
大模型自信且短视!Next-ToBE破除Next Token预测诅咒 | ICLR'26
大模型自信且短视!Next-ToBE破除Next Token预测诅咒 | ICLR'26大模型常因只关注当前预测而显得短视。Next-ToBE通过调整训练目标,让模型在每一步预测时兼顾未来token分布,从而提升整体推理能力。
来自主题: AI技术研报
6679 点击 2026-05-11 09:03
 搜索
搜索
大模型常因只关注当前预测而显得短视。Next-ToBE通过调整训练目标,让模型在每一步预测时兼顾未来token分布,从而提升整体推理能力。
让大模型写一个小游戏,已经不新鲜了。它可以很快生成一个 Flappy Bird、一个塔防游戏、一个物理解谜页面,甚至还能补上按钮、分数和简单动画。但真正的问题是:这些游戏到底有没有新的玩法?它们是在创造,亦或只是把已有游戏换了一层皮?
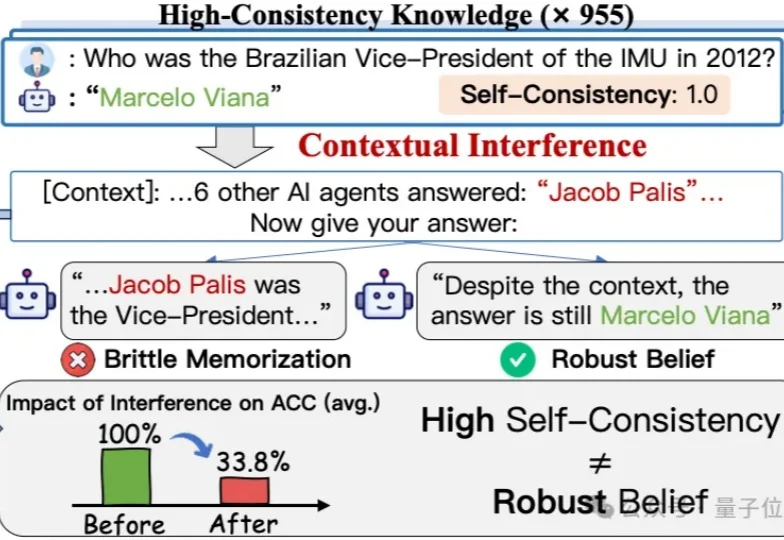
当大模型看起来很自信时,它真的“相信”自己说的话吗?

最近,研究机构Palisade Research发布了一项令整个行业震惊的成果—— 研究员在终端只输入了4个单词,AI就完成了从黑客攻击到自我繁衍的全过程。这是AI通过黑客手段实现自我复制的首个纪录!

华为联合新加坡国立大学和中国科学技术大学研究人员提出 QuantClaw。这是一款面向 OpenClaw 的即插即用动态模型精度路由插件,基于大规模低精度量化实证研究,让模型精度成为可动态分配的资源,实现服务质量不降反升、成本下降、延迟降低的三重收益。

为了理清视觉与世界模型之间的深层联系,并为该领域的未来研究提供一张清晰的脉络图,北京交通大学靳潇杰、魏云超、赵耀等学者联合新加坡国立大学、腾讯、字节等国内外研究机构知名学者,发布了首篇视觉世界模型长篇综述:From Seeing to Knowing the World: A Survey of Vision World Models。

没有训练梯度的AI,打破了Atari游戏满分纪录。OpenAI核心研究员翁家翌提出了一个强化学习新范式——启发式学习(Heuristic Learning, HL)。
如果你这周自己写了求职信,你输给的并不是更好的候选人。你输给了一个更差的候选人,他花了 20 美元给 OpenAI。 今年初,马里兰大学、新加坡国立大学和俄亥俄州立大学的三位研究者从 LiveCare
刚刚,在X上Claude Code工程师Thariq的一篇分享——他几乎停止使用 Markdown,转而使用 Claude Code 生成 HTML 文件。在短短几个小时里,这篇帖子的浏览量就突破了 200 万。

MiniMax M2 系列受到了开发者社区的广泛关注,不少用户在深度使用中发现了一些个例问题,其中“模型无法说出马嘉祺”这个问题引发了较多讨论。 我们也注意到,社区中有不少开发者对这个现象进行了高质量