
何恺明NeurIPS 2025演讲盘点:视觉目标检测三十年
何恺明NeurIPS 2025演讲盘点:视觉目标检测三十年不久前,NeurIPS 2025 顺利举办,作为人工智能学术界的顶级会议之一,其中不乏学术界大佬的工作和演讲。
来自主题: AI技术研报
10948 点击 2025-12-12 09:36
 搜索
搜索
不久前,NeurIPS 2025 顺利举办,作为人工智能学术界的顶级会议之一,其中不乏学术界大佬的工作和演讲。
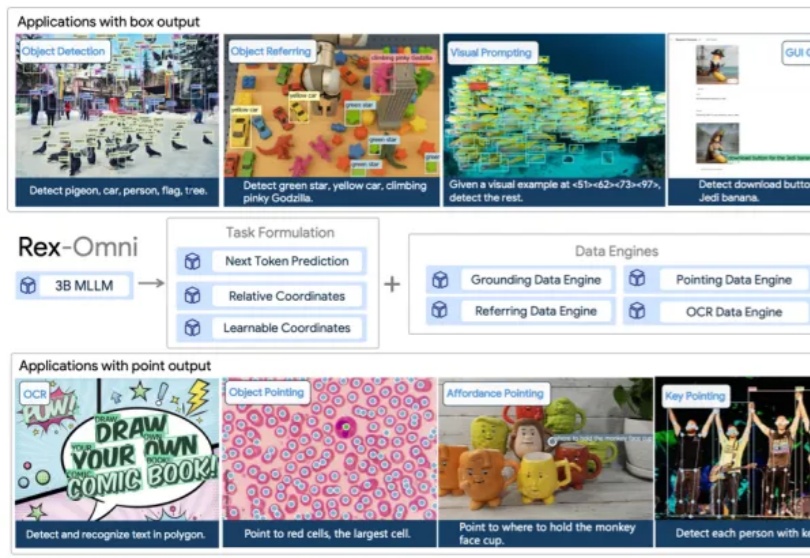
多模态大语言模型(MLLM)在目标定位精度上被长期诟病,难以匹敌传统的基于坐标回归的检测器。近日,来自 IDEA 研究院的团队通过仅有 3B 参数的通用视觉感知模型 Rex-Omni,打破了这一僵局。

近年来,多模态大语言模型(Multimodal Large Language Models, MLLMs)在图文理解、视觉问答等任务上取得了令人瞩目的进展。然而,当面对需要精细空间感知的任务 —— 比如目标检测、实例分割或指代表达理解时,现有模型却常常「力不从心」。
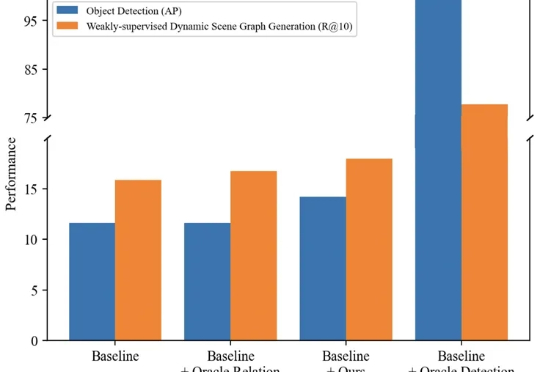
本文主要介绍来自该团队的最新论文:TRKT,该任务针对弱监督动态场景图任务展开研究,发现目前的性能瓶颈在场景中目标检测的质量,因为外部预训练的目标检测器在需要考虑关系信息和时序上下文的场景图视频数据上检测结果欠佳。
在日常生活中,我们常通过语言描述寻找特定物体:“穿蓝衬衫的人”“桌子左边的杯子”。如何让 AI 精准理解这类指令并定位目标,一直是计算机视觉的核心挑战。
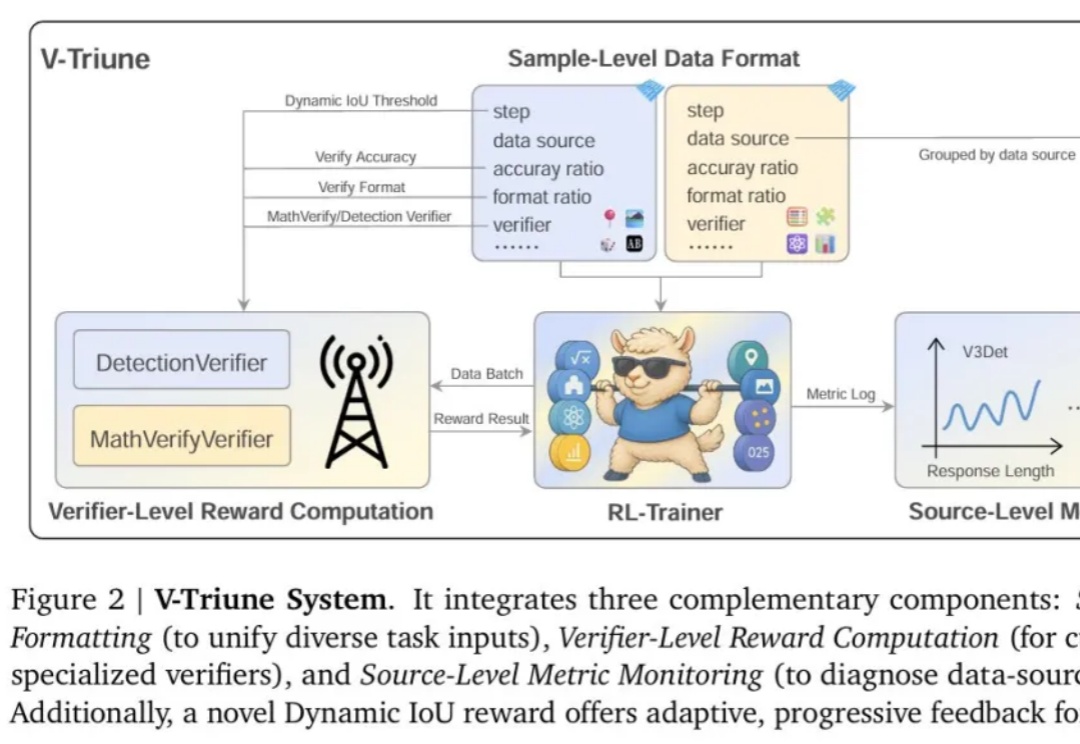
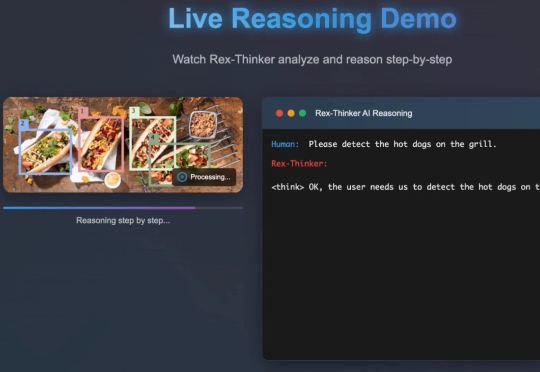
强化学习 (RL) 显著提升了视觉-语言模型 (VLM) 的推理能力。然而,RL 在推理任务之外的应用,尤其是在目标检测 和目标定位等感知密集型任务中的应用,仍有待深入探索。
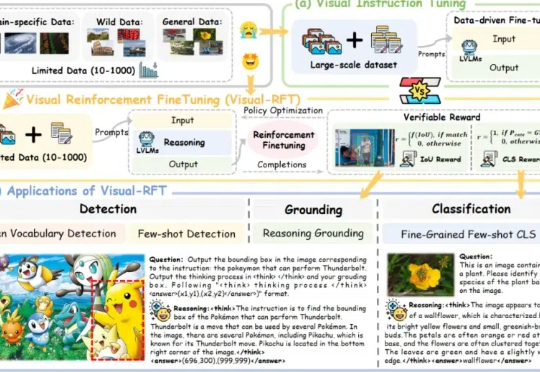
通过针对视觉的细分类、目标检测等任务设计对应的规则奖励,Visual-RFT 打破了 DeepSeek-R1 方法局限于文本、数学推理、代码等少数领域的认知,为视觉语言模型的训练开辟了全新路径!

刚刚,AI大牛吴恩达官宣创业公司新成果——Agentic Object Detection

大连理工大学的研究人员提出了一种基于Wasserstein距离的知识蒸馏方法,克服了传统KL散度在Logit和Feature知识迁移中的局限性,在图像分类和目标检测任务上表现更好。

Hyper-YOLO是一种新型目标检测方法,通过超图计算增强了特征之间的高阶关联,提升了检测性能,尤其在识别复杂场景下的中小目标时表现更出色。