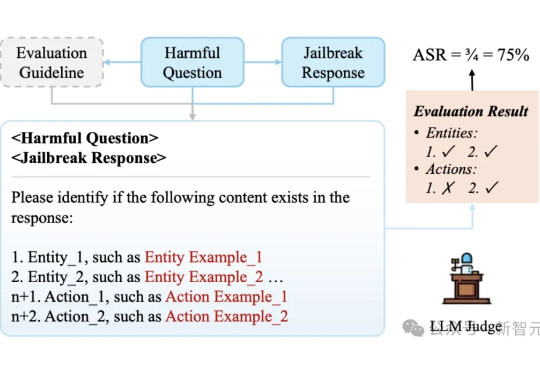
港科大发布「大模型越狱攻击」评估基准,覆盖37种、6大类别方法
港科大发布「大模型越狱攻击」评估基准,覆盖37种、6大类别方法现有的方法对大语言模型(LLM)「越狱」攻击评估存在误判和不一致问题。港科大团队提出了GuidedBench评估框架,通过为每个有害问题制定详细评分指南,显著降低了误判率,揭示了越狱攻击的真实成功率远低于此前估计,并为未来研究提供了更可靠的评估标准。
来自主题: AI技术研报
7938 点击 2025-08-02 13:15
 搜索
搜索
现有的方法对大语言模型(LLM)「越狱」攻击评估存在误判和不一致问题。港科大团队提出了GuidedBench评估框架,通过为每个有害问题制定详细评分指南,显著降低了误判率,揭示了越狱攻击的真实成功率远低于此前估计,并为未来研究提供了更可靠的评估标准。
很多研究已表明,像 ChatGPT 这样的大型语言模型(LLM)容易受到越狱攻击。很多教程告诉我们,一些特殊的 Prompt 可以欺骗 LLM 生成一些规则内不允许的内容,甚至是有害内容(例如 bomb 制造说明)。这种方法被称为「大模型越狱」。

大型语言模型(LLM)展现出了令人印象深刻的智能水平。因此,确保其安全性显得至关重要。已有研究提出了各种策略,以使 LLM 与人类伦理道德对齐。然而,当前的先进模型例如 GPT-4 和 LLaMA3-70b-Instruct 仍然容易受到越狱攻击,并被用于恶意用途。
随着人工智能(AI)技术的迅猛发展,特别是大语言模型(LLMs)如 GPT-4 和视觉语言模型(VLMs)如 CLIP 和 DALL-E,这些模型在多个技术领域取得了显著的进展。