

注意力机制大变革?Bengio团队找到了一种超越Transformer的硬件对齐方案
注意力机制大变革?Bengio团队找到了一种超越Transformer的硬件对齐方案Transformer 已经改变了世界,但也并非完美,依然还是有竞争者,比如线性递归(Linear Recurrences)或状态空间模型(SSM)。这些新方法希望能够在保持模型质量的同时显著提升计算性能和效率。
来自主题: AI技术研报
9316 点击 2026-01-07 17:22
Transformer 已经改变了世界,但也并非完美,依然还是有竞争者,比如线性递归(Linear Recurrences)或状态空间模型(SSM)。这些新方法希望能够在保持模型质量的同时显著提升计算性能和效率。
Mamba一作最新大发长文! 主题只有一个,即探讨两种主流序列模型——状态空间模型(SSMs)和Transformer模型的权衡之术。
当状态空间模型遇上扩散模型,对世界模型意味着什么?

Mamba 这种状态空间模型(SSM)被认为是 Transformer 架构的有力挑战者。近段时间,相关研究成果接连不断。而就在不久前,Mamba 作者 Albert Gu 与 Karan Goel、Chris Ré、Arjun Desai、Brandon Yang 一起共同创立的 Cartesia 获得 2700 万美元种子轮融资。
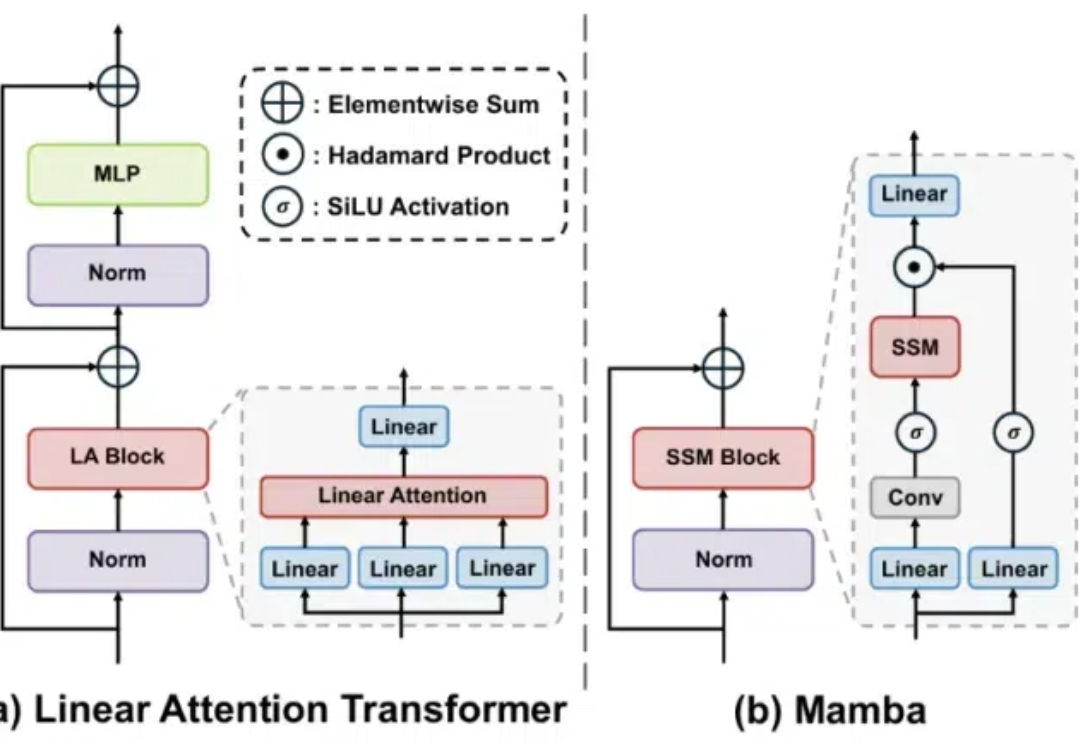
Mamba 是一种具有线性计算复杂度的状态空间模型,它能够以线性计算复杂度实现对输入序列的有效建模,在近几个月受到了广泛的关注。

探索视频理解的新境界,Mamba 模型引领计算机视觉研究新潮流!传统架构的局限已被打破,状态空间模型 Mamba 以其在长序列处理上的独特优势,为视频理解领域带来了革命性的变革。

Transformers 的二次复杂度和弱长度外推限制了它们扩展到长序列的能力,虽然存在线性注意力和状态空间模型等次二次解决方案
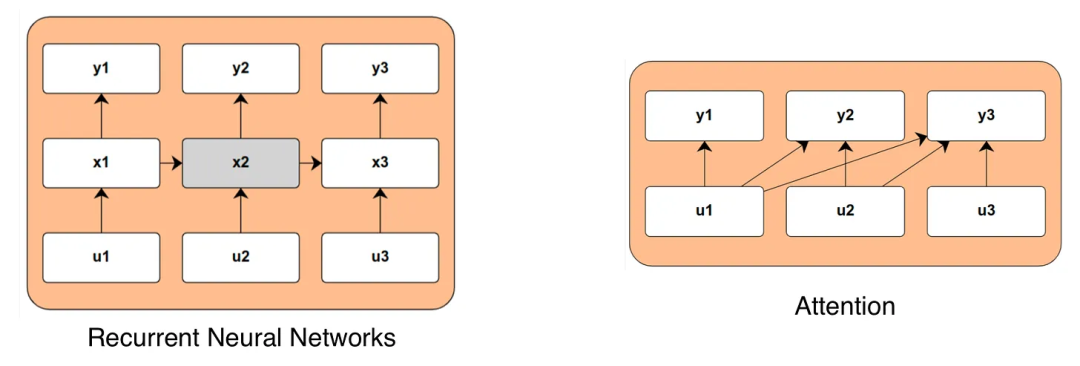
状态空间模型正在兴起,注意力是否已到尽头?

状态空间模型(SSM)是近来一种备受关注的 Transformer 替代技术,其优势是能在长上下文任务上实现线性时间的推理、并行化训练和强大的性能。而基于选择性 SSM 和硬件感知型设计的 Mamba 更是表现出色,成为了基于注意力的 Transformer 架构的一大有力替代架构。

现在ChatGPT等大模型一大痛点:处理长文本算力消耗巨大,背后原因是Transformer架构中注意力机制的二次复杂度。