

人形机器人觉醒之年?2024年十大机器人盘点:理想很美好现实很骨感
人形机器人觉醒之年?2024年十大机器人盘点:理想很美好现实很骨感随着AI时代的到来,算法、大模型、深度学习等技术飞速发展,使得人形机器人成为了面向未来的黄金赛道。
来自主题: AI资讯
5923 点击 2025-01-03 11:34
随着AI时代的到来,算法、大模型、深度学习等技术飞速发展,使得人形机器人成为了面向未来的黄金赛道。

AI末日将近? 深度学习三巨头之一、被称为AI教父的Hinton教授在最新演讲中指出,技术的发展速度远远超出了他的预期,如果再不加以监管人类将会在10年内灭绝

印度最大的癌症护理网络 —— 健康全球企业(HCG)近日宣布与全球知名咨询公司埃森哲建立战略合作关系,旨在利用生成性人工智能和深度学习技术,推动癌症研究和治疗的创新。
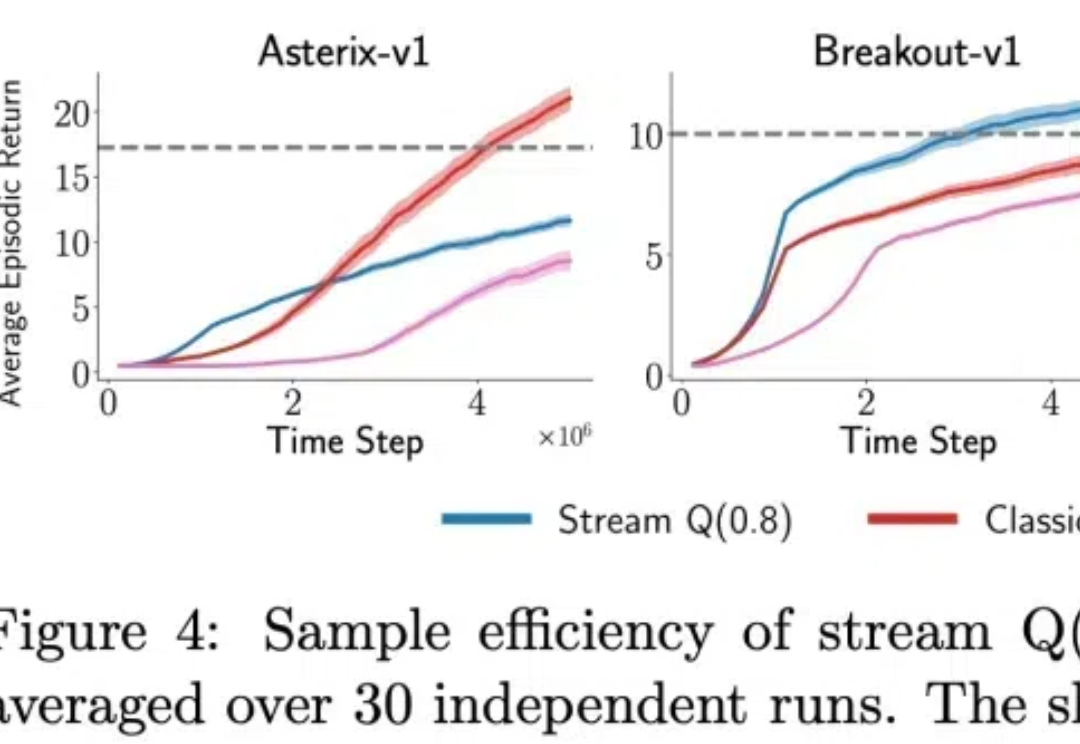
自然智能(Natural intelligence)过程就像一条连续的流,可以实时地感知、行动和学习。流式学习是 Q 学习和 TD 等经典强化学习 (RL) 算法的运作方式,它通过使用最新样本而不存储样本来模仿自然学习。这种方法也非常适合资源受限、通信受限和隐私敏感的应用程序。

刚刚,谷歌官方宣布了一条重磅消息: Keras之父François Chollet,正式离职。

随着人形机器人技术的迅猛发展,如何有效获取高质量的操作数据成为核心挑战。鉴于人类操作行为的复杂性和多样性,如何从真实世界中精准捕捉手与物体交互的完整状态,成为推动人形机器人操作技能学习的关键所在。

在人工智能(AI)领域,特别是深度学习和神经网络训练中,GPU(图形处理单元)已经成为不可或缺的硬件。但为什么AI对GPU的要求高,而不是CPU(中央处理单元)呢?让我们通过一个生动的比喻来揭开这个谜团。

今年诺贝尔奖颁给AI,是诺奖委员会感到压力的结果,需要承认深度学习的影响。 但物理奖颁给Hinton和Hopefield,获奖成果玻尔兹曼机和Hopefield网络现在完全无用。

近日,深度学习三巨头之一的Yoshua Bengio,带领团队推出了全新的RNN架构,以大道至简的思想与Transformer一较高下。

前不久在人工智能的帮助下,两位科学家获得了诺贝尔物理学奖。可以说人工智能已经在很多领域被广泛应用了。随着大语言模型(LLM)和深度学习的广泛应用,GPU 也已成为机器学习工程师和研究人员最重要的计算资源之一。