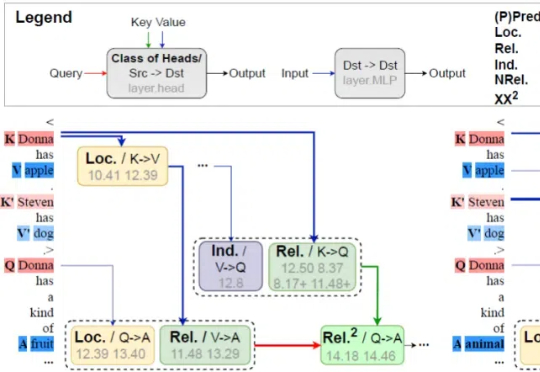
大模型会组合关系推理吗?打开黑盒,窥探Transformer脑回路
大模型会组合关系推理吗?打开黑盒,窥探Transformer脑回路本文作者为北京邮电大学网络空间安全学院硕士研究生倪睿康,指导老师为肖达副教授。主要研究方向包括自然语言处理、模型可解释性。该工作为倪睿康在彩云科技实习期间完成。联系邮箱:ni@bupt.edu.cn, xiaoda99@bupt.edu.cn
来自主题: AI技术研报
5945 点击 2025-02-06 15:30
 搜索
搜索
本文作者为北京邮电大学网络空间安全学院硕士研究生倪睿康,指导老师为肖达副教授。主要研究方向包括自然语言处理、模型可解释性。该工作为倪睿康在彩云科技实习期间完成。联系邮箱:ni@bupt.edu.cn, xiaoda99@bupt.edu.cn

当谷歌在 2018 年推出 BERT 模型时,恐怕没有料到这个 3.4 亿参数的模型会成为自然语言处理领域的奠基之作。
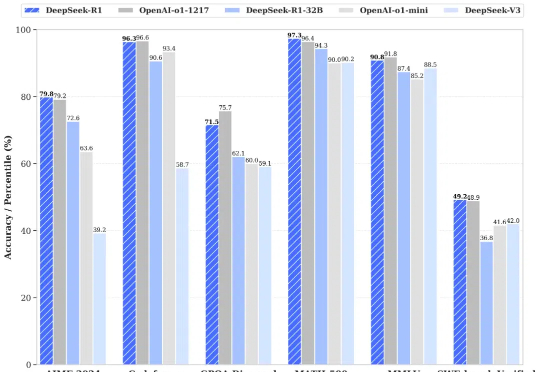
昨天晚上,DeepSeek 又开源了 DeepSeek-R1 模型(后简称 R1),再次炸翻了中美互联网: R1 遵循 MIT License,允许用户通过蒸馏技术借助 R1 训练其他模型。 R1 上线 API,对用户开放思维链输出 R1 在数学、代码、自然语言推理等任务上,性能比肩 OpenAI o1 正式版,小模型则超越 OpenAI o1-mini
Cusor,一个AI编码器,如果仅仅是一个编码器,在chatGPT,百度,阿里,腾讯,字节等众多同类AI编辑器中不是最早的AI编辑器,也不是最先AI赋能的插件或者程序,但是一个支持自然语言,更适合程序员体质的Cusor凭什么脱颖而出?

在机器学习和数据科学领域,余弦相似度长期以来一直是衡量高维对象之间语义相似度的首选指标。余弦相似度已广泛应用于从推荐系统到自然语言处理的各种应用中。它的流行源于人们相信它捕获了嵌入向量之间的方向对齐,提供了比简单点积更有意义的相似性度量。

2023年6月,理想汽车推出了自研认知大模型“Mind GPT”,它以“理想同学”App的形式出现在理想汽车的车机中,支持通过自然语言交流、发送指令。2024年,Mind GPT升级到3.0,带来了行业领先的自然语言任务执行功能。

2023年6月,理想汽车推出了自研认知大模型“Mind GPT”,它以“理想同学”App的形式出现在理想汽车的车机中,支持通过自然语言交流、发送指令。2024年,Mind GPT升级到3.0,带来了行业领先的自然语言任务执行功能。

大语言模型(LLM)在自然语言处理领域取得了令人瞩目的成就,但在需要多步推理的复杂任务中仍面临严峻挑战。

大语言模型(LLM)在自然语言处理领域取得了巨大突破,但在复杂推理任务上仍面临着显著挑战。现有的Chain-of-Thought(CoT)和Tree-of-Thought(ToT)等方法虽然通过分解问题或结构化提示来增强推理能力,但它们通常只进行单次推理过程,无法修正错误的推理路径,这严重限制了推理的准确性。
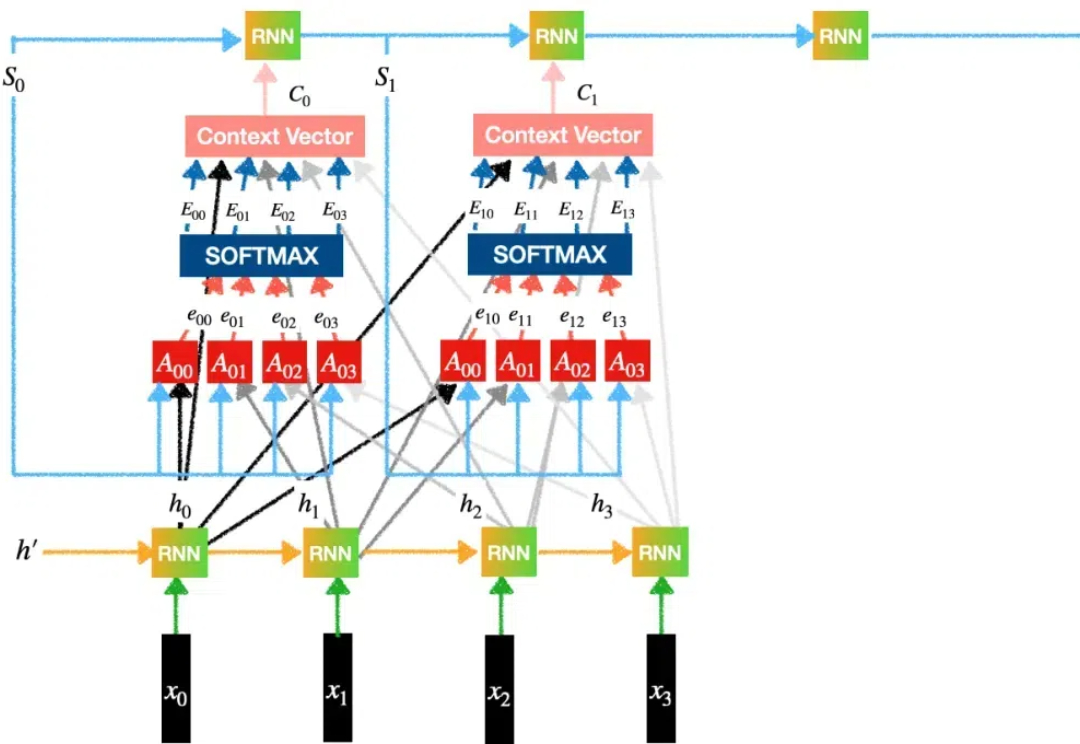
Transformer模型自2017年问世以来,已成为AI领域的核心技术,尤其在自然语言处理中占据主导地位。然而,关于其核心机制“注意力”的起源,学界存在争议,一些学者如Jürgen Schmidhuber主张自己更早提出了相关概念。