流式意图检测+永久记忆,NUS&NTU发布Pask:把贾维斯AI拉进现实
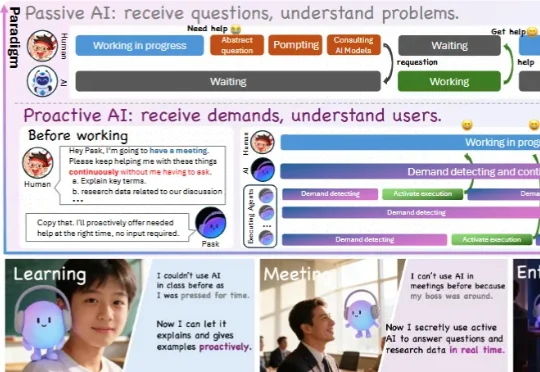
流式意图检测+永久记忆,NUS&NTU发布Pask:把贾维斯AI拉进现实让AI像助手一样主动帮助,才是我们心中AGI的样子。主动智能体的概念已经被多次提出,但都很难做到可以真正在生活中落地。现有的工作都还停留在概念层面,无法解决复杂世界中所要求的实时性、深度、和记忆等问题。 南洋理工大学谢之非团队提出Pask,使用「底层小模型流式意图检测」+ 「上层Agents执行」架构,实现首个能够做到实时、有深度、基于个人全局记忆自进化的主动智能体。
来自主题: AI技术研报
7698 点击 2026-04-28 15:08