
CVPR 2025 | Qwen让AI「看见」三维世界,SeeGround实现零样本开放词汇3D视觉定位
CVPR 2025 | Qwen让AI「看见」三维世界,SeeGround实现零样本开放词汇3D视觉定位3D 视觉定位(3D Visual Grounding, 3DVG)是智能体理解和交互三维世界的重要任务,旨在让 AI 根据自然语言描述在 3D 场景中找到指定物体。
来自主题: AI技术研报
8699 点击 2025-03-24 15:47
 搜索
搜索
3D 视觉定位(3D Visual Grounding, 3DVG)是智能体理解和交互三维世界的重要任务,旨在让 AI 根据自然语言描述在 3D 场景中找到指定物体。
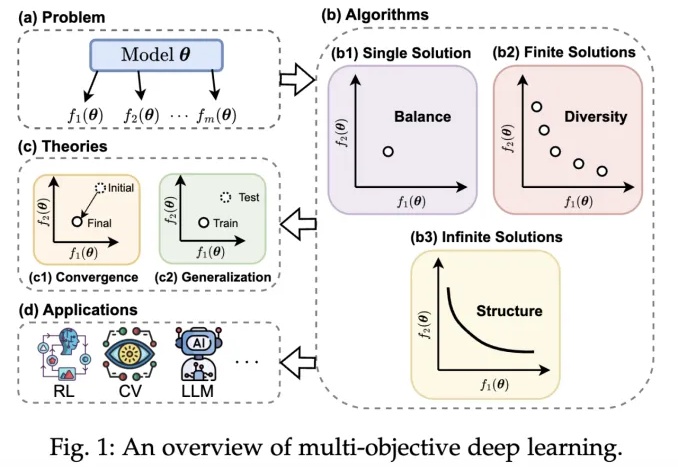
近年来,深度学习技术在自动驾驶、计算机视觉、自然语言处理和强化学习等领域取得了突破性进展。然而,在现实场景中,传统单目标优化范式在应对多任务协同优化、资源约束以及安全性 - 公平性权衡等复杂需求时,逐渐暴露出其方法论的局限性。
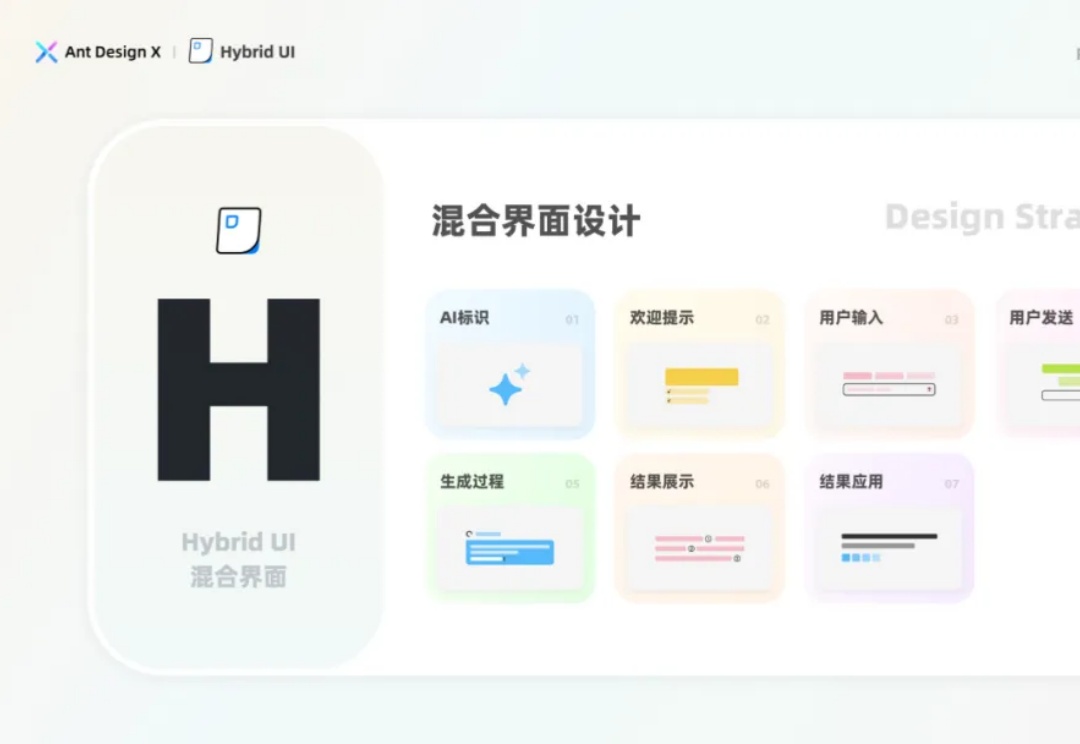
在 AI 时代,图形界面融合了自然语言会话等多通道交互,演变出新的形态。当意图、角色、会话这一切无形的体验规则被确定之后,它们最终也将承载于具体的界面之上。无形的体验融入到有形的体验之中,在这一部分里,我们提出的 Hybrid UI 正是要定义界面这一有形的体验,保障好 AI 产品体验的最后一道门槛。
2021 年年初,我在一个学长的数据公司做投放。这家公司主要是给大厂提供人脸识别标注数据、街道场景标注数据和自然语言标注数据。其中前两个是非常成熟,大厂需求也最多,而自然语言数据需求量几乎说少得可怜。
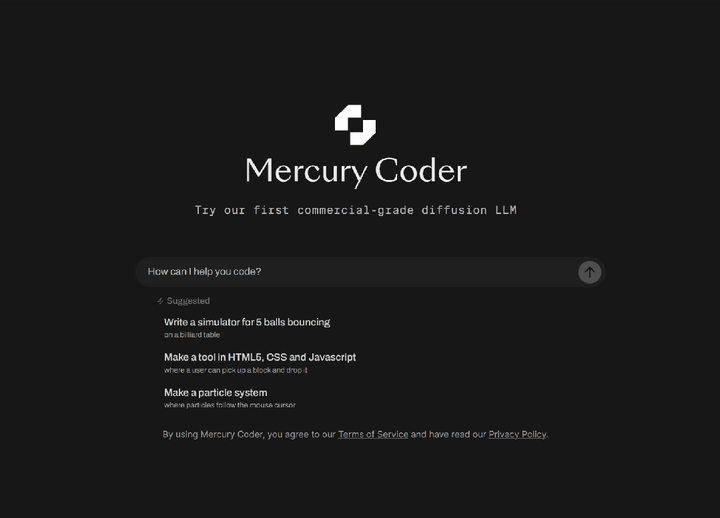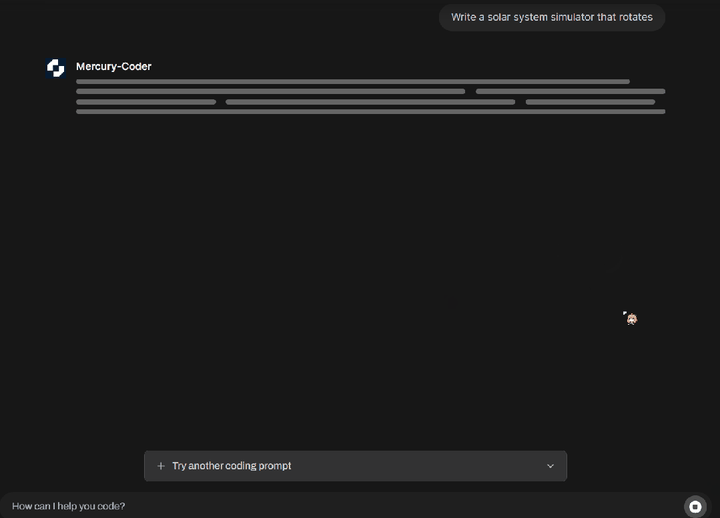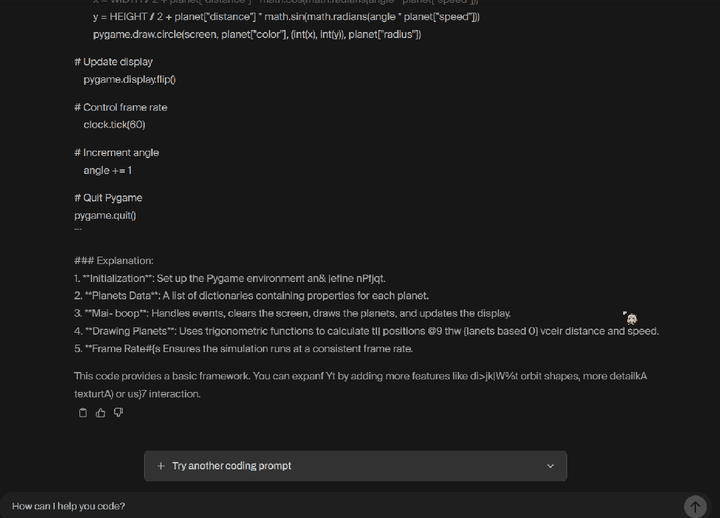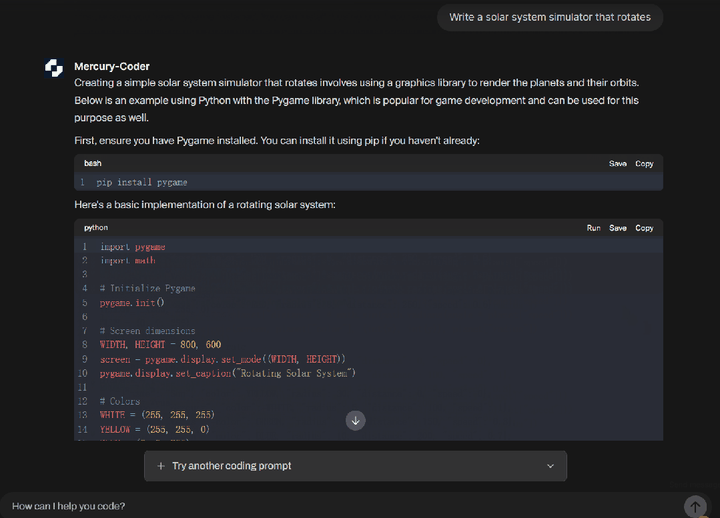
2025年2月27日,由前扩散模型领域顶尖研究者创立的Inception Labs正式发布了全球首个商业级扩散大语言模型(dLLM)——“Mercury”。这一里程碑式产品不仅在生成速度、硬件效率和成本控制上实现突破,更标志着自然语言处理技术从自回归(Autoregressive)范式向扩散(Diffusion)范式的重大跃迁。

大语言模型(LLMs)在当今的自然语言处理领域扮演着越来越重要的角色,但其安全性问题也引发了广泛关注。
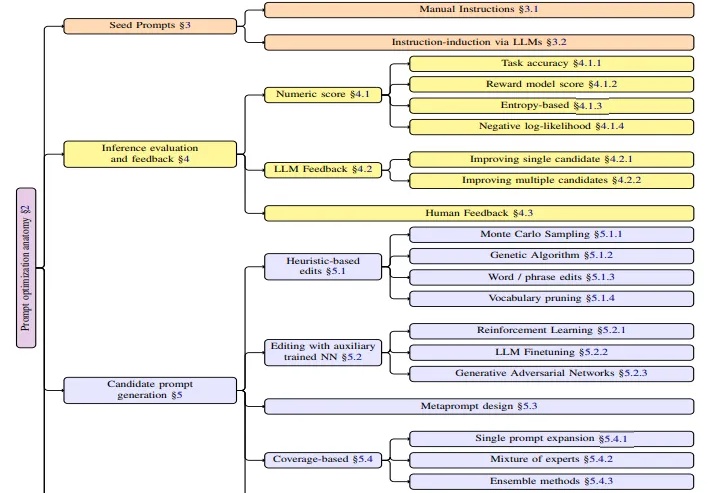
本文是对亚马逊AWS研究团队最新发表的APO(自动提示词优化)技术综述的深度解读。该研究由Kiran Ramnath、Kang Zhou等21位来自AWS的资深研究者共同完成,团队成员来自不同技术背景,涵盖了机器学习、自然语言处理、系统优化等多个专业领域。
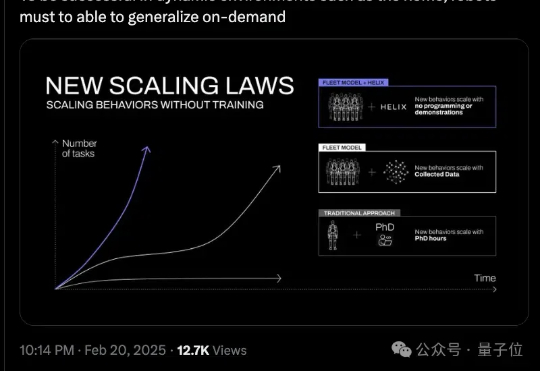
与OpenAI断交之后,Figure首个成果出炉:Helix,一个端到端通用控制模型,它能让机器人像人一样感知、理解和行动。只需自然语言提示,机器人就能拿起任何东西,哪怕是从没见过的东西,比如这个活泼的小仙人掌。
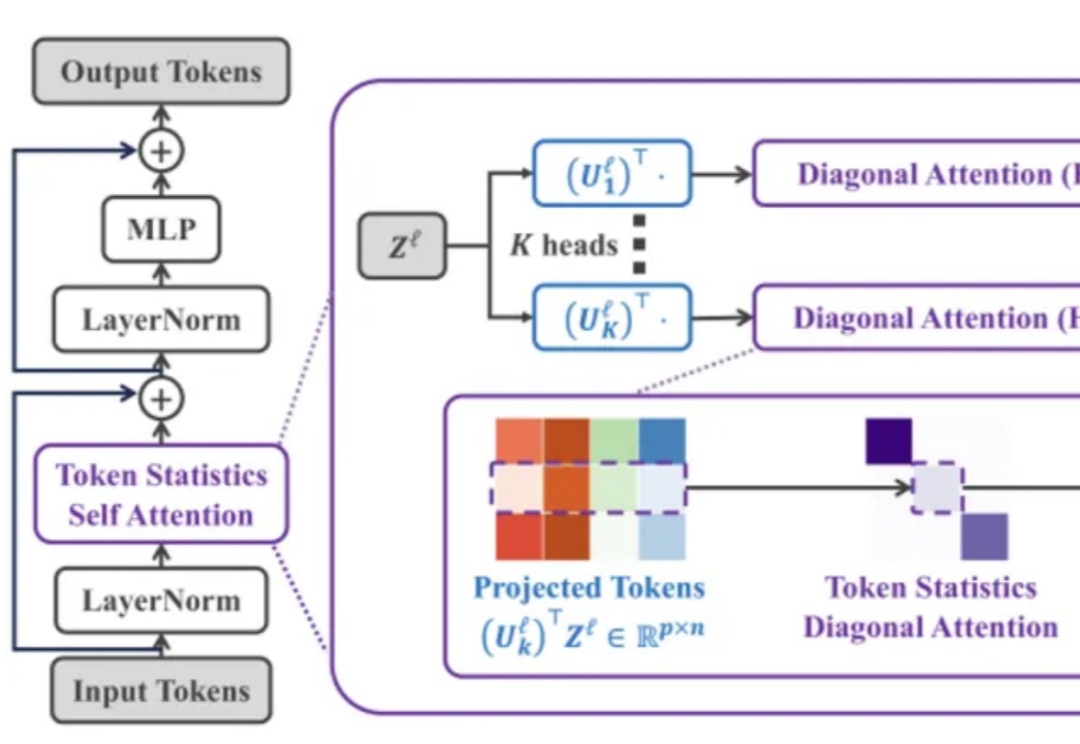
Transformer 架构在过去几年中通过注意力机制在多个领域(如计算机视觉、自然语言处理和长序列任务)中取得了非凡的成就。然而,其核心组件「自注意力机制」 的计算复杂度随输入 token 数量呈二次方增长,导致资源消耗巨大,难以扩展到更长的序列或更大的模型。

自然语言 token 代表的意思通常是表层的(例如 the 或 a 这样的功能性词汇),需要模型进行大量训练才能获得高级推理和对概念的理解能力,