
民办大模型MiniMax努力专升本
民办大模型MiniMax努力专升本葬AI身边的朋友常常有个疑问:为什么MiniMax M3做的不够好(问了很多在做模型测评的朋友,也是类似看法),但市场仍然觉得他们是第一梯队?我朋友@朱亦辉的解释是,MiniMax M3的核心科技是叙事能力,让外界觉得他们和Kimi是一个级别,达到一个强行双骄的效果。
来自主题: AI资讯
9853 点击 2026-07-10 10:31
 搜索
搜索
葬AI身边的朋友常常有个疑问:为什么MiniMax M3做的不够好(问了很多在做模型测评的朋友,也是类似看法),但市场仍然觉得他们是第一梯队?我朋友@朱亦辉的解释是,MiniMax M3的核心科技是叙事能力,让外界觉得他们和Kimi是一个级别,达到一个强行双骄的效果。

你有没有想过一个问题: 我们平时选模型,到底有多少是因为它真的好用,又有多少是因为它便宜?
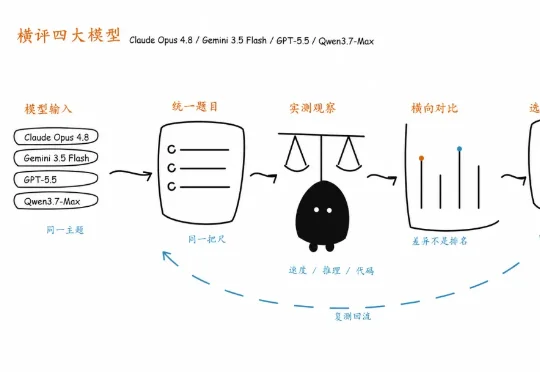
普通人看排行榜估计越看越疑惑,写文章该用哪个?数据分析该用哪个?写代码、审 PR、拆任务又该用哪个?我挑了四款最近讨论度很高的模型:Claude Opus 4.8、Gemini 3.5 Flash、GPT-5.5、Qwen3.7-Max,做一次横评,看看它们在真实任务里的交付表现。

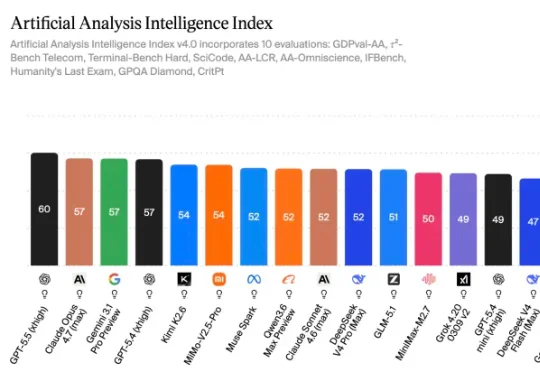
超越 GPT-5.5、Gemini 3.5 Flash、DeepSeek V4 Pro,阿里的最新旗舰模型 Qwen3.7 Max 在编程竞技榜拿下第二名,仅次于 Claude Opus 4.7。除了真实场景的用户选择,在传统的大模型固定评测榜单上,像是终端能力 Terminal Bench、编程能力 SWE Bench 等,Qwen3.7 Max 的表现也是拿下了国产模型的冠军。
上周太集中发的后果就是光在用GPT -5.5了,小米的Mimo-V2.5-Pro,DeepSeek V4 Pro还没有放在Agent的场景上测。所以我跟钱包一拍即合,复制了4个一模一样的Hermes Agent,记忆一样,skill一样,系统设置一样,能调用的工具也一样。

从去年开始做这个账号以来,我其实写过不少测模型的文章。我相信也有很多朋友是因为看了我测评的文章关注我的。但从过年之后,真的就很少写模型评测的文章了。主要是我写文章的速度甚至一度跟不上模型发布的速度了。
四月真是如风驰电掣:Anthropic 发布了 Opus 4.7,OpenAI 发布了 GPT 5.5,最后,DeepSeek 更新了暌违已久的 V4。三家公司的发布通稿读起来都差不多:跑分又涨了,上下文更长了,推理更强了,代码能力又创了新高。

终于,“养虾人”们也有自己的专属模型了。
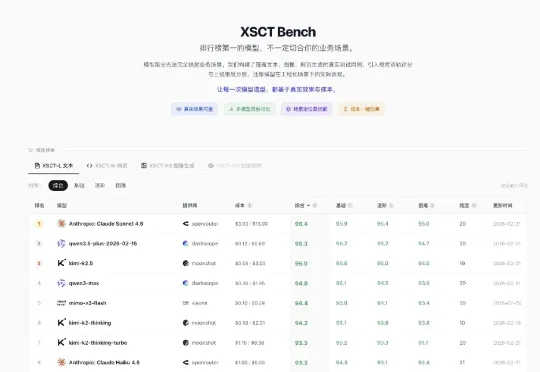
春节闭关五天,我做了个东西:一个大模型场景化测评平台。35000+ 次模型跑测,一共 42+ 模型,11,000 块人民币。我全部跑完了,结论汇成一个平台,还会持续更新。
模型众多,该如何选择? GPT-5:OpenAI的最新旗舰模型,统一智能系统,GPT-5 集成了多个模型,自动根据任务复杂度选择最适合的模型进行处理,多模态首选。 GPT-5 Thinking:GPT