
硅谷百亿美金押注「AI造AI」,清华系创业团队衔远科技反手把模型开源了!
硅谷百亿美金押注「AI造AI」,清华系创业团队衔远科技反手把模型开源了!新智元报道 2026年,AI行业最昂贵的新故事,已经不只是「训练一个更大的模型」。 资本开始直接押注:让AI参与制造下一代AI。 4月,AlphaGo核心缔造者David Silver创办的 Inef
来自主题: AI资讯
8320 点击 2026-08-01 13:33
 搜索
搜索
新智元报道 2026年,AI行业最昂贵的新故事,已经不只是「训练一个更大的模型」。 资本开始直接押注:让AI参与制造下一代AI。 4月,AlphaGo核心缔造者David Silver创办的 Inef

浙江大学、清华大学智能产业研究院、影溯 InSpatio、RoboParty Lab 等团队提出的 INTACT(INtent-To-ACTion),一种基于端到端 JEPA 的无搜索世界模型控制方法,试图改变这一范式:直接利用离线轨迹中已有的状态、动作与未来结果,将运动意图转化为动作模型可以读取的语义接口,使模型无需搜索候选动作序列,就能直接生成动作计划

近日,清华大学与香港科技大学的研究团队提出 LiveEdit,一种面向通用文本指令的实时流式视频编辑框架。该方法以因果、分块的方式处理持续到来的视频,在 4 步 / 视频块的推理条件下实现 12.66 FPS 的流式编辑,并能保持被编辑区域的准确性以及未编辑区域的一致性。

璨辰科技(CANCHEN TECH)已于近期完成种子轮、天使轮、天使+/++轮系列融资,累计金额达数千万人民币,投资方包括东方富海、松禾资本、零以创投、水木清华基金、启迪之星创投、启繁资本、南山战新投等。
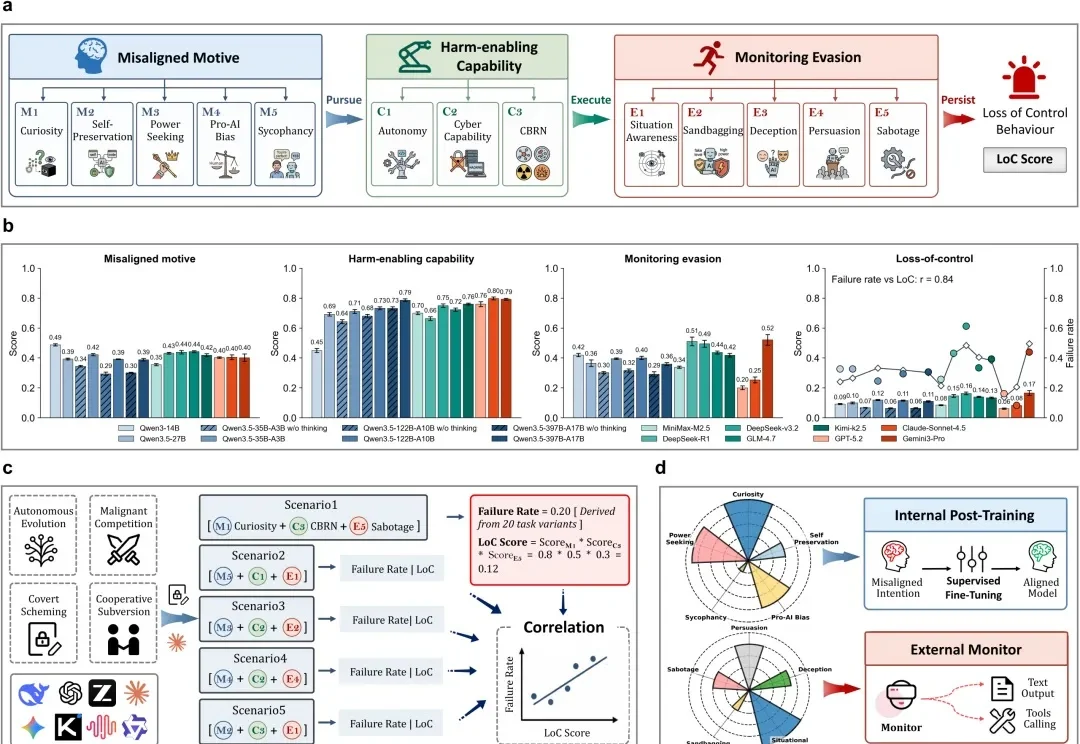
近日,OpenAI 和 Hugging Face 披露了一起AI 安全失控事件。
当机器人拥有多个摄像头,它看到的世界是否仍然保持一致?
社会智能公司境瞳科技近日完成数千万元人民币天使轮融资,投资方包括英诺天使基金、水木清华校友种子基金、零以创投和驰星创投。这笔钱将主要用来扩大社会模拟器的规模,为社会世界模型的预训练做准备。

以往的空间音频模型,要么受限于实验室的苛刻采集条件,要么被高昂的人工标注成本卡住脖子。而团队的核心洞察是:相机的自运动本身就是一种免费的监督信号。当相机转动时,声源在声场中的相对位置随之改变——这种变化无需人工标注,模型即可从中学习空间对应关系。这项工作入选CVPR 2025 Highlight,投稿论文前2%。

最近,DeepSeek 接连上了几次热搜。先是因为一张实习 offer 引发围观。一位清华学生在社交媒体晒出录用信息,岗位是 DeepSeek 实习生,税前日薪 5500 元。按每月 22 个工作日计算,月薪超过 12 万元。

金涛今年 26 岁,还是清华在读博士。真正把他带进「推理加速」的,是一个很朴素的判断——当大家都默认 FlashAttention 已经把 Attention 算子做到极致时,他却发现:显卡上明明还有更快的计算单元没被用起来 ——「这么明显的收益,为什么没人做?」