ICCV 2025 Highlight | 3D真值生成新范式,开放驾驶场景的语义Occupancy自动化标注!
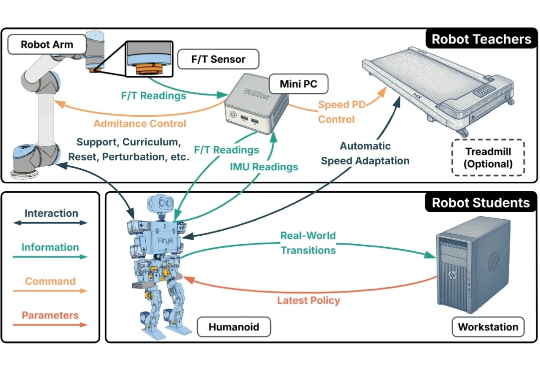
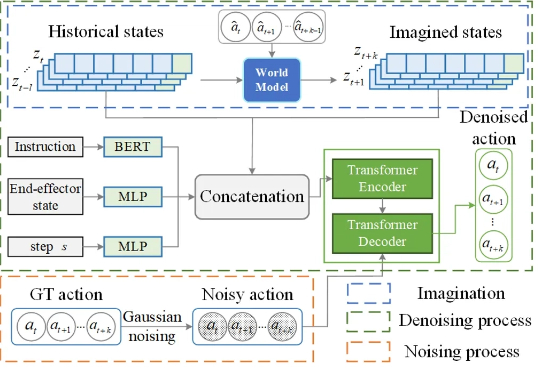
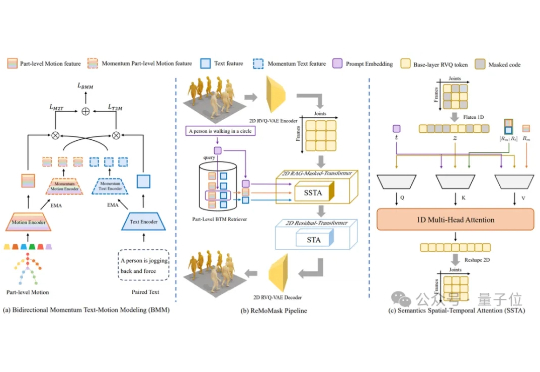
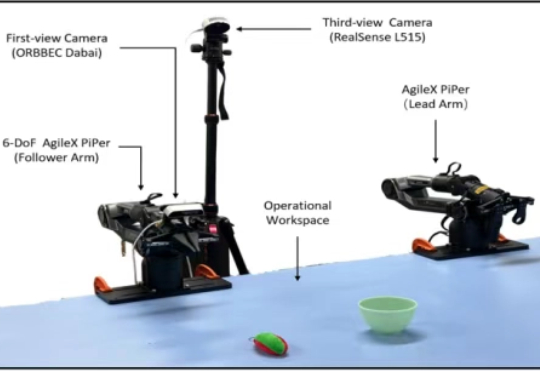
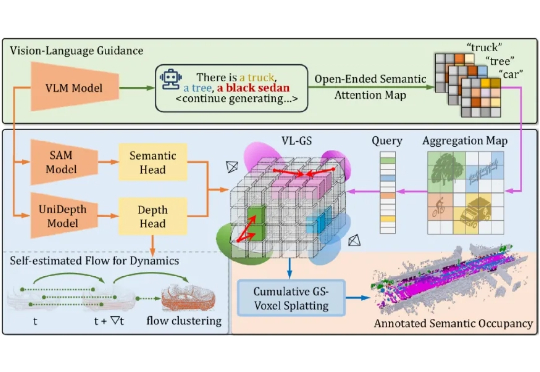
ICCV 2025 Highlight | 3D真值生成新范式,开放驾驶场景的语义Occupancy自动化标注!本文介绍了来自北京大学王选计算机研究所王勇涛团队及合作者的最新研究成果 AutoOcc。针对开放自动驾驶场景,该篇工作提出了一个高效、高质量的 Open-ended 三维语义占据栅格真值标注框架,无需任何人类标注即可超越现有语义占据栅格自动化标注和预测管线,并展现优秀的通用性和泛化能力,论文已被 ICCV 2025 录用为 Highlight。
来自主题: AI技术研报
8951 点击 2025-08-29 11:42