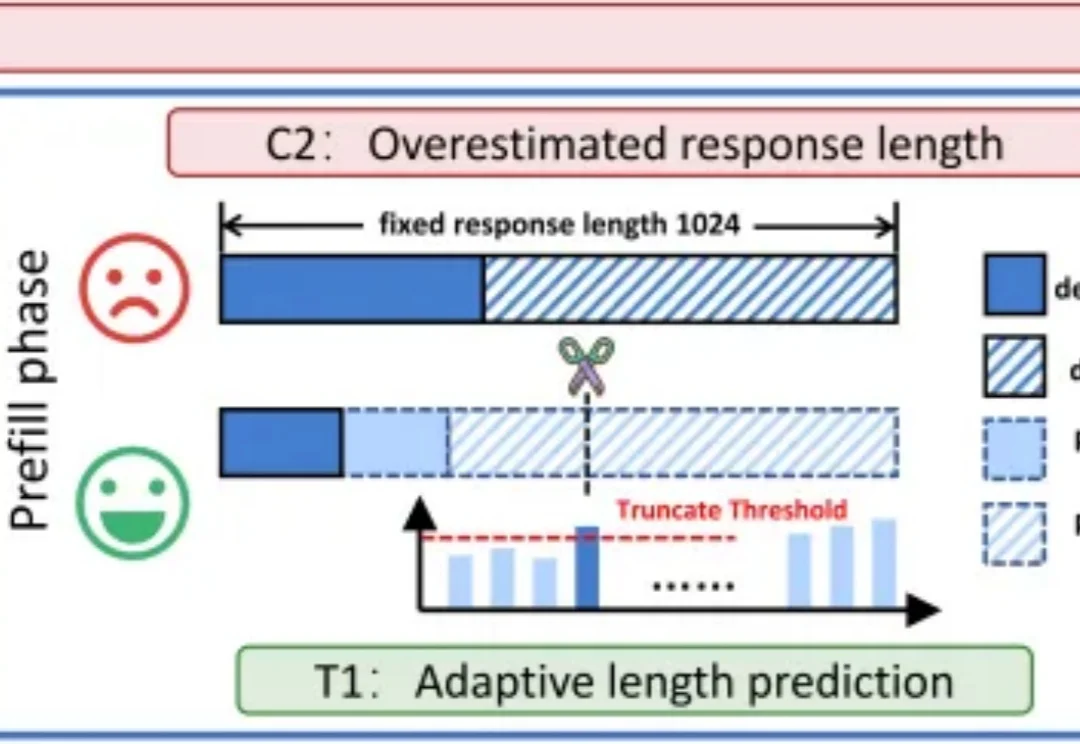
基于扩散的大语言模型 (dLLM) 凭借全局解码和双向注意力机制解锁了原生的并行解码和受控生成的潜力,最近吸引了广泛的关注。例如 Fast-dLLM 的现有推理框架通过分块半自回归解码进一步实现了 dLLM 对 KV cache 的支持,挑战了传统自回归 LLMs 的统治地位。

大模型推理的爆发,实际源于 scaling 范式的转变:从 train-time scaling 到 test-time scaling(TTS),即将更多的算力消耗部署在 inference 阶段。典型的实现是以 DeepSeek r1 为代表的 long CoT 方法:通过增加思维链的长度来获得答案精度的提升。那么 long CoT 是 TTS 的唯一实现吗?

扩散概率生成模型(Diffusion Models)已成为AIGC时代的重要基础,但其推理速度慢、训练与推理之间的差异大,以及优化困难,始终是制约其广泛应用的关键问题。近日,被NeurIPS 2025接收的一篇重磅论文EVODiff给出了全新解法:来自华南理工大学曾德炉教授「统计推断,数据科学与人工智能」研究团队跳出了传统的数值求解思维,首次从信息感知的推理视角,将去噪过程重构为实时熵减优化问题。

就在一周前,全宇宙最火爆的推理框架 SGLang 官宣支持了 Diffusion 模型,好评如潮。团队成员将原本在大语言模型推理中表现突出的高性能调度与内核优化,扩展到图像与视频扩散模型上,相较于先前的视频和图像生成框架,速度提升最高可达 57%:
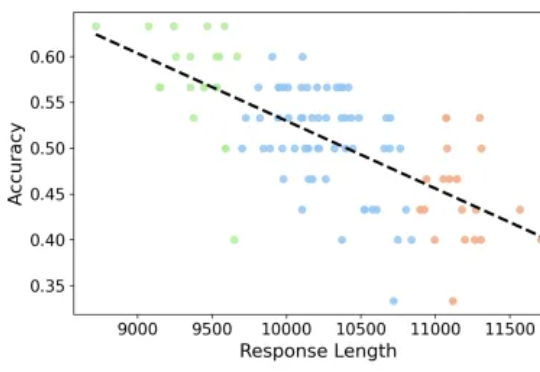
专注推理任务的 Large Reasoning Models 在数学基准上不断取得突破,但也带来了一个重要问题:越想越长、越长越错。本文解读由 JHU、UNC Charlotte 等机构团队的最新工作
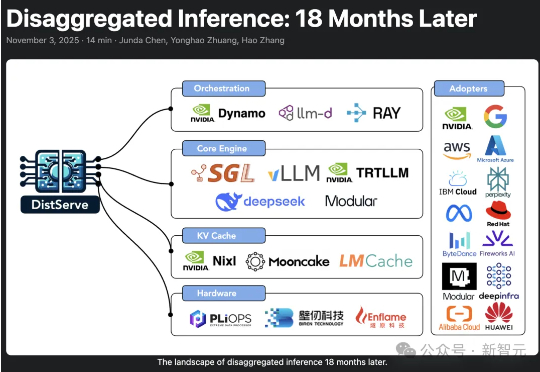
2024年,加州大学圣地亚哥分校「Hao AI Lab」提出了DistServe的解耦推理理念,短短一年多时间,迅速从实验室概念成长为行业标准,被NVIDIA、vLLM等主流大模型推理框架采用,预示着AI正迈向「模块化智能」的新时代。