
小模型用不好Skill?新范式SKILL0让模型学会Skill的底层逻辑,3B模型推理token省5倍
小模型用不好Skill?新范式SKILL0让模型学会Skill的底层逻辑,3B模型推理token省5倍浙江大学联合美团龙猫团队、清华大学推出全新研究成果——SKILL0,并提出技能内化(Skill Internalization)——小模型真正需要的,或许不是推理时的“外挂技能”,而是将技能内化为本能。
来自主题: AI技术研报
8885 点击 2026-04-12 11:56
 搜索
搜索
浙江大学联合美团龙猫团队、清华大学推出全新研究成果——SKILL0,并提出技能内化(Skill Internalization)——小模型真正需要的,或许不是推理时的“外挂技能”,而是将技能内化为本能。
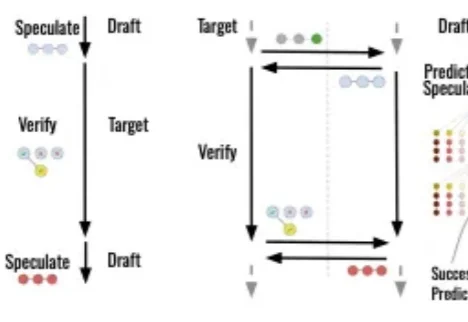
在大语言模型推理领域,虽然「推测解码」(Speculative Decoding,SD)已成为加速生成的标准配置,但它依然存在一个致命弱点: drafting(草拟)和 verification(验证)之间必须串行进行。
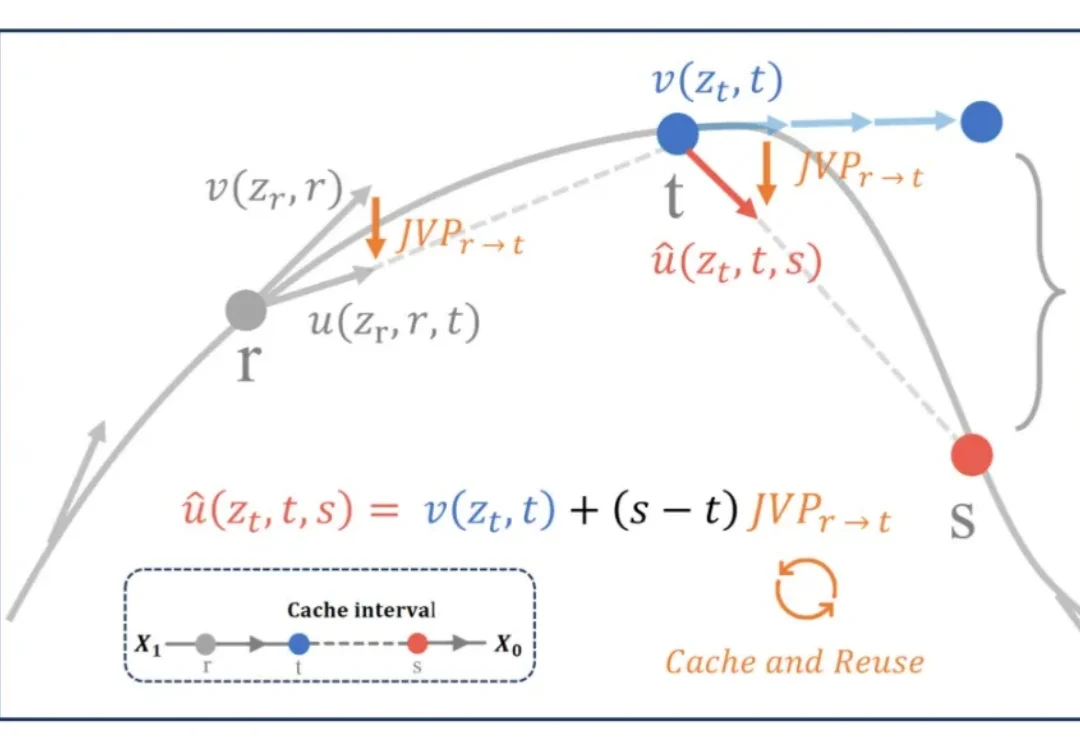
FLUX 、Qwen-Image 等多模态生成模型的推理速度一直是工业级多模态模型落地的痛点。传统的特征缓存(Feature Caching)方案在追求高倍率加速时,常因瞬时速度的剧烈波动导致轨迹漂移。
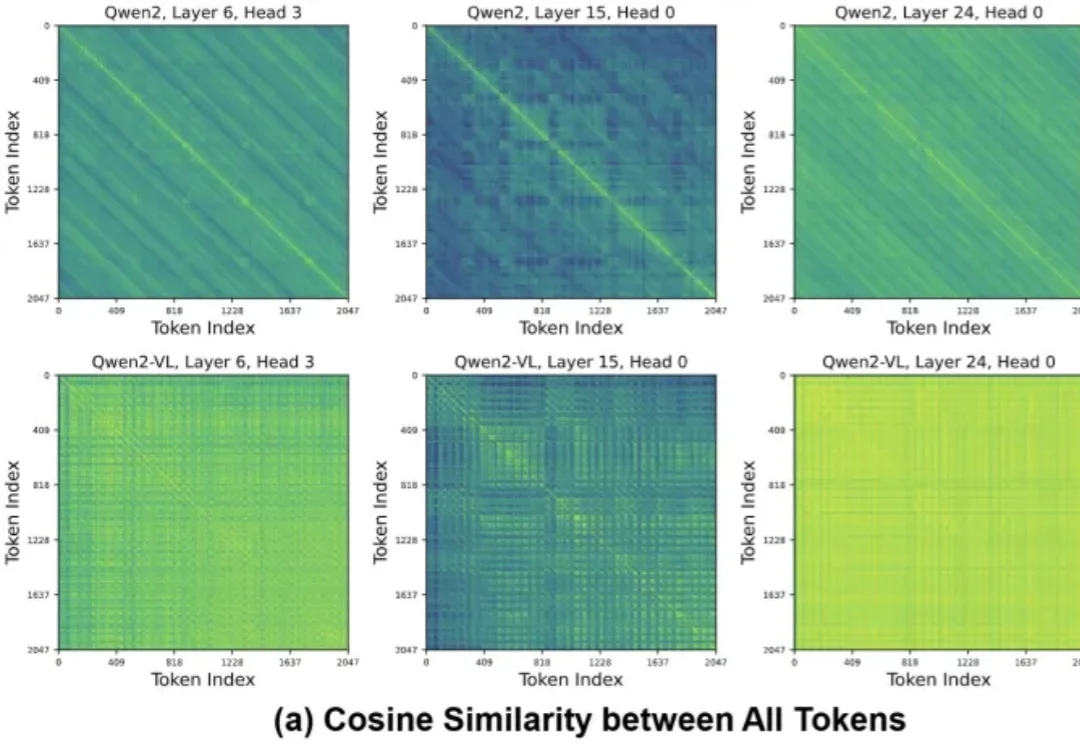
长上下文推理已经成了VLM/LLM的默认形态。

2亿美元A轮融资,估值110亿,成立仅一年就成为独角兽。更震撼的是创始人——25岁的广州00后洪乐潼,父母是从未上过大学的普通务工者。她用数学解决AI最大的痛点:让模型推理步步可验证,彻底杜绝幻觉。为了加入她,弗吉尼亚大学终身教授直接辞职。
《读佳》获悉,百度投资了一家专门做智能多模型推理的平台“AnyInt”,主体公司为上海宏诺伊曼科技有限公司(下简称“宏诺伊曼科技”),本月,百度关联公司北京百度网讯科技有限公司认缴17.6471万元,

ZP独家获悉,AI芯片及系统架构研发商“上海昉擎科技”于近日完成 Pre-A3 轮融资,新引入投资人国开科创、钧山资本、建发新兴投资、多维资本,多维资本担任本轮融资财务顾问并担任后续融资独家财务顾问。
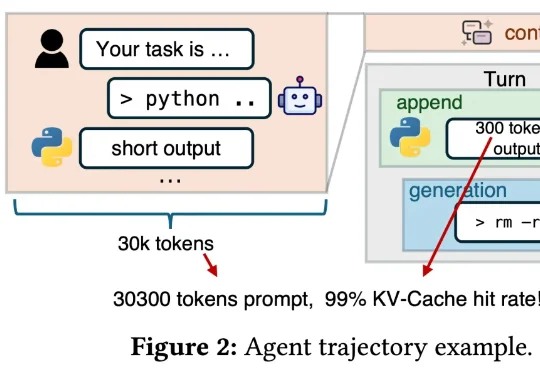
「DeepSeek V4 来了!」这样的消息是不是已经听烦了?总结来说,这篇新论文介绍了一个名为「DualPath」的创新推理系统,专门针对智能体工作负载下的大语言模型(LLM)推理性能进行优化。具体来讲,通过引入「双路径 KV-Cache 加载」机制,解决了在预填充 - 解码(PD)分离架构下,KV-Cache 读取负载不平衡的问题。
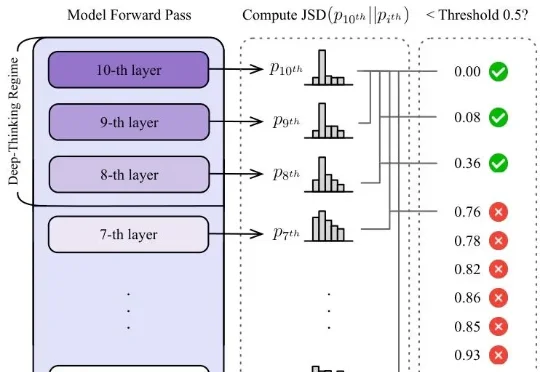
大模型的思维链越长,推理能力就越强?谷歌Say No——token数量和推理质量,真没啥正相关,因为token和token还不一样,有些纯凑数,深度思考token才真有用。新研究抛弃字数论,甩出衡量模型推理质量的全新标准DTR,专门揪模型是在真思考还是水字数。
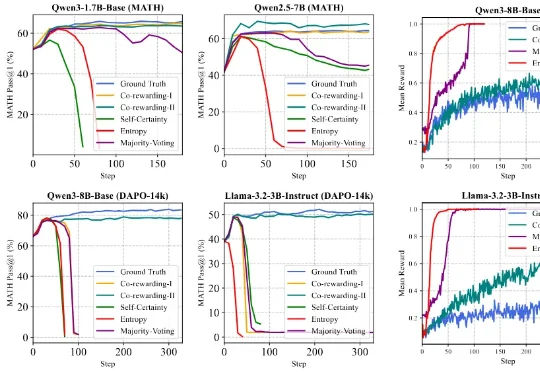
针对这一挑战,来自香港浸会大学和上海交通大学的可信机器学习和推理组提出了一个全新的自监督 RL 框架 ——Co-rewarding。该框架通过在数据端或模型端引入互补视角的自监督信号,稳定奖励获取,提升 RL 过程中模型奖励投机的难度,从而有效避免 RL 训练崩溃,实现稳定训练和模型推理能力的诱导。