
挑战扩散自回归统治!字节提出视觉生成第三种路线,让模型像人类一样边画边改
挑战扩散自回归统治!字节提出视觉生成第三种路线,让模型像人类一样边画边改ber!这个五一假期,我也是真够忙的: 自拍、电影、追剧、街头采访、听音乐会,还抽空回老家结了次婚……
来自主题: AI技术研报
9348 点击 2026-05-14 09:31
 搜索
搜索
ber!这个五一假期,我也是真够忙的: 自拍、电影、追剧、街头采访、听音乐会,还抽空回老家结了次婚……
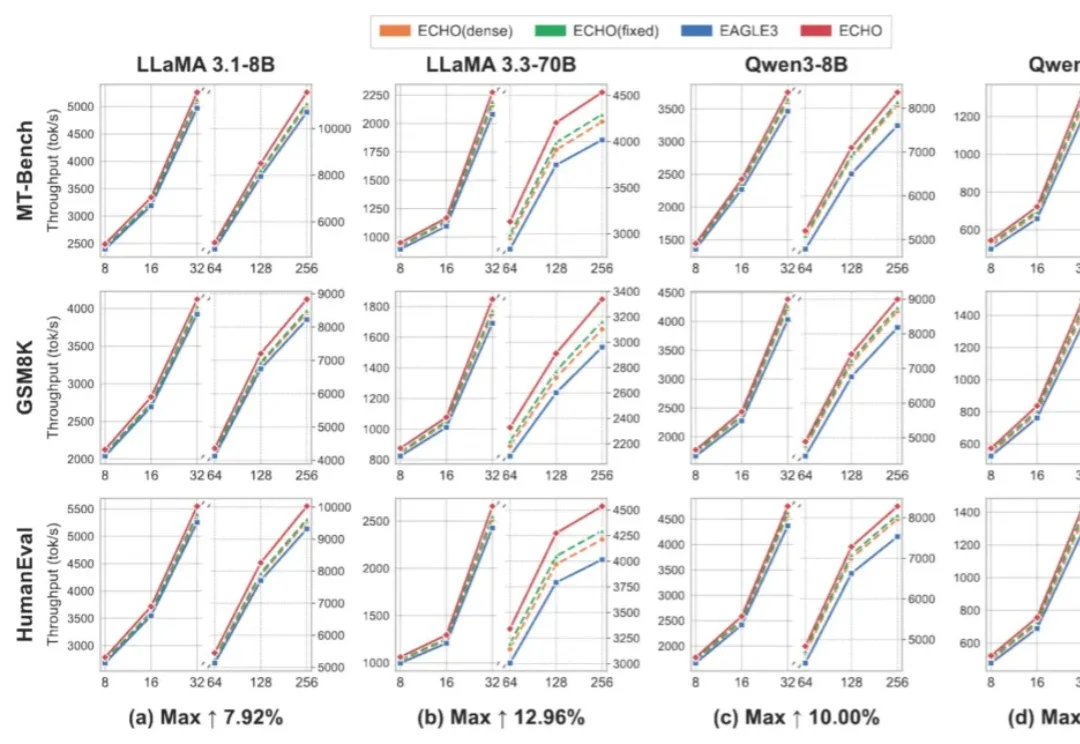
随着大模型参数规模持续扩大,推理成本已经成为生产级 LLM 服务的核心瓶颈。投机解码(Speculative Decoding, SD)通过「小模型 draft + 大模型 verify」的方式,将多个候选 token 放到一次目标模型前向中并行验证,从而缓解自回归解码的串行瓶颈。

何恺明,也下场做语言模型了。

自回归视频生成越往后越崩的问题有救了!
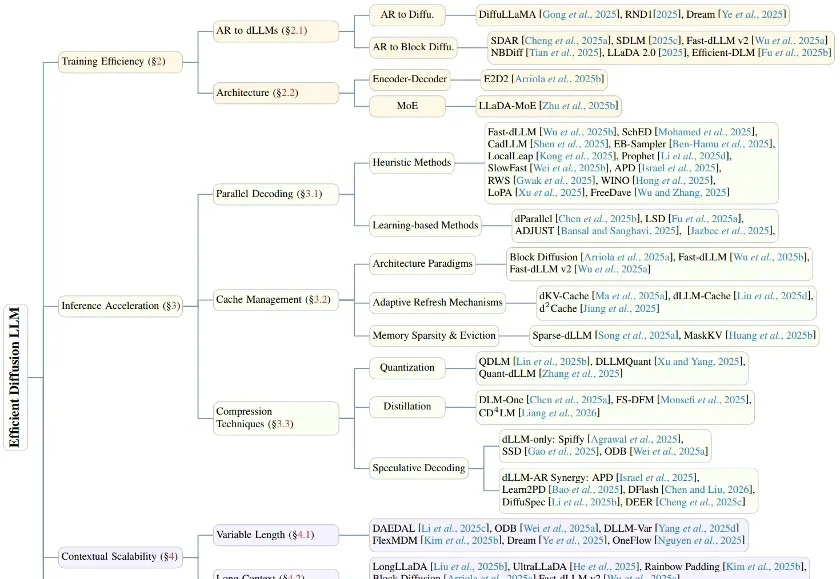
在生成式 AI 的浪潮中,自回归(Autoregressive, AR)模型凭借其卓越的性能占据了统治地位。然而,其「从左到右」逐个预测 Token 的串行机制,天生限制了并行生成的可能性。
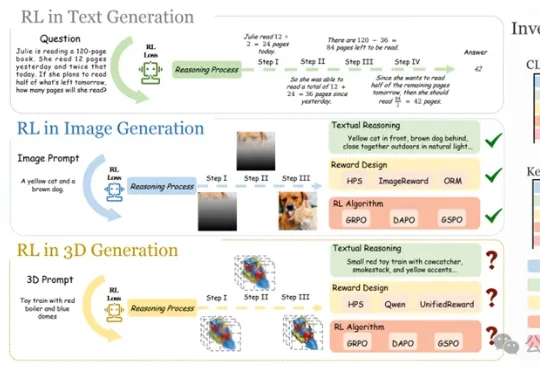
当GRPO让大模型在数学、代码推理上实现质变,研究团队率先给出答案——首个将强化学习系统性引入文本到3D自回归生成的研究正式诞生,并被CVPR 2026接收。该研究不只是简单移植2D经验,而是针对3D生成的独特挑战,从奖励设计、算法选择、评测基准到训练范式,做了一套完整的系统性探索。

前面已经说了,传统自回归就像打字机一样,一次只能处理一个token,且必须按照从左到右的顺序。但扩散模型Mercury 2的工作方式更像一位编辑——最终,Mercury 2能将生成速度提升5倍以上,且速度曲线截然不同。
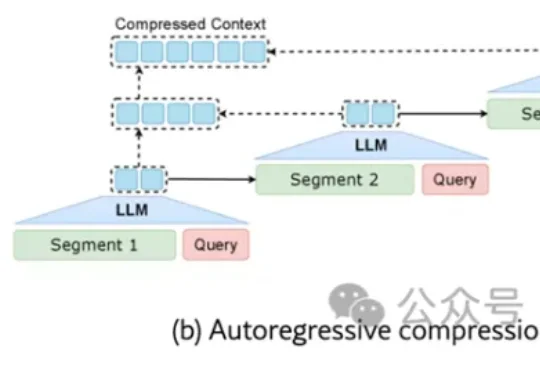
来自清华大学、鹏城实验室与阿里巴巴未来生活实验室的联合研究团队发现:现有任务相关的压缩方法不仅陷入效率瓶颈——要么一次性加载全文(效率低),要么自回归逐步压缩(速度慢),更难以兼顾“保留关键信息”与“保持自然语言可解释性”。

谁能想到啊,在自回归模型(Autoregressive,AR)当道的现在,一个非主流架构的模型突然杀了回马枪——被长期视为学术玩具的扩散语言模型,直接在复杂编程任务中飙出了892 tokens/秒的速度!
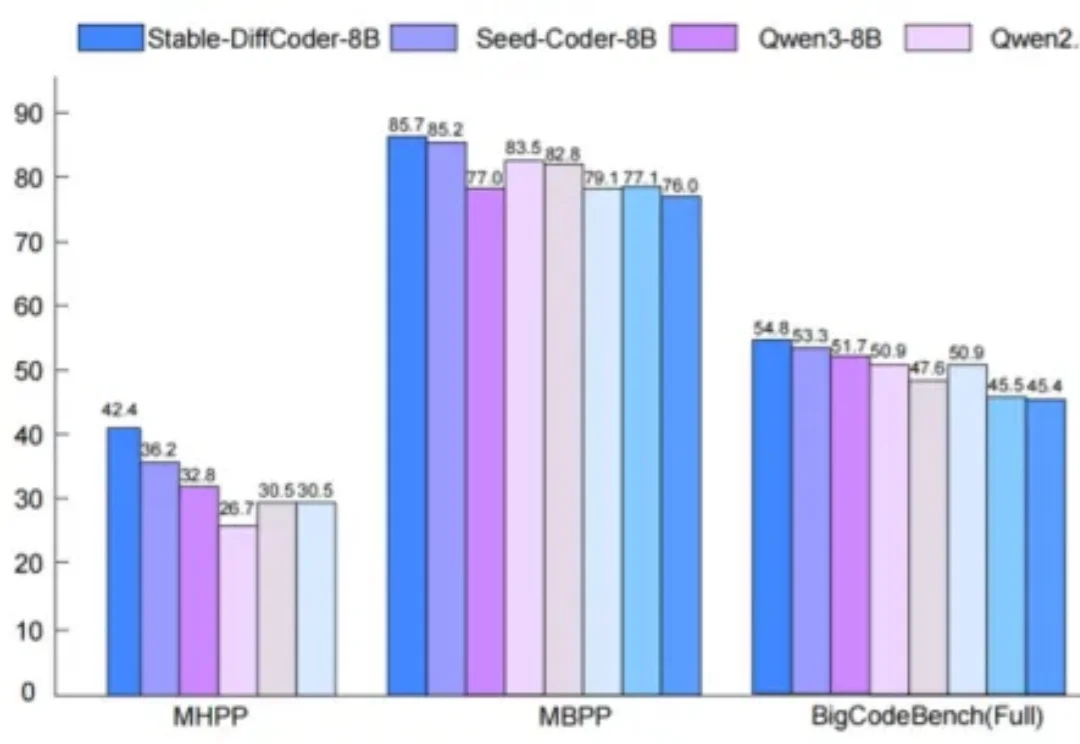
扩散语言模型(Diffusion Language Models, DLLMs)因其多种潜在的特性而备受关注,如能加速的非自回归并行生成特性,能直接起草编辑的特性,能数据增强的特性。然而,其模型能力往往落后于同等规模的强力自回归(AR)模型。