

“创造市场”与“算法进化”,中美AI竞速的岔路口
“创造市场”与“算法进化”,中美AI竞速的岔路口中美多维差异背后,技术落地路径已然不同。当前的全球AI市场,占据主导地位的中美双方,却也走出了两条截然不同的技术路径,前者执着于前沿技术的探索,后者则发力应用优化和商业化落地。
来自主题: AI资讯
4746 点击 2024-09-20 10:16
中美多维差异背后,技术落地路径已然不同。当前的全球AI市场,占据主导地位的中美双方,却也走出了两条截然不同的技术路径,前者执着于前沿技术的探索,后者则发力应用优化和商业化落地。

云+AI基础设施已成为企业智能化转型的关键支撑,但企业在尝试AI时,也面临包括算力、算法开发和专业人才的挑战。

本文作者来自于清华大学电子工程系,北京大学人工智能研究院、第四范式、腾讯和清华-伯克利深圳学院。其中第一作者张瑞泽为清华大学硕士,主要研究方向为博弈算法。通讯作者为清华大学电子工程系汪玉教授、于超博后和第四范式研究员黄世宇博士。
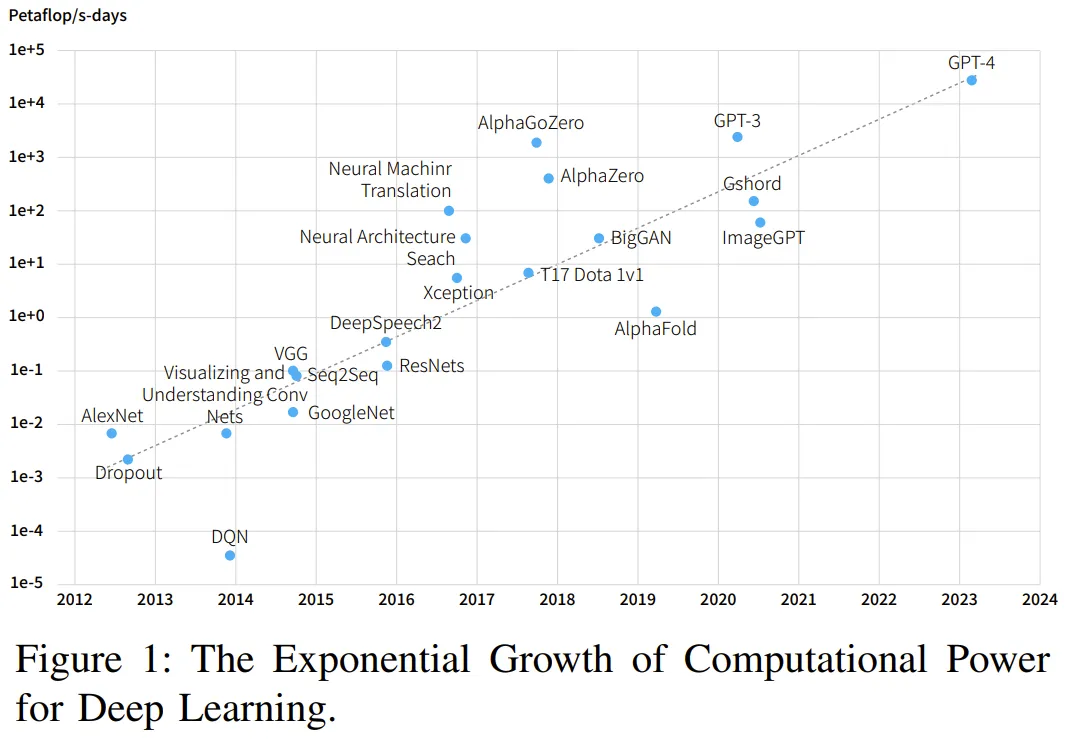
硬件发展速度跟不上 AI 需求,就需要精妙的架构和算法。

本文出自启元世界多模态算法组,共同一作是来自清华大学的一年级硕士生谢之非与启元世界多模态负责人吴昌桥,研究兴趣为多模态大模型、LLM Agents 等。本论文上线几天内在 github 上斩获 1000+ 星标。

近日,Mamba方面又搞出了有意思的研究:来自康奈尔、普林斯顿等机构的研究人员成功将Llama提炼成了Mamba模型,并且设计了新的推测解码算法,加速了模型的推理。

“发挥全球视角与专业经验,为国内产业的长足发展贡献力量。”

人工神经网络、深度学习方法和反向传播算法构成了现代机器学习和人工智能的基础。但现有方法往往是一个阶段更新网络权重,另一个阶段在使用或评估网络时权重保持不变。这与许多需要持续学习的应用程序形成鲜明对比。

为了实现算力层面的提升和追赶,国内有大量的厂商和从业者在各个产业链环节努力。但面对中短期内架构、制程、产能、出口禁令等多方面的制约,我们认为从芯片层面实现单点的突破依旧是非常困难且不足的。

随着人工智能技术的广泛应用,人们认为AI可以避免人类常见的认知偏差。然而,AI本身可能会表现出类似于人类的偏差,例如锚定效应。本文通过回顾“系统1”和“系统2”两个思维模式,探讨AI在这两种模式中的运作方式,分析AI产生认知偏差的原因,并通过具体实验展示AI在面对锚定效应时的表现。本文进一步探讨如何在理解这些局限性的基础上,合理利用AI来改善人类决策质量,并强调AI透明性和可解释性的重要性。