AAAI 2026 Oral | 告别注意力与热传导!北大清华提出WaveFormer,首创波动方程建模视觉
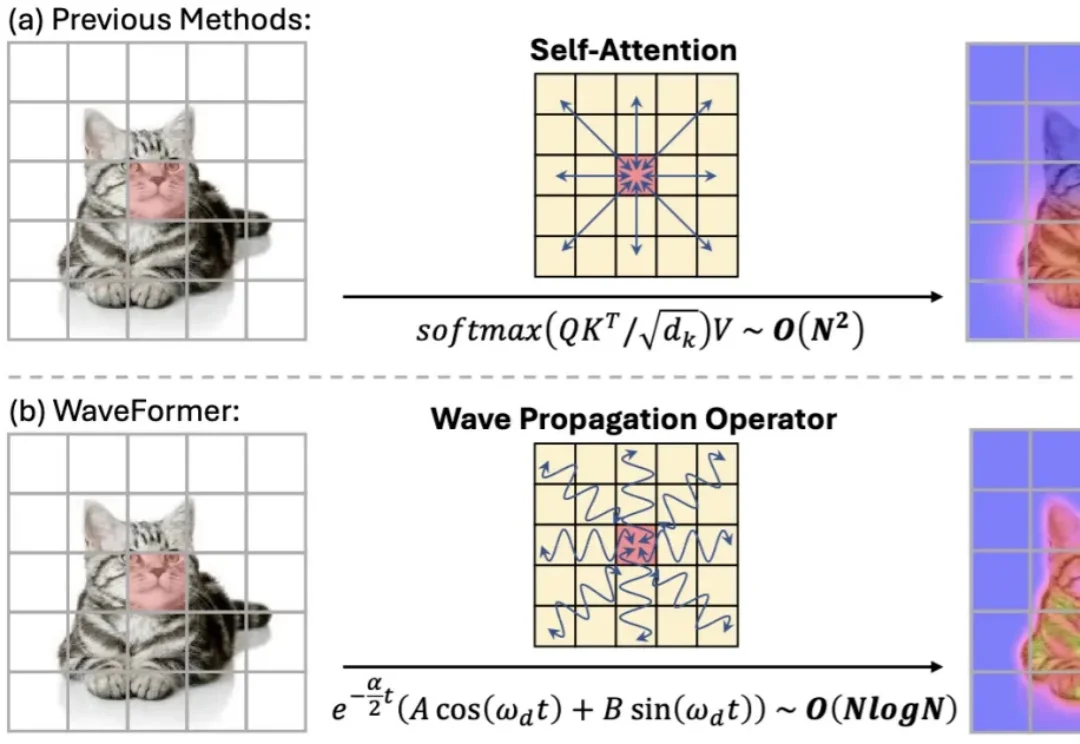
AAAI 2026 Oral | 告别注意力与热传导!北大清华提出WaveFormer,首创波动方程建模视觉“全局交互” 几乎等同于 self-attention:每个 token 都能和所有 token 对话,效果强,但代价也直观 —— 复杂度随 token 数平方增长,分辨率一高就吃不消。现有方法大多从 “相似度匹配” 出发(attention),或从 “扩散 / 传导” 出发(热方程类方法)。但热方程本质上是一个强低通滤波器:随着传播时间增加,高频细节(边缘、纹理)会迅速消失,导致特征过平滑。
来自主题: AI技术研报
9401 点击 2026-01-21 10:39