【LLM开源模型】LLMs-Llama3.1-240723通关攻略笔记v1.0
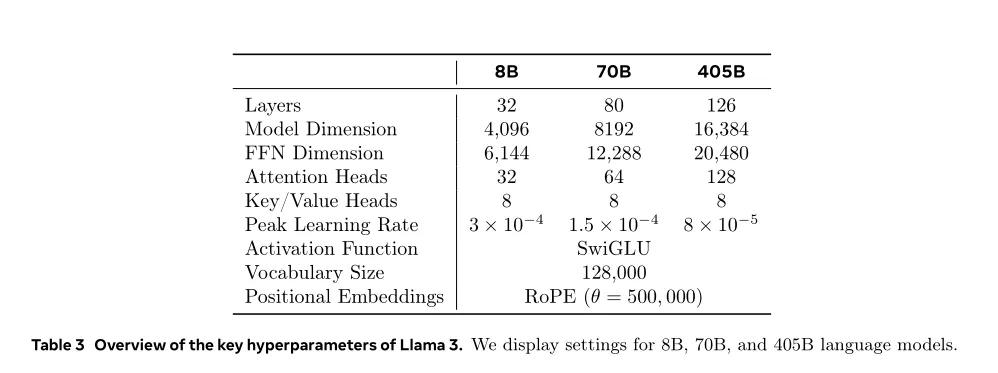
【LLM开源模型】LLMs-Llama3.1-240723通关攻略笔记v1.0不同类型的数据配比如何配置:先通过小规模实验确定最优配比,然后将其应用到大模型的训练中。 Token配比结论:通用知识50%;数学与逻辑25%;代码17%;多语言8%。
来自主题: AI技术研报
10985 点击 2024-08-02 11:53
 搜索
搜索
不同类型的数据配比如何配置:先通过小规模实验确定最优配比,然后将其应用到大模型的训练中。 Token配比结论:通用知识50%;数学与逻辑25%;代码17%;多语言8%。
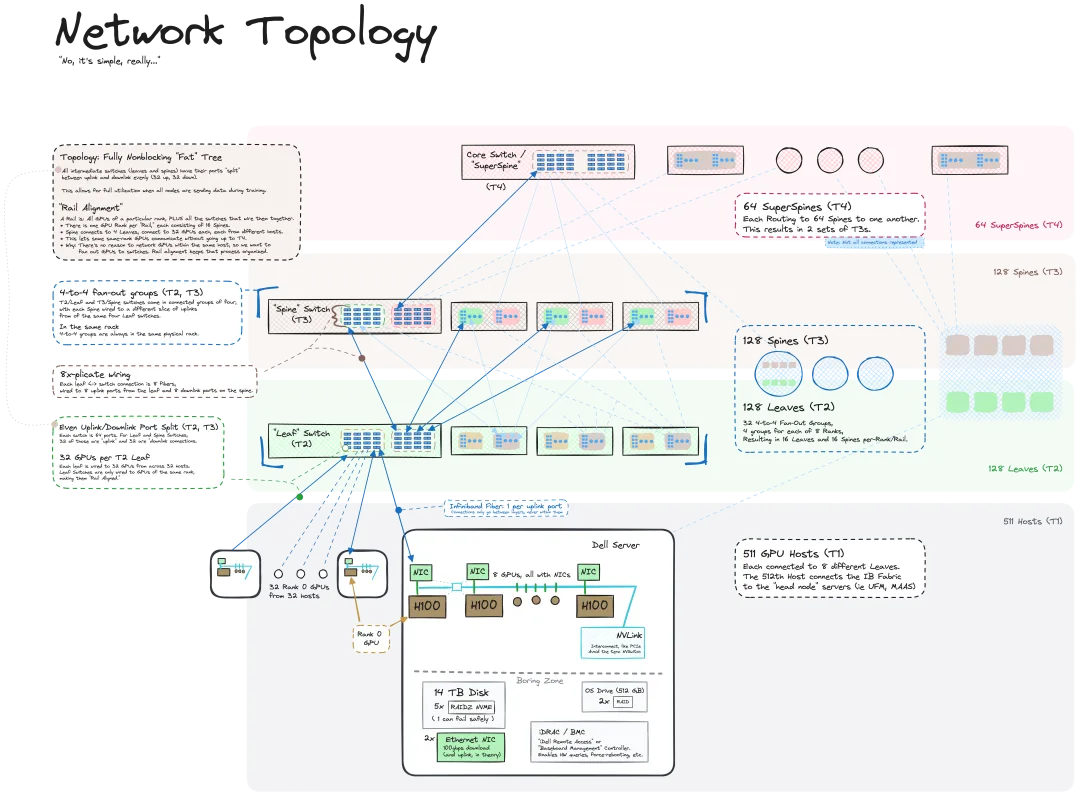
我们知道 LLM 是在大规模计算机集群上使用海量数据训练得到的,机器之心曾介绍过不少用于辅助和改进 LLM 训练流程的方法和技术。而今天,我们要分享的是一篇深入技术底层的文章,介绍如何将一堆连操作系统也没有的「裸机」变成用于训练 LLM 的计算机集群。

Diffusion 不仅可以更好地模仿,而且可以进行「创作」。扩散模型(Diffusion Model)是图像生成模型的一种。有别于此前 AI 领域大名鼎鼎的 GAN、VAE 等算法,扩散模型另辟蹊径,其主要思想是一种先对图像增加噪声,再逐步去噪的过程,其中如何去噪还原图像是算法的核心部分。而它的最终算法能够从一张随机的噪声图像中生成图像。