
ICML 2026 | 只用少量Thinking Tokens,大模型依然能深度思考
ICML 2026 | 只用少量Thinking Tokens,大模型依然能深度思考近年来,Chain-of-Thought(CoT)推理已经成为提升大语言模型和多模态大语言模型复杂问题求解能力的重要技术路径。
来自主题: AI技术研报
7051 点击 2026-05-19 10:01
 搜索
搜索
近年来,Chain-of-Thought(CoT)推理已经成为提升大语言模型和多模态大语言模型复杂问题求解能力的重要技术路径。
过去一年,整个 AI 行业都在告诉你:让模型多想一会儿,答案更好。但一批 GPT-5.5 重度用户刚刚用实战经验打了所有人的脸——thinking 开低、甚至不开,反而更稳更快更能打。
《读佳》获悉,搜狐于近日推出全场景多功能AI助手"小狐",该产品提供智能、高效、个性化的AI服务体验,覆盖生活、学习和工作场景。小狐拥有"快速响应"与"深度思考"双模式——前者追求速度,后者追求质量。

前面已经说了,传统自回归就像打字机一样,一次只能处理一个token,且必须按照从左到右的顺序。但扩散模型Mercury 2的工作方式更像一位编辑——最终,Mercury 2能将生成速度提升5倍以上,且速度曲线截然不同。
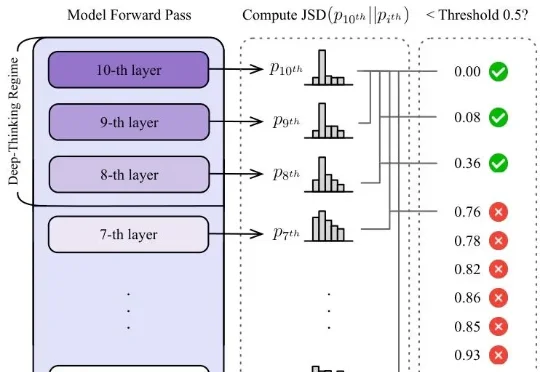
大模型的思维链越长,推理能力就越强?谷歌Say No——token数量和推理质量,真没啥正相关,因为token和token还不一样,有些纯凑数,深度思考token才真有用。新研究抛弃字数论,甩出衡量模型推理质量的全新标准DTR,专门揪模型是在真思考还是水字数。

当地时间 2 月 19 日,Google 曝光 Gemini 3.1 Pro 最新模型。在 ARC-AGI-2 这个公认的推理基准测试中,Gemini 3.1 Pro 拿到了 77.1% 的分数。什么概念?它的前辈 Gemini 3 Pro 只有 31.1%,就连专门用来「深度思考」的 Gemini 3 Deep Think 也只有 45.1%。
万亿级思考模型在开源!Ring-2.5-1T重磅出世,夺下IMO金牌。全新Ling 2.5架构,让它具备了深度思考、长程执行强大能力,真正进化为「通用智能体时代」的基座。

作为腾讯 CodeBuddy 的第一位产品经理和现任 T12 级技术产品专家,我想分享近期对于 AI Coding 产品的深度思考和趋势洞察。本次分享不仅限于 AI Coding 本身,更希望提供一套通用的方法论——当你拿到任何 AI 产品命题时,应该如何系统性地思考和推进。
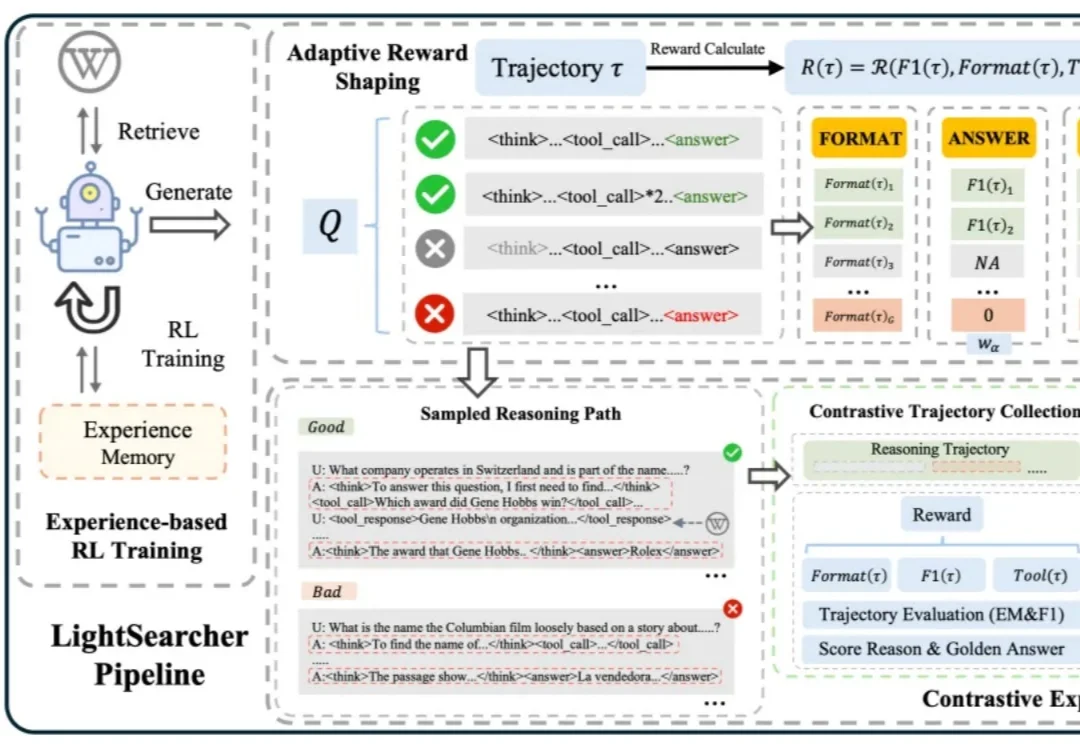
如今,以 DeepSeek-R1 为代表的深度思考大模型能够处理复杂的推理任务,而DeepSearch 作为深度思考大模型的核心搜索器,在推理过程中通过迭代调用外部搜索工具,访问参数边界之外的最新、领域特定知识,从而提升推理的深度和事实可靠性。
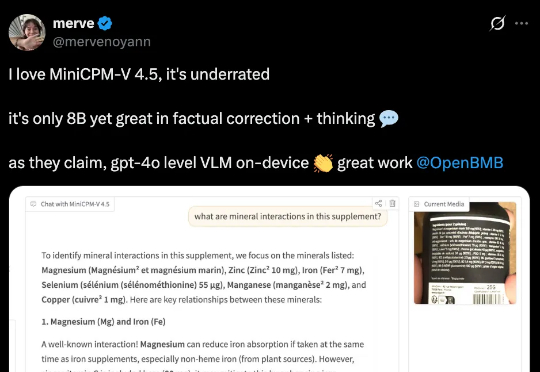
行业首个具备“高刷”视频理解能力的多模态模型MiniCPM-V 4.5的技术报告正式发布!报告提出统一的3D-Resampler架构实现高密度视频压缩、面向文档的统一OCR和知识学习范式、可控混合快速/深度思考的多模态强化学习三大技术。