
中国 AI 公司,该怎么「抄 Claude Code 的作业」?
中国 AI 公司,该怎么「抄 Claude Code 的作业」?一次低级失误,让全球开发者拿到了 AI 编程工具的「行业标准答案」。一个更重要的问题是,AI 公司,应该如何利用这次「泄露」,抄作业?很多人第一反应是:Claude Code 不就是一个套了模型 API 的命令行工具吗?源代码泄露了又怎样,没有模型权重,这些代码不过是个「壳子」。
来自主题: AI资讯
6564 点击 2026-04-01 17:05
 搜索
搜索
一次低级失误,让全球开发者拿到了 AI 编程工具的「行业标准答案」。一个更重要的问题是,AI 公司,应该如何利用这次「泄露」,抄作业?很多人第一反应是:Claude Code 不就是一个套了模型 API 的命令行工具吗?源代码泄露了又怎样,没有模型权重,这些代码不过是个「壳子」。
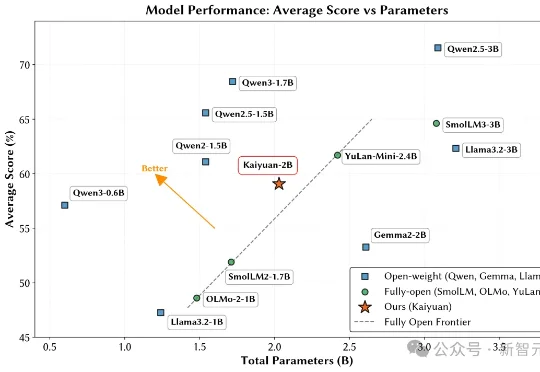
鹏城实验室与清华大学PACMAN实验室联合发布了鹏城脑海‑2.1‑开元‑2B(PCMind‑2.1‑Kaiyuan‑2B,简称开元‑2B)模型,并以全流程开源的方式回应了这一挑战——从训练数据、数据处理框架、训练框架、完整技术报告到最终模型权重,全部开源。

随着大语言模型(LLM)的商业价值快速提升,其昂贵的训练成本使得模型版权保护(IP Protection)成为业界关注的焦点。然而,现有模型版权验证手段(如模型指纹)往往忽略一个关键威胁:攻击者一旦直接窃取模型权重,即拥有对模型的完全控制权,能够逆向指纹 / 水印,或通过修改输出内容绕过指纹验证。

长期以来,多模态代码生成(Multimodal Code Generation)的训练严重依赖于特定任务的监督微调(SFT)。尽管这种范式在 Chart-to-code 等单一任务上取得了显著成功 ,但其 “狭隘的训练范围” 从根本上限制了模型的泛化能力,阻碍了通用视觉代码智能(Generalized VIsioN Code Intelligence)的发展 。
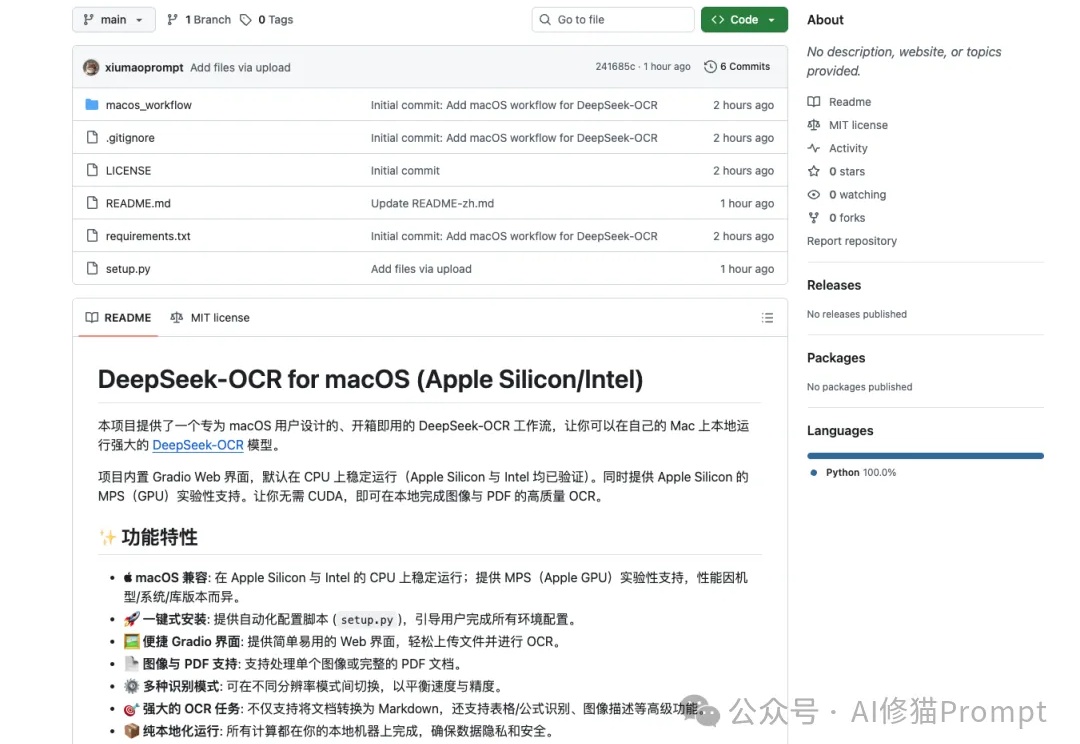
DeepSeek-OCR这段时间非常火,但官方开源的文件是“按 NVIDIA/CUDA 习惯写的 Linux 版推理脚本+模型权重”,而不是“跨设备跨后端”的通吃实现,因此无法直接在苹果设备上运行,对于Mac用户来说,在许多新模型诞生的第一时间,往往只能望“模”兴叹。

就在刚刚,智谱正式发布最新旗舰模型 GLM-4.5。按照智谱官方说法,这是一款专为 Agent 应用打造的基础模型。延续一贯的开源原则,目前这款模型已经在 Hugging Face 与 ModelScope 平台同步开源,模型权重遵循 MIT License。
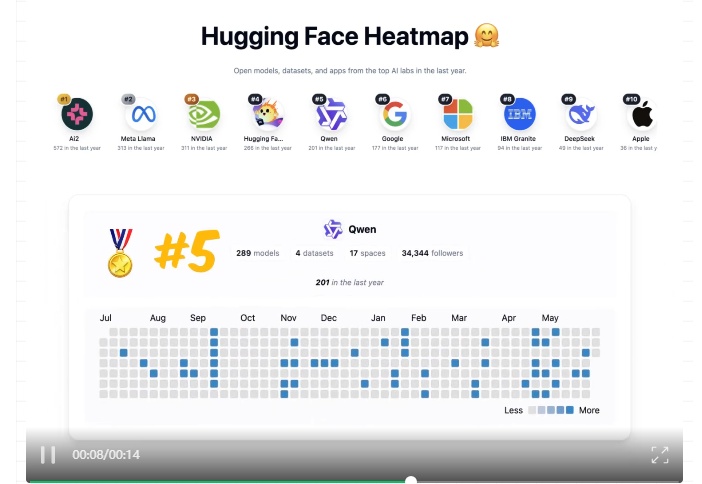
全球知名开源AI平台Hugging Face近日发布开放权重模型贡献榜,中国团队Qwen和DeepSeek成功入围前15名,彰显了中国在全球开源AI领域的技术实力与影响力。该榜单表彰为开源社区提供高质量模型权重的团队,其模型广泛应用于学术与产业创新。
今天,我们正式发布 DeepSeek-R1,并同步开源模型权重。DeepSeek-R1 遵循 MIT License,允许用户通过蒸馏技术借助 R1 训练其他模型。DeepSeek-R1 上线API,对用户开放思维链输出,通过设置 `model='deepseek-reasoner'` 即可调用。

就在刚刚,美国政府曝光了各界对「AI行动计划」的全部政策建议。OpenAI措辞激烈地表示,DeepSeek让我们看到,必须马上锁死中国AI,必须限制高端GPU芯片和模型权重流向中国!Anthropic同样呼吁:必须立马补上H20这一关键漏洞,并且严控H100的门槛。
新国产AI视频生成模型横空出世,一夜间全网刷屏。Magi-1,首个实现顶级画质输出的自回归视频生成模型,模型权重、代码100%开源。整整61页的技术报告中还详细介绍了创新的注意力改进和推理基础设施设计,给人一种视频版DeepSeek的感觉。