
九天大模型大变身:性能狂飙35%!还能一键P大象
九天大模型大变身:性能狂飙35%!还能一键P大象九天基础大模型3.0震撼发布!在2025世界人工智能大会上,九天基础大模型端到端技术全面升级
来自主题: AI资讯
11304 点击 2025-08-04 14:35
 搜索
搜索
九天基础大模型3.0震撼发布!在2025世界人工智能大会上,九天基础大模型端到端技术全面升级
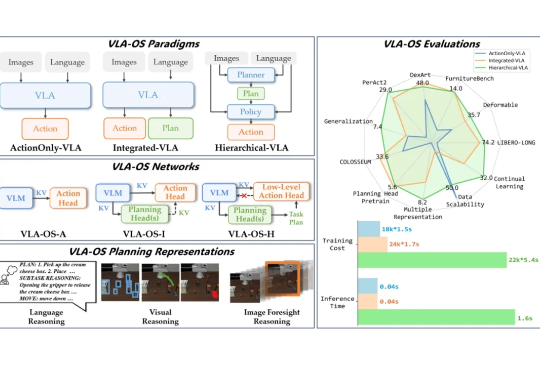
为什么机器人能听懂指令却做不对动作?语言大模型指挥机器人,真的是最优解吗?端到端的范式到底是不是通向 AGI 的唯一道路?这些问题背后,藏着机器智能的未来密码。

上海交通大学研究团队提出了一种融合无人机物理建模与深度学习的端到端方法,实现了轻量、可部署、可协同的无人机集群自主导航方案,其鲁棒性和机动性大幅领先现有方案。

3D生成又补齐了一块重要拼图——物理属性! 南洋理工大学-商汤联合研究中心S-Lab,及上海人工智能实验室合作提出了PhysXNet,号称首个系统性标注的物理基础3D数据集。
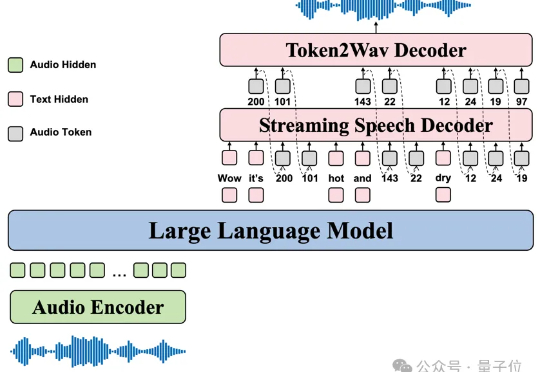
GPT-4o、Gemini这些顶级语音模型虽然展现了惊人的共情对话能力,但它们的技术体系完全闭源。
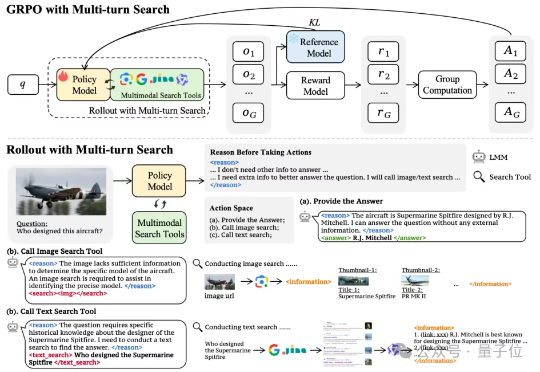
多模态模型学会“按需搜索”!字节&NTU最新研究,优化多模态模型搜索策略——通过搭建网络搜索工具、构建多模态搜索数据集以及涉及简单有效的奖励机制,首次尝试基于端到端强化学习的多模态模型自主搜索训练。
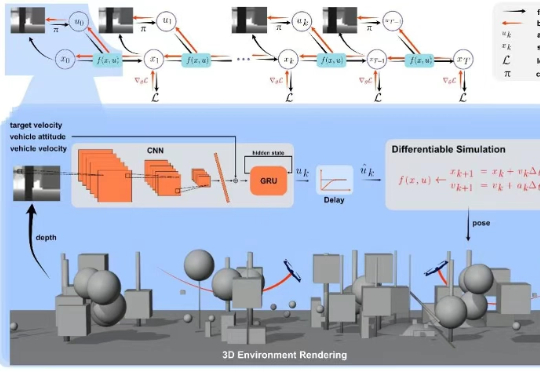
上海交通大学研究团队提出了一种融合无人机物理建模与深度学习的端到端方法,该研究首次将可微分物理训练的策略成功部署到现实机器人中,实现了无人机集群自主导航,并在鲁棒性、机动性上大幅领先现有的方案。

近年来,基于智能体的强化学习(Agent + RL)与智能体优化(Agent Optimization)在学术界引发了广泛关注。然而,实现具备工具调用能力的端到端智能体训练,首要瓶颈在于高质量任务数据的极度稀缺。
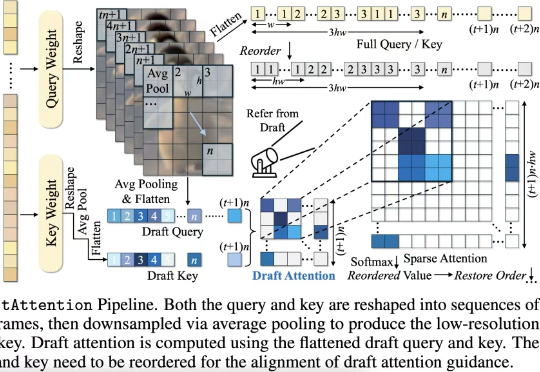
在高质量视频生成任务中,扩散模型(Diffusion Models)已经成为主流。然而,随着视频长度和分辨率的提升,Diffusion Transformer(DiT)模型中的注意力机制计算量急剧增加,成为推理效率的最大瓶颈。
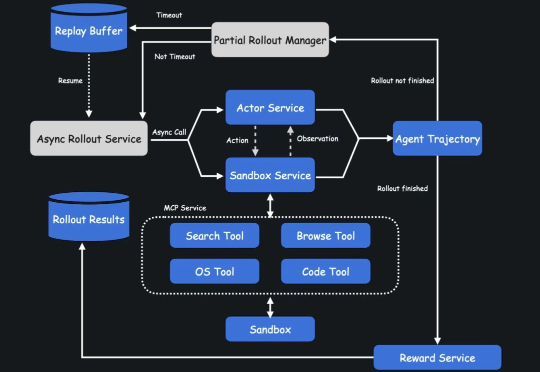
这款 Agent 擅长多轮搜索和推理,平均每项任务执行 23 个推理步骤,访问超过 200 个网址。它是基于 Kimi k 系列模型的内部版本构建,并完全通过端到端智能体强化学习进行训练,也是国内少有的基于自研模型打造的 Agent。