单次训练横扫9个基准,遥感检测最大数据集与基础模型框架LEVIRDet问世
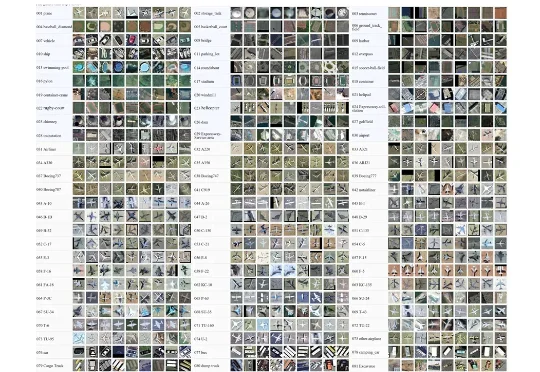
单次训练横扫9个基准,遥感检测最大数据集与基础模型框架LEVIRDet问世近日,北京航空航天大学史振威教授和邹征夏教授团队发布了一个面向通用遥感目标检测的大规模数据集与基础模型框架 ——LEVIRDet。该研究构建了目前最大规模、最全面的遥感目标检测数据集 LEVIRDet-159,并在此基础上提出了面向通用遥感检测的基础模型 LEVIRDetNet。
来自主题: AI技术研报
7531 点击 2026-07-07 10:20