
北大开源全新图像压缩感知网络:参数量、推理时间大幅节省,性能显著提升 | 顶刊TPAMI
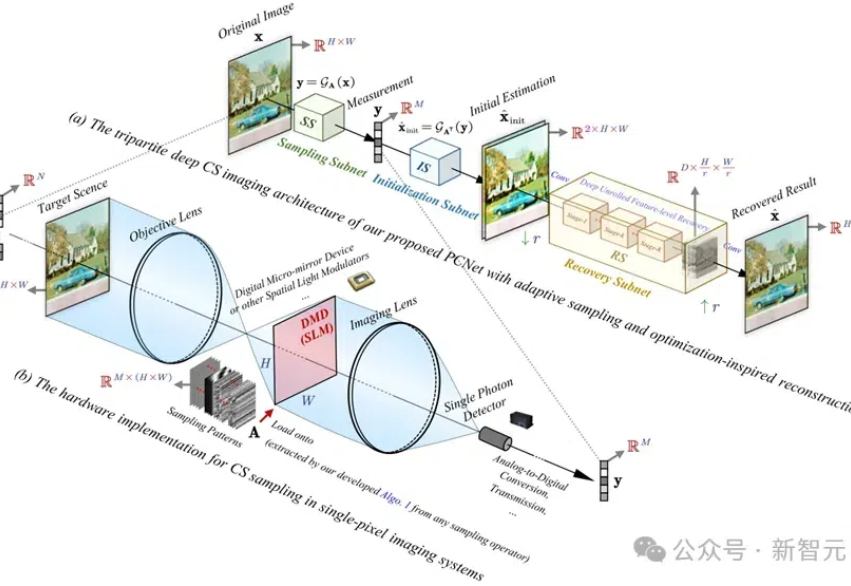
北大开源全新图像压缩感知网络:参数量、推理时间大幅节省,性能显著提升 | 顶刊TPAMIPCNet网络具有创新的协同采样算子和优化的重建网络,实验结果证明,其在图像重建精度、计算效率和任务扩展性方面均优于现有方法,为高分辨率图像的压缩感知提供了新的解决方案。
来自主题: AI技术研报
8078 点击 2024-12-17 14:35
PCNet网络具有创新的协同采样算子和优化的重建网络,实验结果证明,其在图像重建精度、计算效率和任务扩展性方面均优于现有方法,为高分辨率图像的压缩感知提供了新的解决方案。

Ilya「预训练结束了」言论一出,圈内哗然。谷歌大佬Logan Klipatrick和LeCun站出来反对说:预训练还没结束!Scaling Law真的崩了吗?Epoch AI发布报告称,我们已经进入「小模型」周期,但下一代依然会更大。
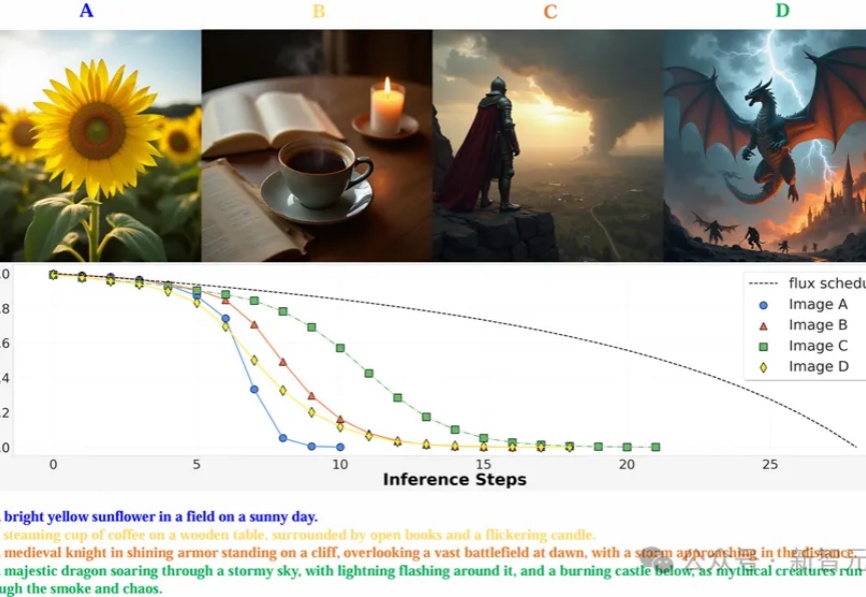
MAPLE实验室提出通过强化学习优化图像生成模型的去噪过程,使其能以更少的步骤生成高质量图像,在多个图像生成模型上实现了减少推理步骤,还能提高图像质量。
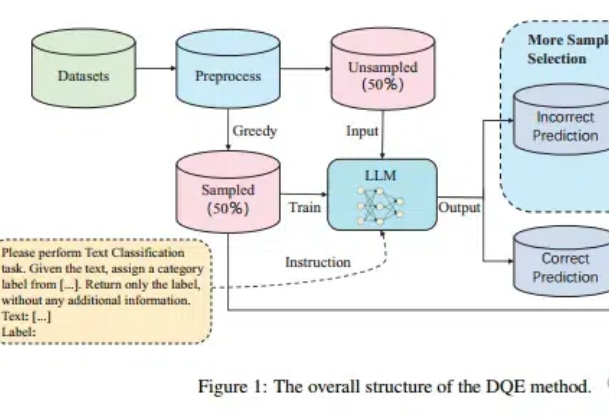
Scaling Law不仅在放缓,而且不一定总是适用! 尤其在文本分类任务中,扩大训练集的数据量可能会带来更严重的数据冲突和数据冗余。
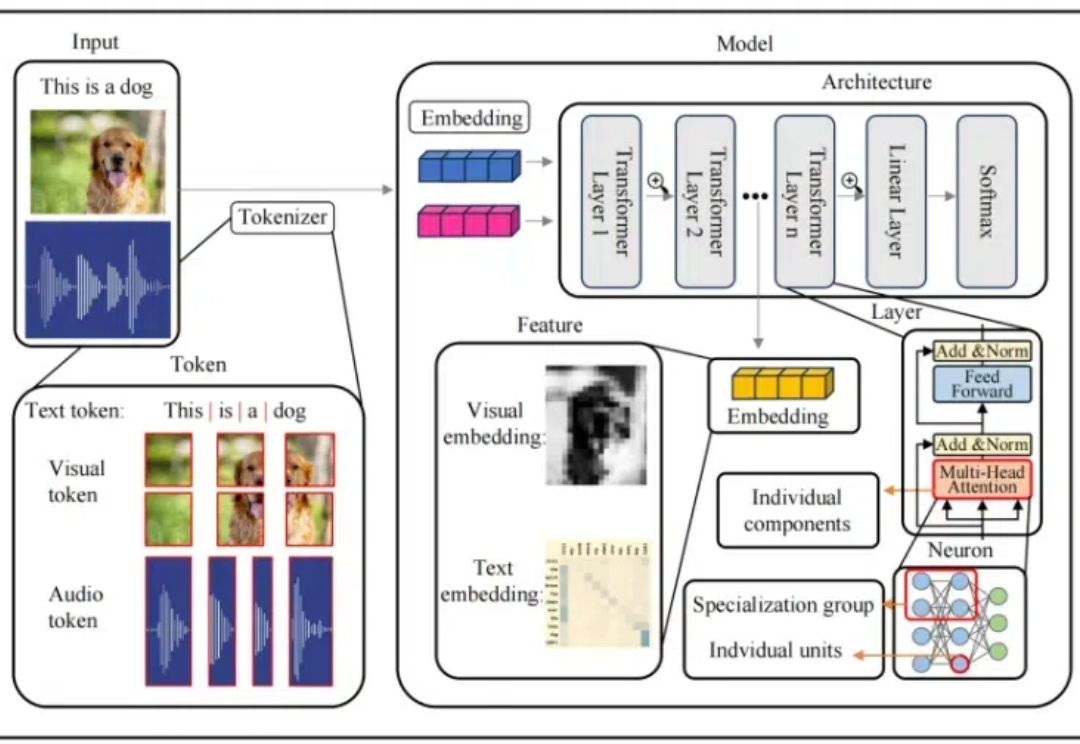
本文介绍了首个多模态大模型(MLLM)可解释性综述
ACM SIGKDD(简称 KDD)始于 1989 年,是全球数据挖掘领域历史最悠久、规模最大的国际顶级学术会议。KDD 2025 将于 2025 年 8 月 3 日在加拿大多伦多举办。

大语言模型(LLMs)通过更多的推理展现出了更强的能力和可靠性,从思维链提示发展到了 OpenAI-o1 这样具有较强推理能力的模型。
Transformer模型自2017年问世以来,已成为AI领域的核心技术,尤其在自然语言处理中占据主导地位。然而,关于其核心机制“注意力”的起源,学界存在争议,一些学者如Jürgen Schmidhuber主张自己更早提出了相关概念。

最近,Apollo Research团队发布了一项令人深思的研究。这项研究揭示了一个惊人的发现:当前主流的前沿AI模型已经具备了基本的"策划"(Scheming)能力。

Hyper-YOLO是一种新型目标检测方法,通过超图计算增强了特征之间的高阶关联,提升了检测性能,尤其在识别复杂场景下的中小目标时表现更出色。