
Agent要数量也要脑子!浪潮信息一边单柜养4万Agent,一边让大模型组队答题
Agent要数量也要脑子!浪潮信息一边单柜养4万Agent,一边让大模型组队答题AI基础设施的核心任务,已经从支撑大模型推理,转向支撑海量智能体的规模化运行与高质量Token的持续生产。
来自主题: AI资讯
9049 点击 2026-07-14 10:35
 搜索
搜索
AI基础设施的核心任务,已经从支撑大模型推理,转向支撑海量智能体的规模化运行与高质量Token的持续生产。

近期,DeepSeek发布DSpark让大模型推理效率再次成为行业焦点。
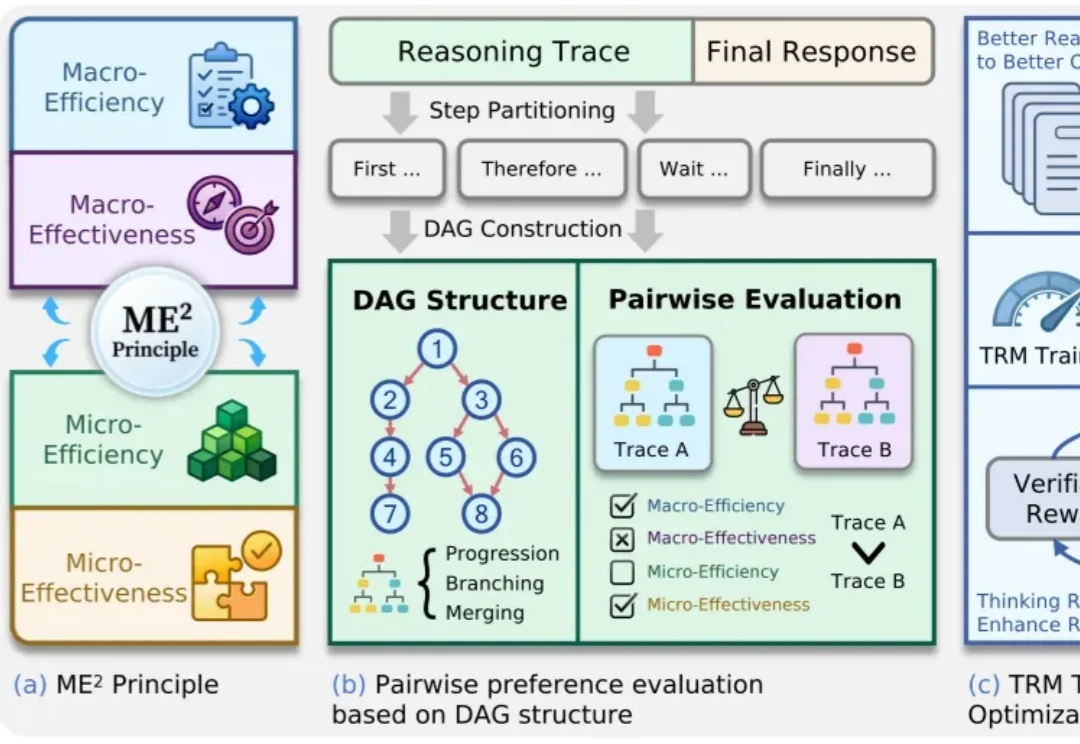
大模型推理能力越来越强,但答案对了,思考过程就一定好吗?
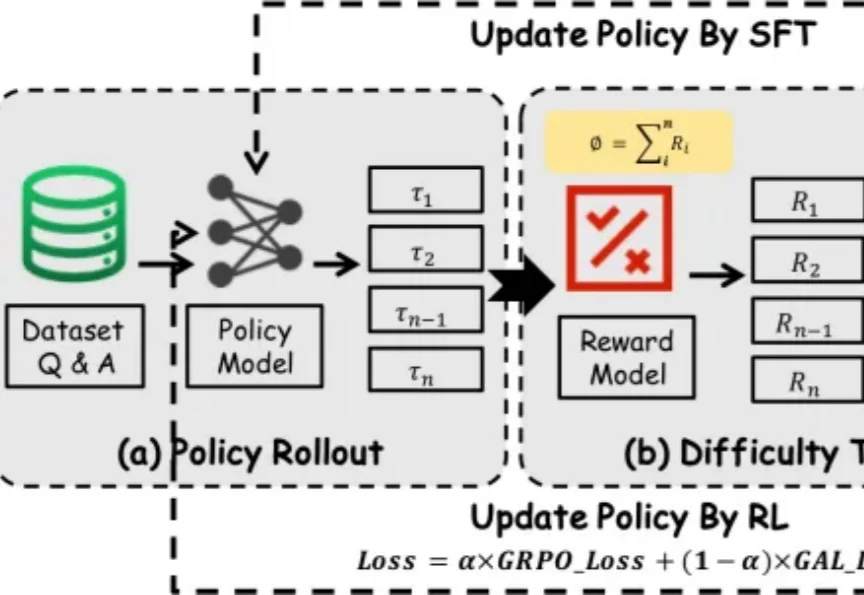
过去一段时间里,在围绕大模型推理能力增强的研究中,SFT 和 RL 是两类核心后训练范式 —— 前者稳定收敛快,能高效吸收高质量推理数据;后者更具探索性,有望推动模型实现复杂推理和分布外泛化。

在多模态大模型(MLLM)快速发展的浪潮中,融合多模型 “集体智慧” 已成为提升模型性能的关键路径,并催生了多教师知识蒸馏这一主流范式。然而,不同来源的教师模型在架构与优化上的差异,其在相似推理过程中呈现出不稳定甚至偏移的认知轨迹,即 “概念漂移”(Concept Drift)。

随着大模型后训练(Post-training)技术的发展,强化学习(RL)在提升模型推理能力方面的表现备受瞩目。

如果你让大模型给林黛玉找一个外国文学里的平替,它能给出令人信服的答案吗?这个脑洞的背后其实是当下人工智能最核心的软肋——“类比推理”能力。

智能体时代的核心是算力。

大模型时代的「炼金术师」们,或许都曾面临一个共同的困扰:当我们试图将 DeepSeek-R1、OpenAI-o1 那种惊艳的推理能力迁移到小规模语言模型(SLMs)时,效果却总是差强人意。现有的强化学习方法如 GRPO 在 7B+ 的大模型上效果显著,但一旦应用到 1.7B 甚至更小参数的模型上,性能提升就微乎其微。

在 AI 工程界,长文本推理一直是个“富贵病”。