# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
就在一周前,全宇宙最火爆的推理框架 SGLang 官宣支持了 Diffusion 模型,好评如潮。团队成员将原本在大语言模型推理中表现突出的高性能调度与内核优化,扩展到图像与视频扩散模型上,相较于先前的视频和图像生成框架,速度提升最高可达 57%:
模型支持:覆盖主流开源视频和图像生成模型,包括 Wan 系列、Hunyuan、Qwen-Image、Qwen-Image-Edit、Flux 等。
性能加速:在多种工作负载上实现最高 57% 的推理加速。
多种接口:提供 OpenAI 兼容 API、CLI 和 Python 接口,降低使用门槛。
完整生态:与 FastVideo 团队合作,打造从模型训练到生产部署的端到端解决方案。
过去两年,SGLang 借助高效调度与自研内核,在大模型推理场景建立了「高性能推理引擎」的口碑。
而在图像与视频生成领域,扩散模型(Diffusion Models)逐渐成为领域基石——无论是视频模型 Wan / FastWan / 混元(Hunyuan),还是图像模型 Qwen-Image / Flux,都被广泛应用。
社区中一直有强烈诉求:「能否用同一套高性能基础设施,同时跑 LLM 和扩散模型?」/「我们已经在用 SGLang 推理 LLM,可不可以用同一套引擎,把图像和视频也一起加速?」
SGLang 团队给出了肯定的回答:SGLang Diffusion。
更深层的原因在于,未来的生成式 AI,很可能不再是「单一架构」的世界,而是 自回归(AR)+ 扩散(Diffusion) 的混合架构:
要支撑这种「多架构融合」的新时代,需要一个统一的高性能推理底座,能同时处理语言任务与扩散任务。SGLang Diffusion 的目标,是成为面向未来的高性能多模态底座。
具体实现上,SGLang Diffusion 采用了独立优化架构与底层生态共享的策略:
为了适配扩散模型复杂多变的结构,SGLang 团队提出了ComposedPipelineBase。可以理解为把扩散推理过程拆成一个个可复用的 Stage,再用 ComposedPipelineBase 把它们按需「拼起来」。
典型 Stage 包括:
这套顶层设计给开发者和有魔改的用户都带来几个明显好处:
为了追求极致性能,SGLang Diffusion 还在扩散推理中引入了先进的并行技术:
注意到,SGLang Diffusion 底层仍由 sgl-kernel 承载,这也为未来引入了量化等高性能内核提供了天然扩展位。
为了提供无缝的使用体验,SGLang Diffusion 提供了多种熟悉的接口形式,包括:
对于已有基于 OpenAI API 的应用而言,引入 SGLang Diffusion 几乎是「零改动」级别,开发者可以以最小改动将扩散生成能力集成到现有工作流中。
sglang generate \
--model-path Wan-AI/Wan2.1-T2V-1.3B-Diffusers \
--prompt "A simple, natural shot of an ordinary jeep driving along a quiet forest road. Trees line both sides of the road, sunlight filtering softly through the leaves. The camera follows the jeep from a gentle forward or side angle, with calm, steady motion. Realistic lighting, relaxed atmosphere, and smooth, subtle movement." \
--save-output

sglang generate --model-path=Wan-AI/Wan2.1-I2V-14B-480P-Diffusers \
--prompt="Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard. The fluffy-furred feline gazes directly at the camera with a relaxed expression. Blurred beach scenery forms the background featuring crystal-clear waters, distant green hills, and a blue sky dotted with white clouds. The cat assumes a naturally relaxed posture, as if savoring the sea breeze and warm sunlight. A close-up shot highlights the feline's intricate details and the refreshing atmosphere of the seaside." \ --image-path="https://github.com/Wan-Video/Wan2.2/blob/990af50de458c19590c245151197326e208d7191/examples/i2v_input.JPG?raw=true" \
--num-gpus 2 --enable-cfg-parallel --save-output

sglang generate --model-path black-forest-labs/FLUX.1-dev \
--prompt "A Logo With Bold Large Text: SGL Diffusion" \
--save-output

sglang generate --model-path=Qwen/Qwen-Image
--prompt='A cute cat'
--width=720 --height=720
--save-output

sglang generate --model-path=Qwen/Qwen-Image-Edit \
--prompt="Convert 2D style to 3D style" \
--image-path="https://github.com/lm-sys/lm-sys.github.io/releases/download/test/TI2I_Qwen_Image_Edit_Input.jpg" \
--width=1024 --height=1536
--save-output

输入

输出
对比 Huggingface Diffusers 等开源基线(Baseline),SGLang Diffusion 实现了显著的性能提升:
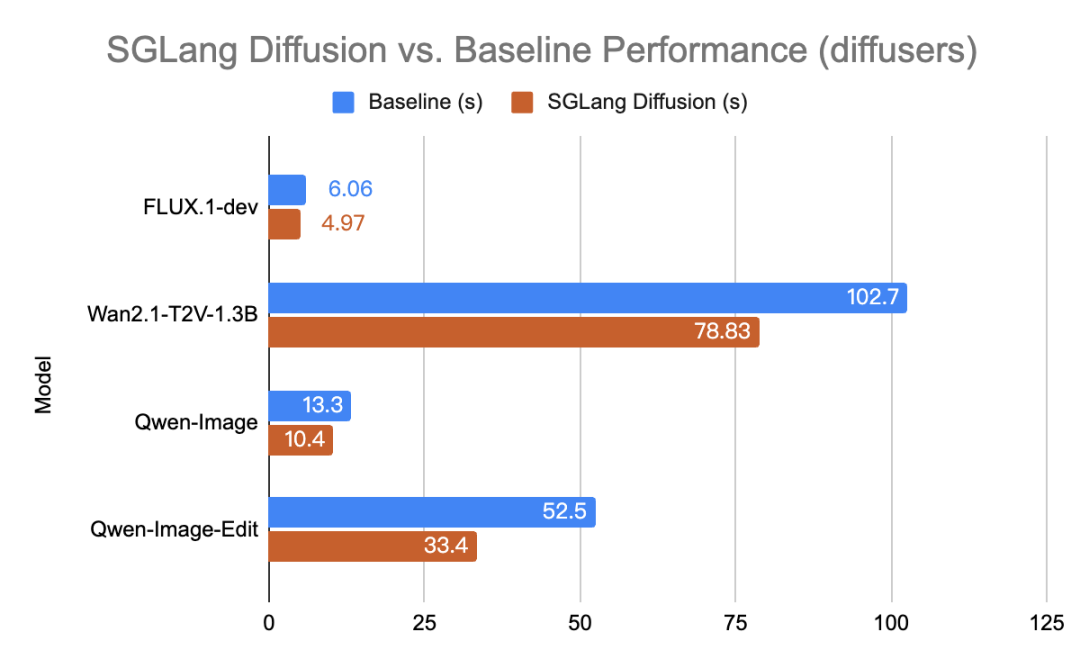
SGL Diffusion Performance Benchmark on an H100 GPU(横坐标为多次平均后的推理耗时,越短意味着性能越高)

SGLang Diffusion Performance Benchmark on an H200 GPU(横坐标为多次平均后的推理耗时,越短意味着性能越高)
SGLang Diffusion 团队专注于持续创新,这些升级都指向一个目标:在扩散推理中复刻甚至超越 SGLang 在 LLM 场景中已有的性能优势:
从长上下文 LLM,到图像与视频扩散模型,再到未来的多模态统一架构,SGLang 正在把「高性能推理」这件事做得越来越系统化、工程化。
对于研究者和工程师来说,SGLang Diffusion 至少带来三件有价值的事:
如果你正在做视频生成、图像生成,或者在探索 AR + Diffusion 融合路线,欢迎尝试 SGLang Diffusion!
文章来自于微信公众号 “机器之心”,作者 “机器之心”


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【部分开源免费】FLUX是由Black Forest Labs开发的一个文生图和图生图的AI绘图项目,该团队为前SD成员构成。该项目是目前效果最好的文生图开源项目,效果堪比midjourney。
项目地址:https://github.com/black-forest-labs/flux
在线使用:https://fluximg.com/zh
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
