最强32B中文推理大模型易主:Skywork-OR1 开源免费商用,1/20 DeepSeek-R1参数量SOTA,权重代码数据集全开源
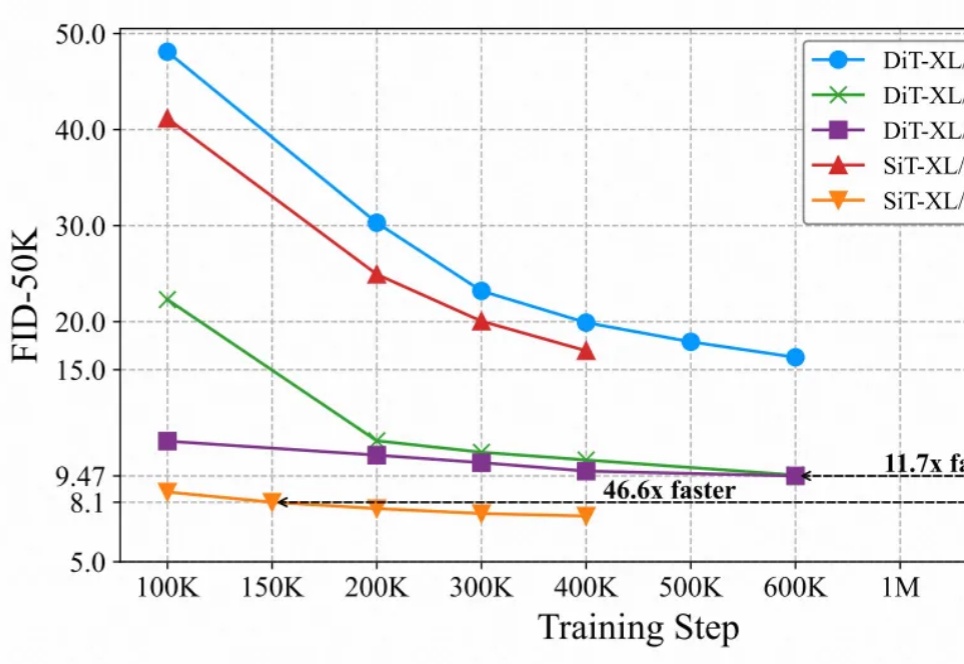
最强32B中文推理大模型易主:Skywork-OR1 开源免费商用,1/20 DeepSeek-R1参数量SOTA,权重代码数据集全开源千亿参数内最强推理大模型,刚刚易主了。32B——DeepSeek-R1的1/20参数量;免费商用;且全面开源——模型权重、训练数据集和完整训练代码,都开源了。这就是刚刚亮相的Skywork-OR1 (Open Reasoner 1)系列模型——
来自主题: AI资讯
11482 点击 2025-04-13 23:34