
跨模态通信总丢失语义、产生歧义?加入AI大模型,LAM-MSC实现四模态统一高效传输
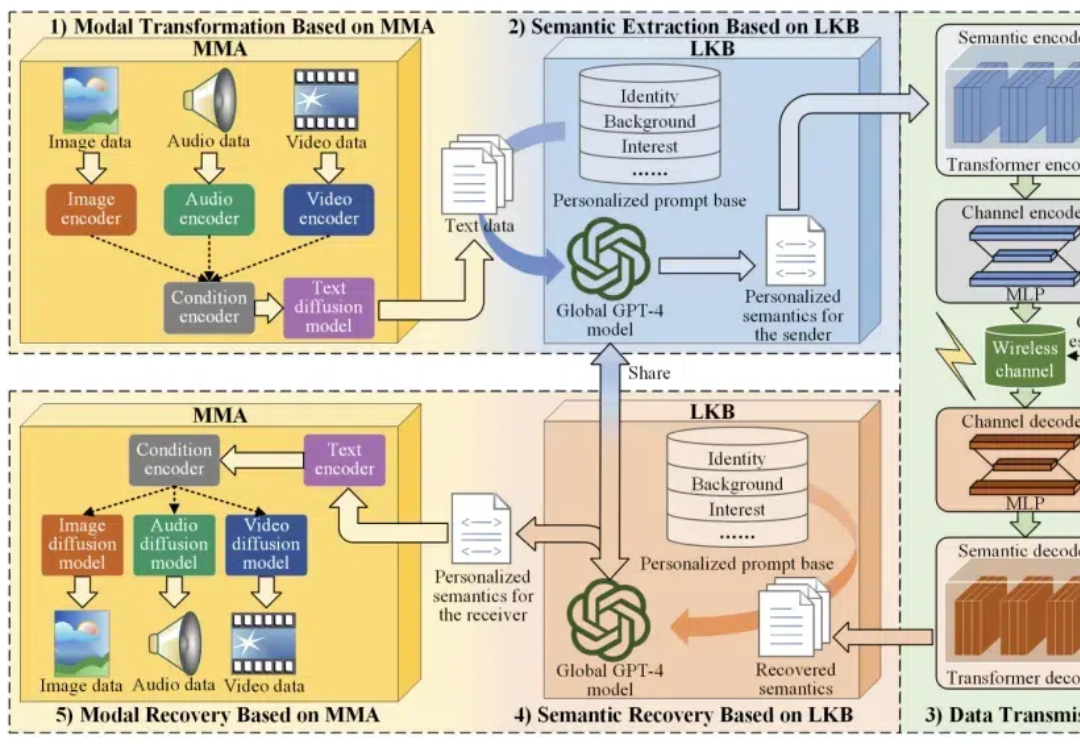
跨模态通信总丢失语义、产生歧义?加入AI大模型,LAM-MSC实现四模态统一高效传输多模态信号,包括文本、音频、图像和视频等,可以被整合到语义通信中,在语义层面提供低延迟、高质量的沉浸式体验。
来自主题: AI技术研报
7727 点击 2024-12-19 16:01
多模态信号,包括文本、音频、图像和视频等,可以被整合到语义通信中,在语义层面提供低延迟、高质量的沉浸式体验。
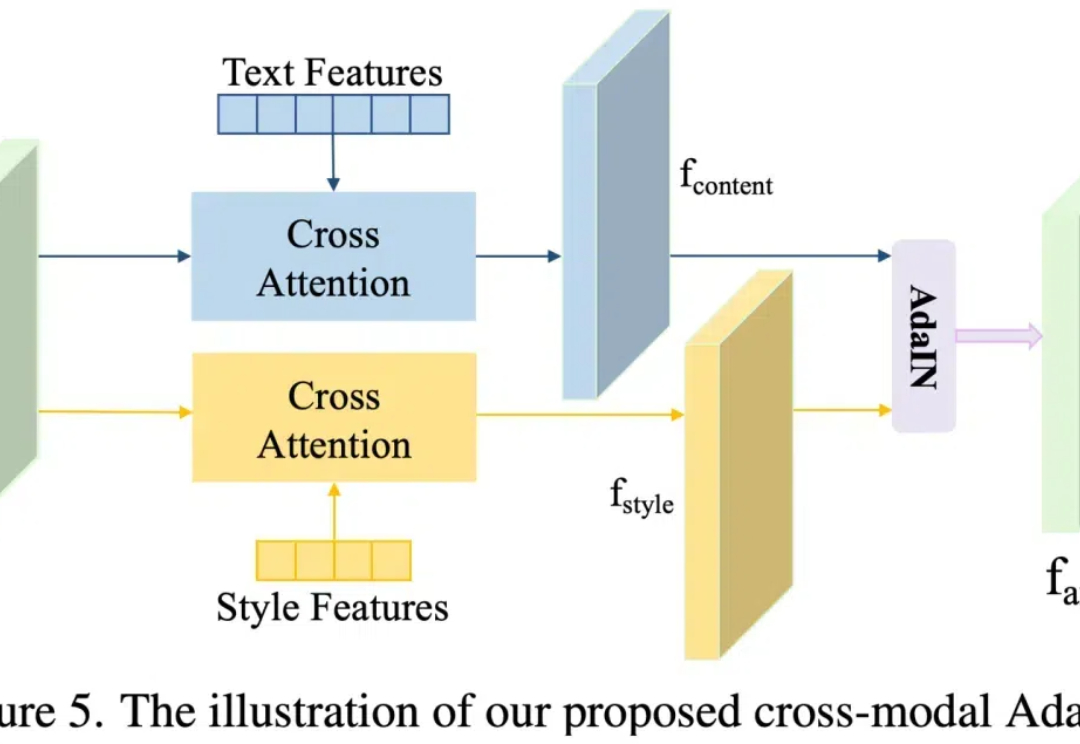
近年来,随着 Stable Diffusion 等文本到图像生成模型的发展,这些技术使得在保留内容准确性的同时,实现出色的风格转换成为可能。这项技术在数字绘画、广告和游戏设计等领域具有重要的应用价值。

面对AI圈疯传的「数据如化石燃料一般正在枯竭」,我们该如何从海量数据中掘金?AI炼出的数据飞轮2.0,或许就是答案。
要让大模型适应各不一样的下游任务,微调必不可少。常规的中心化微调过程需要模型和数据存在于同一位置 —— 要么需要数据所有者上传数据(这会威胁到数据所有者的数据隐私),要么模型所有者需要共享模型权重(这又可能泄露自己花费大量资源训练的模型)。
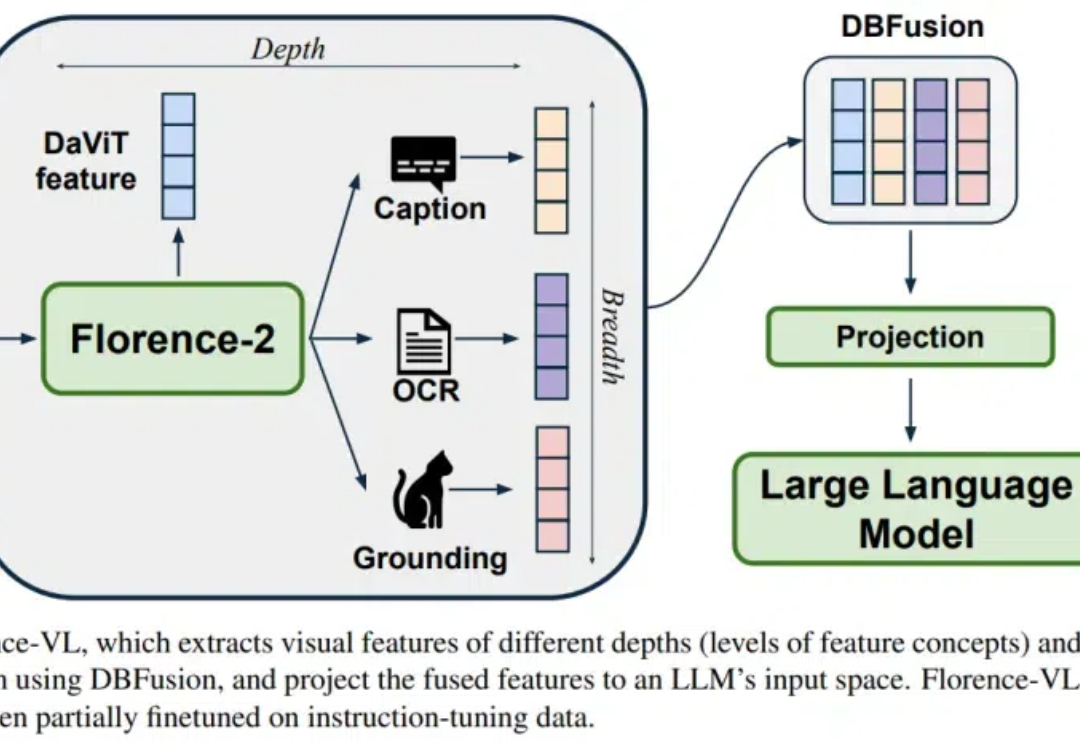
Florence-VL 提出了使用生成式视觉编码器 Florence-2 作为多模态模型的视觉信息输入,克服了传统视觉编码器(如 CLIP)仅提供单一视觉表征而往往忽略图片中关键的局部信息。
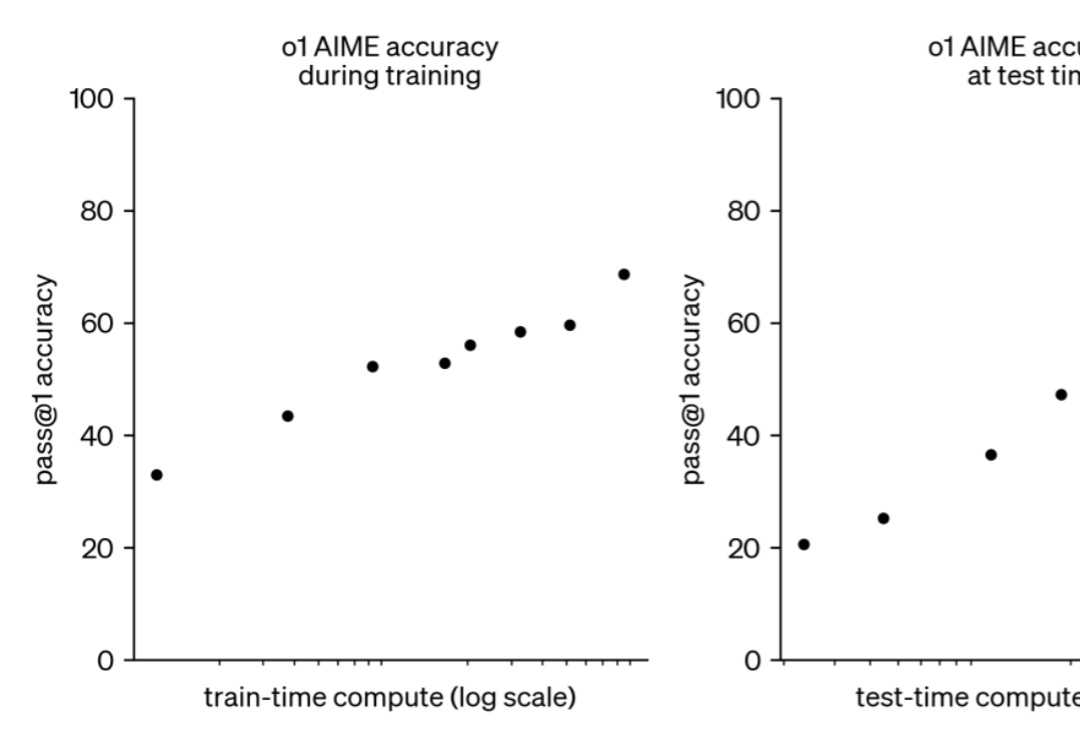
如果给小模型更长的思考时间,它们性能可以超越更大规模的模型。

现如今,以 GPT 为代表的大语言模型正深刻影响人们的生产与生活,但在处理很多专业性和复杂程度较高的问题时仍然面临挑战。在诸如药物发现、自动驾驶等复杂场景中,AI 的自主决策能力是解决问题的关键,而如何进行决策大模型的高效训练目前仍然是开放性的难题。

BLT 在许多基准测试中超越了基于 token 的架构。
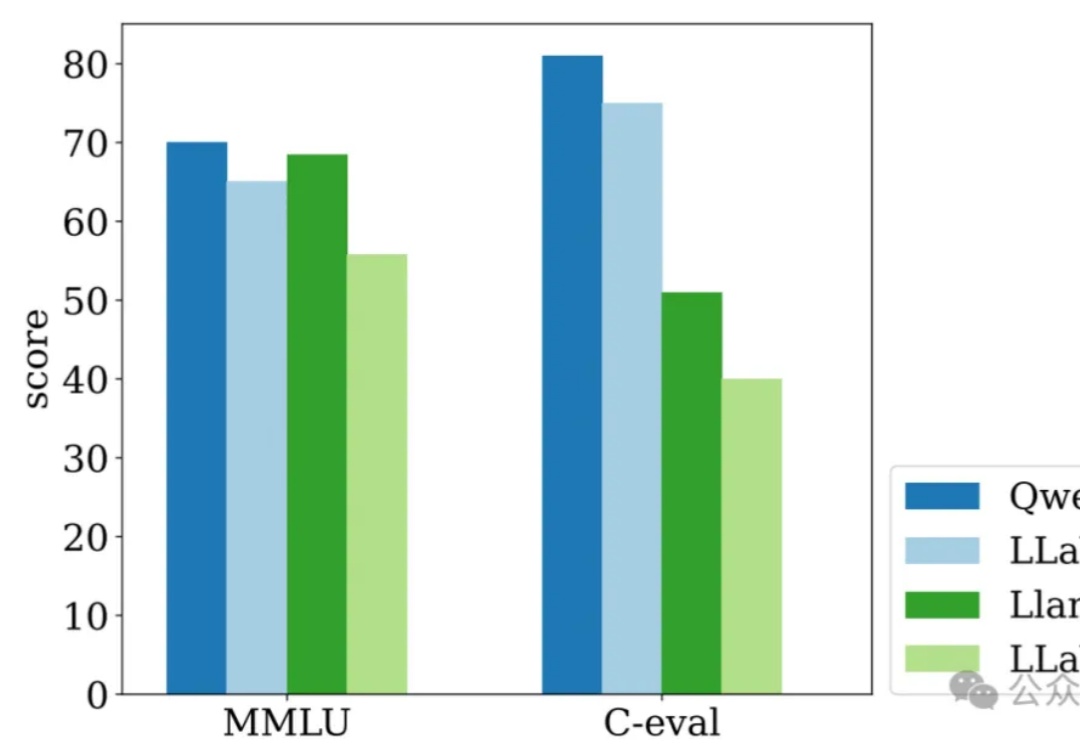
多模态大模型内嵌语言模型总是出现灾难性遗忘怎么办?
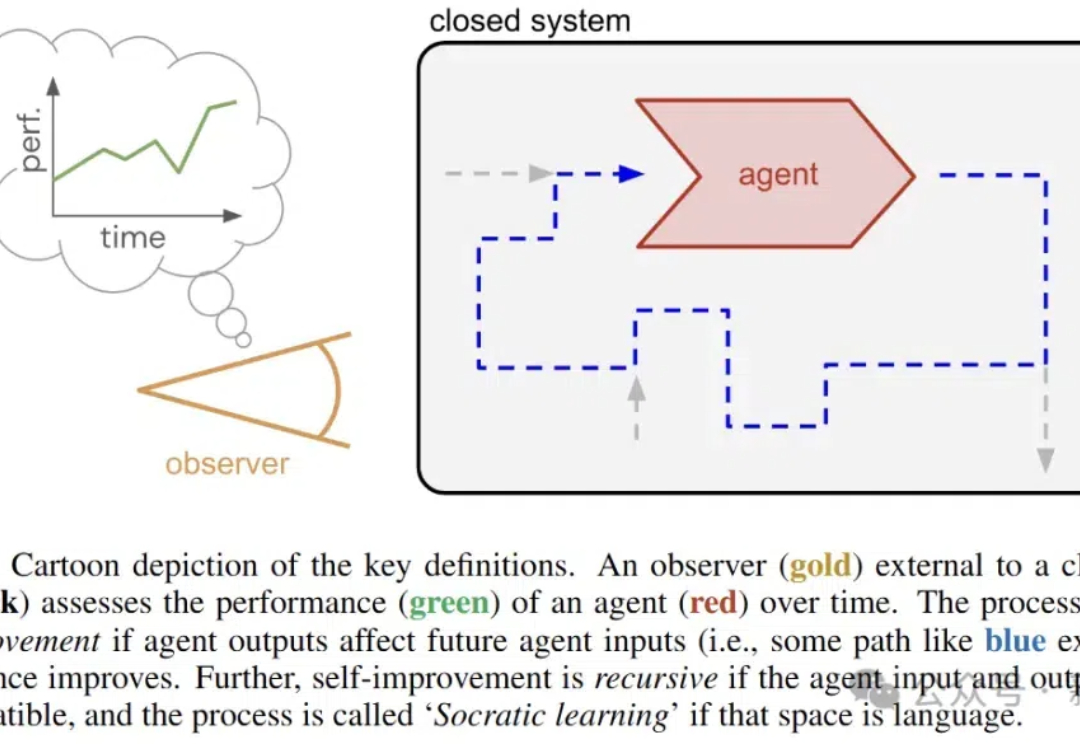
近日,谷歌DeepMind的研究人员推出了苏格拉底式学习,在没有外部数据的情况下,让AI通过语言游戏不断变强。