
单向VLM变双向!人大斯坦福等提出MoCa框架:双向多模态编码器
单向VLM变双向!人大斯坦福等提出MoCa框架:双向多模态编码器MoCa框架把单向视觉语言模型转化为双向多模态嵌入模型,通过持续预训练和异构对比微调,提升模型性能和泛化能力,在多模态基准测试中表现优异,尤其小规模模型性能突出。
来自主题: AI技术研报
10542 点击 2025-07-11 10:09
 搜索
搜索
MoCa框架把单向视觉语言模型转化为双向多模态嵌入模型,通过持续预训练和异构对比微调,提升模型性能和泛化能力,在多模态基准测试中表现优异,尤其小规模模型性能突出。
如今的视觉语言模型 (VLM, Vision Language Models) 已经在视觉问答、图像描述等多模态任务上取得了卓越的表现。然而,它们在长视频理解和检索等长上下文任务中仍表现不佳。
迈向通用人工智能(AGI)的核心目标之一就是打造能在开放世界中自主探索并持续交互的智能体。随着大语言模型(LLMs)和视觉语言模型(VLMs)的飞速发展,智能体已展现出令人瞩目的跨领域任务泛化能力。
总是“死记硬背”“知其然不知其所以然”?
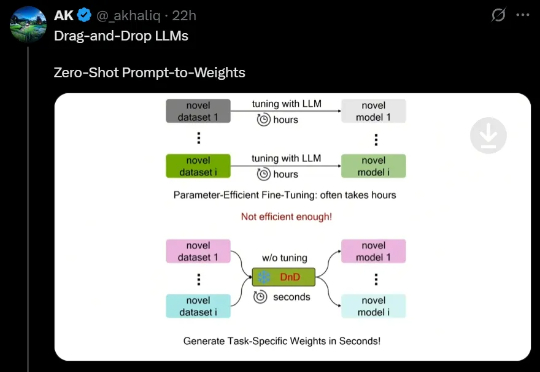
最近,来自NUS、UT Austin等机构的研究人员创新性地提出了一种「拖拽式大语言模型」(DnD),它可以基于提示词快速生成模型参数,无需微调就能适应任务。不仅效率最高提升12000倍,而且具备出色的零样本泛化能力。

关于大模型产生幻觉这个事,从2023年GPT火了以后,就一直是业界津津乐道的热门话题,但始终缺乏系统性的重磅研究来深入解释其根本机制。今天,伯克利的研究者们带来一个重要研究成果:让基于Transformer架构的语言模型产生幻觉的机制,恰恰也是让它们拥有超强泛化能力的关键。这就像是一枚硬币的两面,您想要哪一面,就得接受另一面的存在。

近期,人工智能领域对“具身智能”的讨论持续升温——如何让AI不仅能“理解”语言,还能用“手”去感知世界、操作环境、完成任务?相比语言模型的迅猛发展,真正通向Agent的下一步,需要AI具备跨模态感知、动作控制与现实泛化能力。具身智能让AI不仅能“思考”,更能“感知”“行动”。
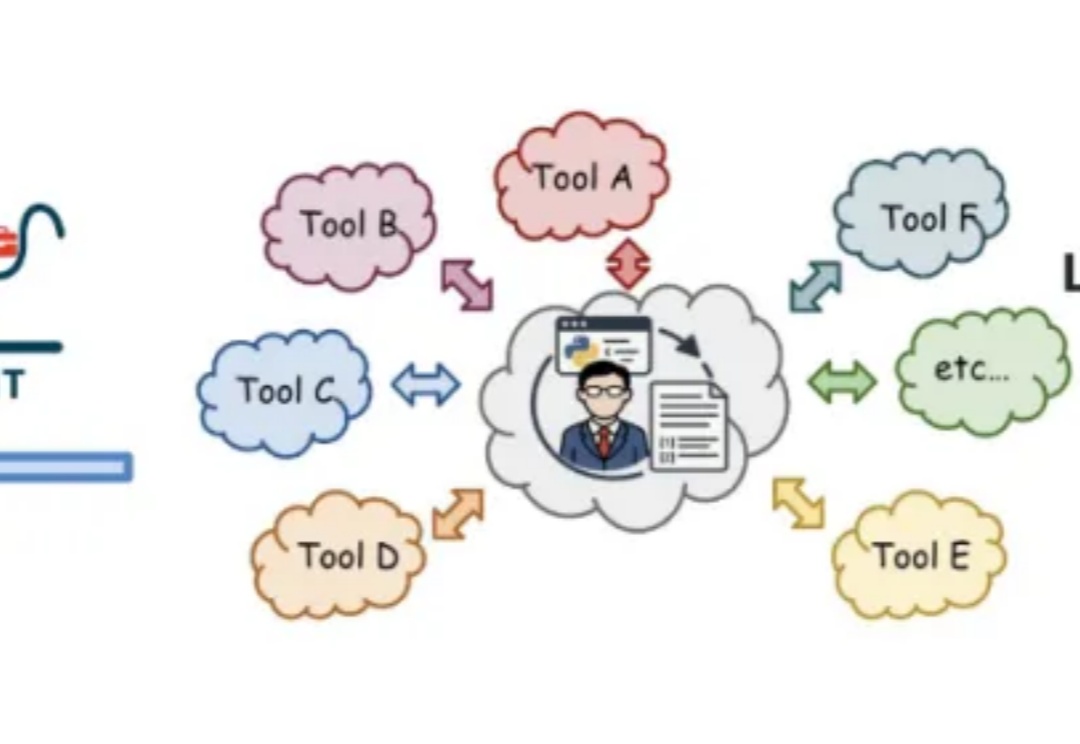
智能体技术日益发展,但现有的许多通用智能体仍然高度依赖于人工预定义好的工具库和工作流,这极大限制了其创造力、可扩展性与泛化能力。

开发能在开放世界中完成多样任务的通用智能体,是AI领域的核心挑战。开放世界强调环境的动态性及任务的非预设性,智能体必须具备真正的泛化能力才能稳健应对。然而,现有评测体系多受限于任务多样化不足、任务数量有限以及环境单一等因素,难以准确衡量智能体是否真正「理解」任务,或仅是「记住」了特定解法。

具身智能最大的挑战在于泛化能力,即在陌生环境中正确完成任务。最近,Physical Intelligence推出全新的π0.5 VLA模型,通过异构任务协同训练实现了泛化,各种家务都能拿捏。