
破案了!为啥ChatGPT老想着「稳稳地接住你」
破案了!为啥ChatGPT老想着「稳稳地接住你」其中,大家「讨伐」声量最大的莫过于 ChatGPT 了,从 AI 味儿熏人的经典破折号、「不是 A,而是 B」句式,以及前段时间间歇性出现的「哥布林」,再到如今充满青春伤痛文学矫情劲儿的「我会稳稳接住你」,用户快要被折磨疯了:我们关系可以亲密,但没必要这么亲密。
来自主题: AI资讯
8466 点击 2026-05-08 15:31
 搜索
搜索
其中,大家「讨伐」声量最大的莫过于 ChatGPT 了,从 AI 味儿熏人的经典破折号、「不是 A,而是 B」句式,以及前段时间间歇性出现的「哥布林」,再到如今充满青春伤痛文学矫情劲儿的「我会稳稳接住你」,用户快要被折磨疯了:我们关系可以亲密,但没必要这么亲密。

为了解决这一痛点,由 MBZUAI、复旦大学、中国人民大学高瓴人工智能学院以及哈佛大学联合组成的研究团队,提出了一种名为 Laser 的全新隐式视觉推理范式。该研究从认知心理学中汲取灵感,引入了 “Forest-before-Trees” 的认知机制,通过动态窗口对齐学习(DWAL),首次实现了在隐空间中维持视觉特征的 “概率叠加” 状态。
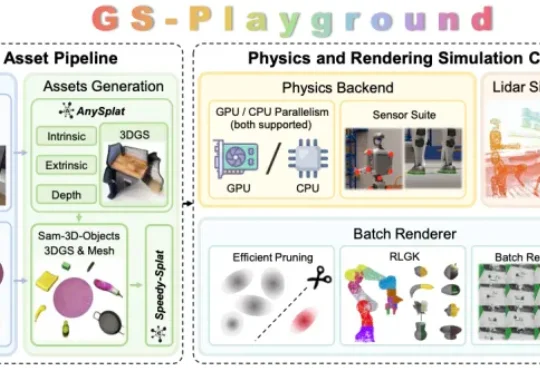
近日,清华大学智能产业研究院(AIR)DISCOVER Lab 联合谋先飞技术、原力灵机、求之科技和地瓜机器人,提出了新一代高通量视觉高保真仿真器 GS-Playground。该成果已被机器人领域国际顶级学术会议 RSS 2026(Robotics: Science and Systems)录用,标志着国内具身智能仿真基础设施在视觉保真度与训练吞吐量两个维度上同时取得了国际领先水平的突破。

LenVM将长度建模提升到token级别,开辟可扩展价值预训练的新维度——3B开源模型精确长度控制全面击败GPT-5.4、Claude-Opus-4-6等顶级闭源模型;相同token预算下推理准确率提升10倍(63% vs 6%);沿模型规模、数据量、采样数三轴无饱和scaling的value pretraining
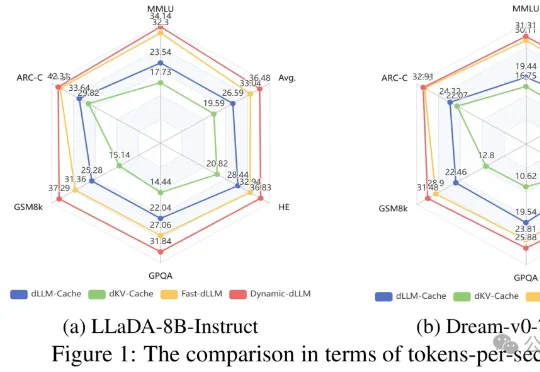
文本生成这件事,扩散大语言模型(dLLMs)正展现出巨大的潜力。但与此同时,它也面临着严重的计算瓶颈——为此,哈工大(深圳)与华为、深圳河套学院的研究团队提出了一套免训练加速框架Dynamic-dLLM。
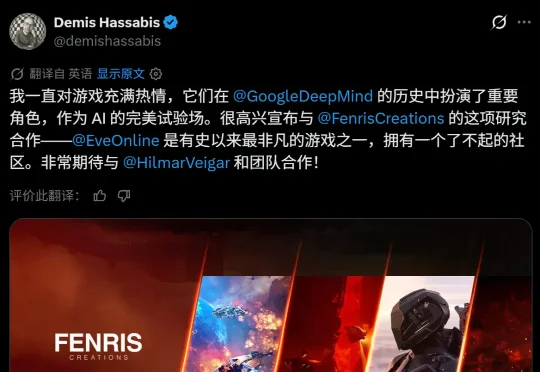
本周四,Google DeepMind 宣布他们又要开始打游戏了。这次目标还是全世界最硬核的那一款:EVE Online。Google DeepMind 此次宣布收购著名科幻在线角色扮演游戏《EVE Online》(星战前夜)开发商的部分股权,并表示将利用该游戏研究「复杂、动态、玩家驱动的系统中的智能」。
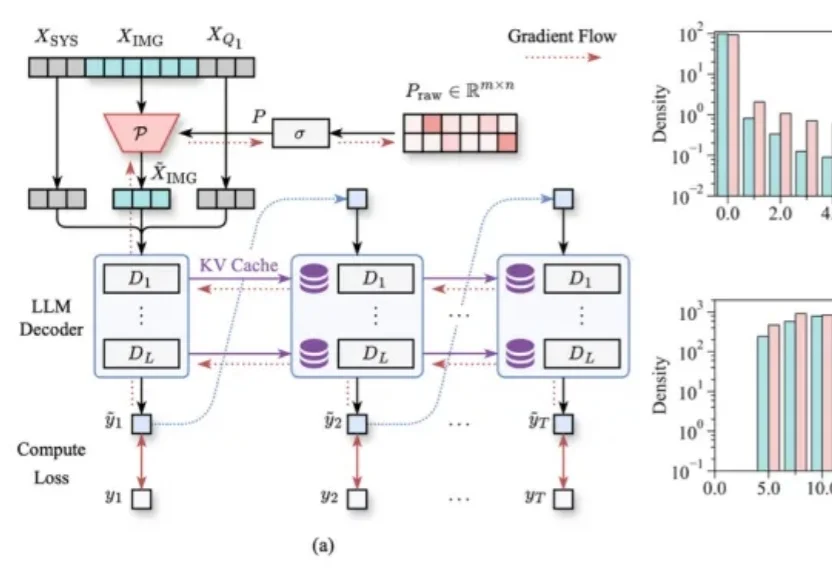
多轮视觉问答,正在成为LVLM推理效率的“照妖镜”。

OpenAI,这次又真·Open了一下。

UniGeo通过视频模型的连续视角先验与统一几何引导,实现稳定、高质量的相机可控图像生成,全面超越现有方法,在不同幅度的相机运动中提升跨视角一致性与结构稳定性。

Anthropic最新研究让AI先读懂规范背后的意义,再接受行为示范,在特定实验中将Agent失控率从54%压到7%。