Wan2.5+Midjourney V7,阿里夸克这个新AI鲨疯了!价格还砍一大刀
Wan2.5+Midjourney V7,阿里夸克这个新AI鲨疯了!价格还砍一大刀夸克“造点”AI发布了!直接上大招,Wan2.5+Midjourney V7双强模型联合!夸克“造点”还在今天第一时间,率先接入了阿里自家刚刚发布的视频生成模型通义万相Wan2.5,甚至直接开放了7天免费体验。
来自主题: AI资讯
10601 点击 2025-09-25 11:37
 搜索
搜索
夸克“造点”AI发布了!直接上大招,Wan2.5+Midjourney V7双强模型联合!夸克“造点”还在今天第一时间,率先接入了阿里自家刚刚发布的视频生成模型通义万相Wan2.5,甚至直接开放了7天免费体验。

刚刚,快手可灵AI基座模型再升级,推出可灵2.5 Turbo视频生成模型。AI视频玩家抹一把老泪,终于有AI视频模型让运动员们拥有不鬼畜自由了!a16z合伙人在𝕏上分享了一个可灵2.5 Turbo生成的视频:
深夜,阿里通义大模型团队连放三个大招:开源原生全模态大模型Qwen3-Omni、语音生成模型Qwen3-TTS、图像编辑模型Qwen-Image-Edit-2509更新。Qwen3-Omni能无缝处理文本、图像、音频和视频等多种输入形式,并通过实时流式响应同时生成文本与自然语音输出。
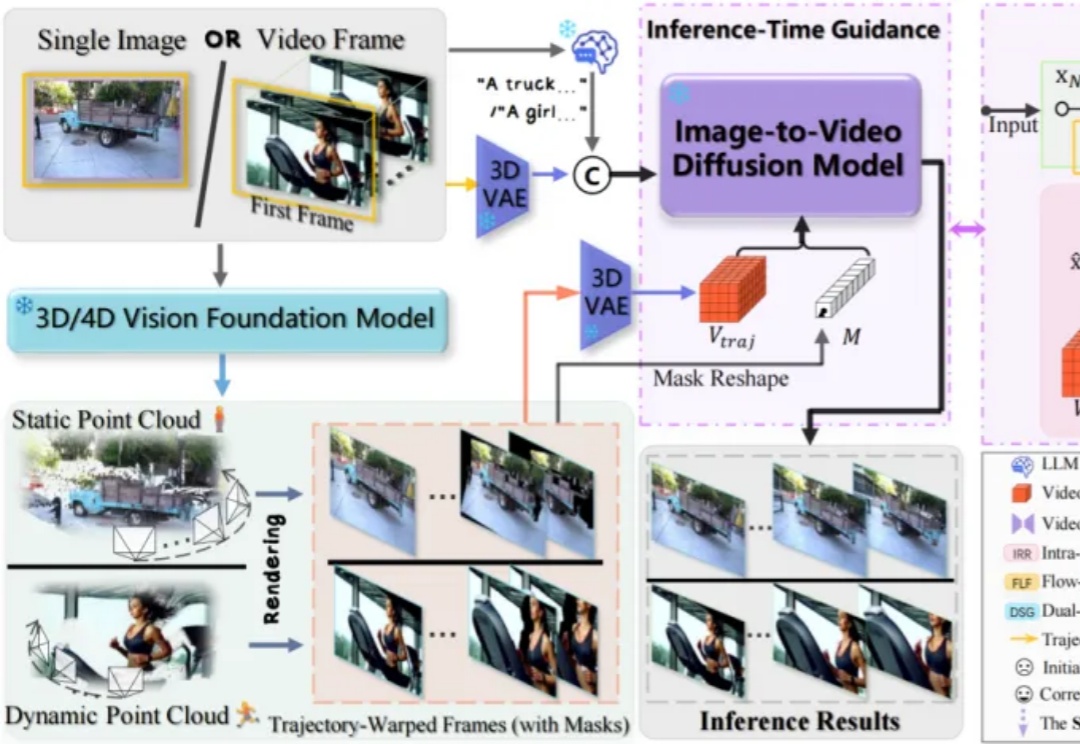
近来,由AI生成的视频片段以前所未有的视觉冲击力席卷了整个互联网,视频生成模型创造出了许多令人惊叹的、几乎与现实无异的动态画面。
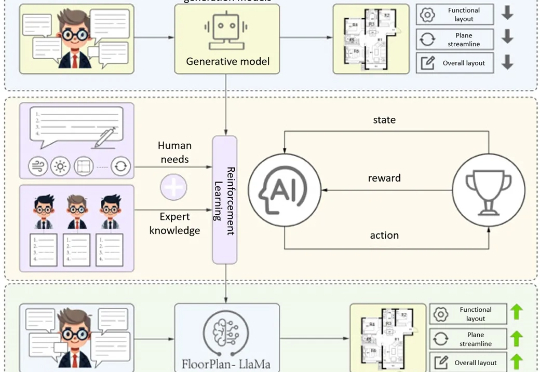
清华大学最新提出的建筑专业知识驱动的平面图自动生成方案FloorPlan-LLaMa,解决传统模型「指标优秀但实际不可用」 痛点,让AI生成贴合建筑师设计偏好的可行方案。

随着内容创作智能化需求的爆发,长时长、高质量数字人视频生成始终是行业痛点。近日,字节跳动商业化 GenAI 团队联合浙江大学推出商用级长时序音频驱动人物视频生成模型 ——InfinityHuman,打破传统音频驱动技术在长视频场景中的局限性,开启 AI 数字人实用化新征程
自带声音的视频生成模型,开源版开卷! 最新赶到的是腾讯混元:刚刚正式开源端到端的视频音效生成模型HunyuanVideo-Foley。

传统 video dubbing 技术长期受限于其固有的 “口型僵局”,即仅能编辑嘴部区域,导致配音所传递的情感与人物的面部、肢体表达严重脱节,削弱了观众的沉浸感。现有新兴的音频驱动视频生成模型,在应对长视频序列时也暴露出身份漂移和片段过渡生硬等问题。

最近3D内容生成模型好生热闹,像谷歌Genie 3、World Labs、混元、昆仑争相发布并开测世界模型。

百度最新视频生成模型蒸汽机2.0(MuseSteamer 2.0),好像真的有点东西。